A Deep Dive into Context-Aware AI Generation Techniques
RAG variants, Chain-of-Thought RAG (CoT-RAG), Graph Retrieval-Augmented Generation (GRAG) and Credibility-aware Generation (CAG) focuses on mitigating the impact of flawed information by enabling models to discern and process information based on its credibility.


Retrieval-Augmented Generation (RAG) has emerged as a fundamental paradigm for equipping Large Language Models (LLMs) with external knowledge, addressing inherent limitations such as hallucination and outdated information. This approach has proven critical for information retrieval and knowledge-intensive applications. However, the conventional RAG framework, characterized by a static retrieve-then-generate pipeline and input-level knowledge injection, often falls short in complex scenarios demanding multi-hop reasoning, adaptive information access, or deeper knowledge integration.
In response to these challenges, a new generation of advanced RAG variants has surfaced. Chain-of-Thought RAG (CoT-RAG) enhances reasoning and reliability by integrating structured knowledge graphs and programmatic logic with LLM generation. Graph Retrieval-Augmented Generation (GRAG) specifically addresses the limitations of traditional RAG in handling complex relational knowledge by leveraging graph databases. Concurrently, Credibility-aware Generation (CAG) focuses on mitigating the impact of flawed information by enabling models to discern and process information based on its credibility. While standard RAG provides a foundational mechanism for external knowledge access, these advanced techniques introduce sophisticated mechanisms for dynamic context awareness, structured reasoning, and enhanced reliability, thereby significantly expanding the capabilities of LLMs across diverse and demanding applications.
Retrieval-Augmented Generation (RAG)
Core Principles and Mechanisms of Standard RAG
Retrieval-Augmented Generation (RAG) stands as a pivotal paradigm designed to imbue Large Language Models (LLMs) with external knowledge, playing a crucial role in information retrieval and various knowledge-intensive applications. Its fundamental purpose is to overcome inherent limitations of LLMs, such as their propensity for generating inaccurate information (hallucinations), their lack of specialized domain knowledge, and the challenge of keeping their internal knowledge base current. By providing LLMs with access to external, verifiable information, RAG enhances the accuracy and relevance of their outputs.
The conventional RAG framework operates on a straightforward "retrieve-then-generate" principle. In this setup, an external retriever, or a more intricate retrieval system, first identifies and fetches documents relevant to a user's initial query. These retrieved documents are then concatenated and supplied as additional context to the LLM's input, which subsequently processes this augmented input to formulate a response. This approach represents a one-time retrieval strategy, where all information gathering occurs before the generation process commences.
The architecture of a standard RAG system comprises two primary components:
Retriever: This component is tasked with identifying and fetching pertinent information from a vast dataset or knowledge base in response to a user's query. The typical workflow involves segmenting large documents into smaller, manageable chunks. These chunks are then converted into high-dimensional numerical vector representations (embeddings). These embeddings are subsequently stored in a vector database, which is specifically optimized for efficient similarity searches, allowing for rapid identification of relevant content.
Generator: This is typically an LLM that receives both the original user prompt and the context retrieved by the retriever. The LLM then leverages this combined input to produce a coherent, factually grounded, and contextually appropriate response.
The operational flow of a standard RAG pipeline can be delineated into three main steps:
Indexing: External knowledge sources, such as documents or databases, are processed. This involves splitting them into discrete chunks, encoding these chunks into vector embeddings, and then storing them in a vector database. This structured storage facilitates quick and efficient lookups later.
Retrieval: When a user submits a query, the query itself is embedded into a vector. This query embedding is then used to search the vector database, identifying and retrieving the "top-k" most semantically similar chunks or documents. These are considered the most relevant pieces of information for the query.
Generation: The retrieved documents are combined with the original user query. This augmented prompt is then fed into the LLM, enabling it to generate a more informed and accurate final output, leveraging the external knowledge provided.
1.2 Advantages and Inherent Limitations of Conventional RAG
The adoption of Retrieval-Augmented Generation offers several compelling advantages for enhancing LLM capabilities:
Mitigation of Hallucination: A primary benefit of RAG is its capacity to anchor LLM responses in external, verifiable knowledge. This significantly reduces the incidence of factually incorrect or nonsensical outputs, a common challenge for LLMs that rely solely on their internal parametric memory.
Access to Up-to-Date and Domain-Specific Knowledge: RAG empowers LLMs to access current information and specialized domain knowledge that extends beyond their original training data cutoff. This negates the need for costly and frequent retraining of the entire model, allowing LLMs to remain relevant in rapidly evolving knowledge domains.
Enhanced Factual Accuracy and Relevance: By integrating retrieved evidence directly into the generation process, RAG substantially improves the factual accuracy, controllability, and overall relevance of the LLM's output, leading to more reliable and useful responses.
Cost-Effectiveness: Compared to the resource-intensive process of continuously fine-tuning or retraining large-scale LLMs to incorporate new or evolving information, RAG methods present a more economical and agile solution for knowledge integration.
Despite these advantages, conventional RAG systems possess inherent limitations that restrict their effectiveness in more complex scenarios:
Static Retrieve-Then-Generate Pipeline: The traditional RAG approach, which performs a single retrieval step based on the initial query, proves suboptimal for complex tasks requiring multi-hop reasoning, adaptive information access, or deeper knowledge integration. This static model operates under the assumption that all necessary information can be gathered comprehensively at the outset, which is often not the case for intricate queries.
Suboptimal Knowledge Injection: Standard RAG typically injects retrieved knowledge by simply appending documents to the input prompt, an approach known as in-context knowledge injection. While effective for basic grounding, this input-level method can be less efficient or effective for complex tasks that demand a more profound and integrated utilization of external knowledge.
"Lost in the Middle" Phenomenon and Context Window Issues: LLMs exhibit limitations in effectively processing excessively long input contexts, such as a large number of retrieved chunks (e.g., top-100). This is not merely an efficiency concern; empirical observations indicate that a shorter list of highly relevant contexts (e.g., 5-10) often yields higher generation accuracy. This highlights a crucial trade-off: while a smaller number of retrieved documents might compromise the recall of all relevant information, a larger number can introduce irrelevant or noisy content, potentially misleading the LLM and degrading the quality of the generated response. This challenge underscores that simply increasing the volume of information does not equate to improved performance; instead, the quality and pertinence of the retrieved context are paramount.
Limited Capacity of Retriever: Current RAG systems frequently employ sparse retrieval methods (e.g., BM25) or embedding models of moderate size. While these are efficient for very large corpora, their capacity to learn effective local alignments across the entire embedding space can be limited. This can reduce their effectiveness in ensuring a high recall of truly relevant content, particularly when dealing with novel tasks or domains.
Neglecting Relationships: A fundamental limitation of traditional RAG is its failure to capture significant structured relational knowledge. Textual content is often interconnected, but conventional RAG primarily relies on semantic similarity between isolated snippets, overlooking the complex relationships between entities that cannot be adequately represented through disjointed textual segments.
Redundant Information: When retrieved textual snippets are simply concatenated as prompts, traditional RAG can introduce redundancy and verbosity. This can potentially overwhelm the LLM with repetitive or less critical information, making it harder for the model to identify and focus on the most salient points.
Evolution: Dynamic and Parametric RAG Approaches
The limitations of static RAG have spurred the development of more sophisticated approaches, leading to the evolution of the RAG paradigm. This progression reflects a fundamental architectural shift from a rigid, batch-processing mindset to a real-time, adaptive intelligence paradigm in LLMs.
Dynamic Retrieval-Augmented Generation (Dynamic RAG):
Mechanism: This emerging paradigm directly addresses the constraints of static RAG by enabling multiple rounds of retrieval. Dynamic RAG adaptively determines when and what information to retrieve during the LLM's ongoing generation process, allowing for real-time adaptation to the model's evolving information requirements. The decision to initiate retrieval can be made autonomously by the LLM itself (e.g., by generating special tokens that signal a need for external knowledge) or by an external system that monitors the model's generation state for indicators of uncertainty or information gaps. Similarly, the queries for retrieval can be formulated directly by the LLM or through a dedicated external query-generation module.
Advantages: By iteratively incorporating newly retrieved external knowledge at relevant points throughout the generation process, Dynamic RAG empowers the model to produce more accurate, context-aware, and comprehensive responses. This significantly enhances performance on complex tasks that require multi-hop reasoning or the generation of long-form text, as the model can actively seek information as its internal thought process unfolds. An illustrative example is Self-Reflective RAG (Self-RAG), which employs "reflection tokens" as explicit signals to trigger on-the-fly retrieval, allowing the LLM to actively seek external information precisely when needed. This underlying trend implies that future RAG systems will increasingly integrate sophisticated feedback loops and agentic capabilities, empowering the LLM itself to play a more active and autonomous role in determining its information requirements, rather than passively consuming pre-selected contexts.
Parametric Retrieval-Augmented Generation (Parametric RAG):
Mechanism: Parametric RAG redefines how retrieved knowledge is integrated into LLMs. Moving beyond simply appending documents to the input prompt (input-level injection), this approach transitions to parameter-level knowledge injection. This means the external knowledge is infused directly into the model's parameters, allowing for a deeper and more intrinsic integration.
Advantages: This method facilitates a more profound assimilation of external knowledge, enabling the LLM to leverage retrieved information in a manner more akin to its own internal parametric knowledge. This can lead to enhanced efficiency and effectiveness in utilizing external data.
The RAG research landscape is continuously evolving, with methodologies broadly categorized into three main stages:
Naive RAG: Represents the conventional, static retrieve-then-generate approach discussed earlier.
Advanced RAG: Builds upon Naive RAG by introducing specific improvements, primarily focusing on enhancing retrieval quality through pre-retrieval and post-retrieval strategies to overcome its limitations.
Modular RAG: Introduces multiple specific functional modules that can be replaced or rearranged. This framework supports processes that are not limited to sequential retrieval and generation but can include iterative and adaptive retrieval processes, offering greater flexibility and sophistication.
This progression from static to dynamic and modular RAG architectures highlights a significant development: RAG serves as a crucial architectural component for building truly adaptive and evergreen AI systems. A significant limitation of traditional LLMs is their "knowledge cutoff," meaning their parametric knowledge is static and can quickly become outdated. RAG's core ability to "pull in fresh and relevant context from external sources" and provide "access to up-to-date information" fundamentally transforms LLMs from static knowledge repositories into dynamic, adaptable systems. This capability extends beyond merely reducing hallucinations; it enables a form of pseudo-continual learning without the prohibitive costs and complexities of full model retraining. This is particularly vital for applications in rapidly evolving domains such as real-time news analysis, cutting-edge scientific research, or dynamic legal frameworks, where information freshness is paramount. The focus shifts from retrieving more information to retrieving smarter and more pertinent information.
Chain-of-Thought RAG (CoT-RAG)
Integration of Chain-of-Thought (CoT) and RAG: Principles and Mechanisms
To address the growing demand for more sophisticated LLM capabilities, particularly in complex problem-solving, the integration of Chain-of-Thought (CoT) prompting with Retrieval-Augmented Generation (RAG) has emerged as a powerful advancement.
Chain-of-Thought (CoT) Prompting Background: Chain-of-Thought (CoT) prompting is a technique that significantly improves the ability of Large Language Models (LLMs) to perform complex reasoning tasks. It achieves this by inducing the LLM to break down a problem into a series of intermediate reasoning steps before arriving at a final answer, thereby mimicking a human's train of thought. CoT can be implemented in a few-shot manner, where a few examples with detailed reasoning steps are provided as exemplars. Alternatively, it can function as a zero-shot technique by simply appending a phrase like "Let's think step by step" to the prompt, a method proven surprisingly effective. CoT techniques were specifically developed to help LLMs handle multi-step reasoning tasks, demonstrating improved performance on arithmetic, commonsense, and symbolic reasoning questions.
Limitations of Traditional CoT: Despite its benefits, traditional CoT faces notable limitations. Its primary reliance on LLM-generated reasoning chains can lead to issues such as logical errors, factual inaccuracies, and interference from the inherent ambiguity of natural language reasoning steps. The effectiveness of in-context learning (ICL), often leveraged by CoT, is highly dependent on the quality of prompting examples. Noisy rationales, which include irrelevant or inaccurate reasoning thoughts, can significantly degrade performance. Furthermore, current LLMs often lack the intrinsic denoising ability to effectively discern and remove these noisy thoughts without external supervision.
CoT-RAG: A Hybrid Approach: CoT-RAG is a novel reasoning framework designed to integrate Chain-of-Thought reasoning with Retrieval-Augmented Generation, specifically to overcome the limitations of traditional CoT and enhance reasoning in LLMs. This framework specifically combines structured knowledge graphs with retrieval-augmented generation to mitigate the unreliability often associated with purely LLM-generated reasoning.
CoT-RAG employs a sophisticated three-stage approach in its design:
Knowledge Graph-driven CoT Generation: This design leverages knowledge graphs to modulate and enhance the credibility of reasoning chain generation by LLMs. The process initiates with a decision tree (DT) constructed by domain experts, which provides a foundational, interpretable representation of the core reasoning logic. To address the resource-intensive nature of manual DT creation, CoT-RAG utilizes LLMs to decompose "coarse-grained" nodes from the expert-provided DT into a more "fine-grained" knowledge graph. Each entity (node) in this decomposed knowledge graph is enriched with four specific attributes: a simplified
Sub-question derived from the original query, concise Sub-case contextual information, Sub-description (text extracted from user inputs or answers from other entities), and the Answer (the LLM's output for the Sub-question).
Learnable Knowledge Case-aware RAG: This component incorporates a retrieval mechanism that diverges from traditional vector-based approaches. CoT-RAG employs LLM-based retrieval to process lengthy user query descriptions. When a user submits a query (e.g., "Roger carrying lunch trays"), the LLM extracts specific details (e.g., "Roger can only carry 4 trays at a time") and dynamically assigns them to the relevant "Sub-description" fields within the knowledge graph. This dynamic assignment allows the framework to update the "Knowledge case" within the decision tree based on new user inputs, making the knowledge graph more comprehensive and adaptable over time.
Pseudo-Program Prompting Execution (PsePrompting): This innovative approach transforms the reasoning chain, as represented by the knowledge graph, into pseudo-programs. The objective is to achieve a balance between the general applicability of natural language and the logical precision inherent in programming. Key characteristics of PsePrompting include a simple logical structure for ease of understanding, general applicability across various question types, no reliance on external interpreters, and extensibility to different programming languages (e.g., C++, Java).
This architectural design signifies a crucial development in LLM capabilities: a shift from reasoning by the LLM to reasoning guided by structured knowledge. Traditional CoT primarily relies on the LLM's intrinsic ability to generate intermediate reasoning steps. However, this approach is inherently prone to unreliability and factual errors when the LLM's internal knowledge or reasoning capabilities are insufficient. CoT-RAG fundamentally addresses this by introducing "Knowledge Graph-driven CoT Generation" and "Pseudo-Program Prompting Execution". This means that instead of merely eliciting reasoning from the LLM, CoT-RAG structures and guides that reasoning with external, verifiable knowledge representations (knowledge graphs) and programmatic logic. The LLM's role evolves from an autonomous reasoner to an executor and decomposer within a pre-defined, expert-informed logical framework. This external grounding enhances both the credibility and the interpretability of the reasoning process.
Advantages in Complex Reasoning and Factual Grounding
CoT-RAG offers substantial advantages in handling complex reasoning tasks and ensuring factual accuracy:
Enhanced Reasoning Reliability: By combining structured knowledge graphs with retrieval and pseudo-program prompting, CoT-RAG significantly improves the reliability and logical consistency of LLM reasoning. This directly addresses the inherent unreliability and ambiguity of purely LLM-generated chains, providing a more robust framework for complex problem-solving.
Reduced Hallucinations and Factual Errors: The integration of the RAG component is crucial for grounding the LLM's responses in relevant external information. This effectively mitigates hallucination issues and factual inaccuracies that are common in traditional CoT methods, which rely solely on the LLM's internal parametric knowledge.
Significant Accuracy Improvements: Experimental evaluations conducted on nine public datasets, encompassing arithmetic, commonsense, and symbolic reasoning tasks, demonstrate substantial accuracy gains for CoT-RAG. Its performance ranges from 4.0% to 44.3% higher than state-of-the-art methods and traditional CoT variants (including CoT, Zero-shot-CoT, Auto-CoT, PS, and QDMRPS).
Superior Performance on Complex Problems: CoT-RAG consistently demonstrates superior performance as problem complexity increases, with the performance gap widening for more intricate multi-step reasoning problems. For example, it outperforms standard CoT by 3.4% and Zero-shot-CoT by 15.3% on GSM8K problems involving eight or more entities, indicating its effectiveness in handling highly challenging scenarios.
Robustness Across Implementations: The framework exhibits strong robustness, with minimal accuracy variations (errors below 4%) observed when testing variants that utilize different programming languages (e.g., C++, Java) or incorporate different knowledge cases. This underscores its adaptability and stability across diverse operational environments and implementation choices.
Scalability and Efficiency: CoT-RAG demonstrates superior performance in domain-specific tasks, such as legal, financial, and logical reasoning. This includes notable increases in accuracy, reduced runtime, and decreased token consumption compared to other RAG approaches. Specifically, it achieved a 19.0% increase in accuracy, a 29.2% reduction in runtime, and a 33.4% decrease in token consumption compared to vector-based retrieval approaches and GraphRAG, showcasing its strong practical applicability and scalability.
The following table provides a quantitative comparison of CoT-RAG's performance against various baseline CoT methods across a range of reasoning benchmarks. This empirical evidence underscores the significant impact of CoT-RAG's architectural innovations on accuracy and efficiency.
Key Limitations and Dependencies
Despite its impressive performance, CoT-RAG is subject to certain limitations and dependencies:
Reliance on Advanced LLMs: A significant constraint of CoT-RAG is its requirement for LLMs that possess advanced program understanding and execution capabilities. This often necessitates the use of proprietary models, as many publicly available LLMs may not yet have the requisite sophistication for these specific functionalities, limiting broader accessibility and deployment.
Dependency on Expert Knowledge for Decision Trees: The quality and effectiveness of the initial decision trees, which form the foundational reasoning logic for CoT-RAG, are directly contingent on the domain-specific knowledge and expertise of the human experts who construct them. This introduces potential variability in performance and can pose a scalability bottleneck in practical deployments, as manual expert input is a non-trivial resource.
Challenges with Noisy Rationales: While CoT-RAG aims to address the issue of noisy rationales, the underlying problem of irrelevant or inaccurate reasoning thoughts in CoT prompting remains complex. Research indicates that LLMs cannot achieve effective denoising solely with their intrinsic abilities, implying a continuous need for external supervision or sophisticated architectural designs to mitigate this challenge effectively.
Typical Application Scenarios
CoT-RAG is particularly valuable in real-world applications where reasoning reliability, factual accuracy, and interpretability of the reasoning path are paramount:
Complex Reasoning Tasks: CoT-RAG demonstrates high effectiveness across a spectrum of tasks demanding multi-step reasoning. These include arithmetic reasoning (e.g., AQUA, GSM8K, MultiArith, SingleEq), commonsense reasoning (e.g., HotpotQA, CSQA, SIQA), and symbolic reasoning (e.g., Last Letter Concatenation, Coin Flip).
Knowledge-Intensive Domains Requiring High Reliability: Its structured approach makes it exceptionally well-suited for fields where precision and verifiable reasoning are critical:
Legal Domains: For tasks that necessitate precise logical reasoning and accurate information retrieval and synthesis from complex legal texts and precedents, CoT-RAG can provide reliable insights.
Financial Domains: It is applicable for complex financial analysis, risk assessment, and informed decision-making processes, where precision and verifiable reasoning are crucial for managing significant economic implications.
Medical Domains: In areas such as diagnostic support, treatment planning, and understanding intricate medical cases, the accuracy and interpretability of AI-generated insights are critical for patient outcomes, making CoT-RAG a valuable tool.
Research Ideation: CoT-RAG can function as a topic-guided ideation agent. By integrating RAG chains with relevant, recent, and personalized information from academic literature, it can generate and refine research abstracts, aiding researchers in their exploratory phases.
The design principles of CoT-RAG, particularly its emphasis on explicit knowledge graphs and pseudo-programs, offer a promising avenue for developing more explainable and auditable AI reasoning systems. A significant challenge in AI adoption is the lack of transparency in how complex decisions are made. The reliance on expert-built decision trees and their subsequent decomposition into knowledge graphs in CoT-RAG inherently provides a more transparent and interpretable reasoning path compared to the opaque internal processes of a standalone LLM. Furthermore, the "pseudo-program prompting" lends itself to clearer, step-by-step execution that can be more easily traced and understood. This structured and explicit approach directly addresses the "lack of reliability" and "ambiguity" limitations of traditional CoT by making the reasoning process more accountable. This is a critical factor for the broader adoption of AI in regulated industries such as law, finance, and medicine, where not just the answer, but how the answer was derived, is paramount. This moves beyond mere factual grounding to a deeper reasoning grounding.
Graph Retrieval-Augmented Generation (GRAG): Leveraging Structured Knowledge
Core Principles and Mechanisms: Graph-Based Indexing, Graph-Guided Retrieval, and Graph-Enhanced Generation
Traditional Retrieval-Augmented Generation (RAG) systems primarily rely on flat data structures and semantic similarity for information retrieval. This approach significantly limits their ability to capture the complex, interconnected relationships among different entities found in many real-world databases. Consequently, conventional RAG often fails to leverage crucial structured relational knowledge and can lead to redundant information when retrieved textual snippets are simply concatenated as prompts.
Graph Retrieval-Augmented Generation (GraphRAG or GRAG) emerges as an innovative solution specifically engineered to overcome these limitations. Its core idea involves leveraging structural information embedded within knowledge graphs to enable more precise and comprehensive retrieval. This allows GRAG to effectively capture relational knowledge and facilitate more accurate, context-aware responses. Unlike traditional RAG, GRAG explicitly considers the interconnections between texts and entities, providing a richer contextual understanding.
The overall workflow of GraphRAG is typically decomposed into three interconnected stages:
Graph-Based Indexing (G-Indexing):
Principle: This initial phase involves identifying or constructing a graph database that aligns with specific downstream tasks and establishing efficient indices on it. Such graph databases can be sourced from large public knowledge graphs (e.g., Wikidata, Freebase, DBpedia, YAGO, ConceptNet, ATOMIC) or meticulously constructed from proprietary data sources like textual documents, tables, or other structured databases.
Mechanism: The indexing process encompasses mapping node and edge properties, establishing pointers between connected nodes, and organizing data for rapid traversal and retrieval. Common indexing methods include graph indexing (which preserves the entire graph structure), text indexing (converting graph data into textual descriptions), vector indexing (transforming graph data into vector representations), and hybrid indexing (combining these various methods). This stage is crucial for determining the granularity of subsequent retrieval operations and optimizing overall query efficiency.
Graph-Guided Retrieval (G-Retrieval):
Principle: Following the G-Indexing phase, this stage focuses on extracting pertinent information from the graph database in response to user queries. The primary objective is to retrieve the most relevant graph elements, which may include individual nodes, triplets (subject-predicate-object relationships), paths, or even entire subgraphs, depending on the complexity of the query.
Mechanism: This process involves measuring the semantic similarity between user queries and the structured graph data. Retrievers can be categorized based on their underlying mechanisms: non-parametric (relying on heuristic rules or traditional graph search algorithms), LM-based (leveraging the natural language understanding capabilities of language models to interpret queries and graph data), or GNN-based (encoding graph data and scoring retrieval granularities based on query similarity). Retrieval paradigms can vary, including once retrieval (a single operation), iterative retrieval (multiple steps based on prior results, allowing for dynamic refinement), and multi-stage retrieval (a linear division into stages, each potentially employing different retrievers). The retrieval granularity refers to the specific form of retrieved knowledge, such as individual nodes, triplets, paths, subgraphs, or hybrid combinations thereof. A specific GRAG variant, Graph Chain-of-Thought (Graph-CoT), exemplifies this by iteratively reasoning through the graph, dynamically expanding queries and adapting retrieval based on evolving information needs, thereby selecting only the most relevant information at each step rather than entire subgraphs.
Graph-Enhanced Generation (G-Generation):
Principle: This final phase involves synthesizing meaningful outputs or responses based on the retrieved graph data. The output can range from direct answers to user queries to the generation of comprehensive reports or summaries.
Mechanism: In this stage, a generator takes the user query, the retrieved graph elements, and an optional prompt as input to produce the final response. The choice of generator depends heavily on the specific downstream task:
GNNs (Graph Neural Networks): These are particularly effective for discriminative tasks, such as multi-choice question answering, due to their powerful representational capabilities for graph data. GNNs directly encode graph data, capturing complex relationships and node features, which are then processed through a Multi-Layer Perceptron (MLP) to generate predictive outcomes.
LMs (Language Models): LMs are proficient in text understanding and can serve as generators. However, due to the non-Euclidean nature of graph data, it must be converted into formats compatible with LMs. Once formatted, the graph data is combined with the query and fed into the LM. Both encoder-only models (like BERT, RoBERTa) are used for discriminative tasks, encoding input text and mapping it to the answer space via MLPs. Encoder-decoder and decoder-only models (like T5, GPT-4, LLaMA) are suitable for both discriminative and generative tasks, excelling in text understanding, generation, and reasoning.
Hybrid Models: These models integrate GNNs and LMs to leverage the strengths of both in representing graph structure and understanding text. This integration can follow a cascaded paradigm, where the output from a GNN (processing graph data) serves as input for an LM, which then generates the final text-based response. Prompt tuning is a typical approach here, where GNNs encode retrieved graph data, and this encoding is prepended as a prefix to the LM's input text embeddings. Alternatively, a parallel paradigm allows both GNNs and LMs to receive initial inputs simultaneously, processing different facets of the data in tandem, with their outputs merged to produce a unified response.
Graph Formats: When LMs are used as generators, graph data needs to be converted into a compatible format. This can involve:
Graph Languages: Formalized systems for characterizing and representing graph data, providing a uniform syntax and semantic framework. Examples include Adjacency/Edge Tables, Natural Language descriptions (using predefined templates or generating summaries), Code-Like Forms (e.g., GML, GraphML), Syntax Trees, and Node Sequences. Effective graph languages should be complete (capturing all essential information), concise (avoiding lengthy contexts), and comprehensible (easily understood by LLMs).
Graph Embeddings: Using GNNs to represent graphs as embeddings, which can be integrated with textual representations into a unified semantic space, often through prompt tuning. This avoids long text inputs but faces challenges in preserving precise information and generalization.
Generation Enhancement: Techniques are employed to further improve the quality of output responses. These include pre-generation enhancements (improving input data or representations), mid-generation enhancements (adjusting strategies during generation, like constrained decoding), and post-generation enhancements (integrating multiple generated responses).
Advantages in Handling Relational Knowledge and Complex Queries
GraphRAG offers significant advantages, particularly in scenarios demanding a deeper understanding of interconnected information:
Mitigates Hallucination: By referencing an external knowledge base, GraphRAG, like conventional RAG, refines LLM outputs, effectively reducing issues such as "hallucination," lack of domain-specific knowledge, and outdated information.
Captures Relational Knowledge: A key differentiator is GraphRAG's ability to leverage structural information across entities. This enables more precise and comprehensive retrieval, capturing relational knowledge that is often missed by traditional RAG methods that rely solely on semantic similarity of isolated text snippets. This leads to more accurate and context-aware responses.
Addresses Complex Relationships: Unlike traditional RAG, GraphRAG explicitly considers the interconnections between texts and entities. This enables a more accurate and comprehensive retrieval of relational information, which is crucial for answering complex queries that require understanding relationships beyond simple keyword matching.
Reduces Redundancy and Length: Graph data, such as knowledge graphs, inherently offer abstraction and summarization of textual data. By retrieving structured graph elements instead of raw text snippets, GraphRAG can significantly shorten the length of the input context provided to the LLM, mitigating concerns of verbosity and the "lost in the middle" dilemma where LLMs struggle with long inputs.
Grasps Global Information: By retrieving subgraphs or graph communities, GraphRAG can access comprehensive information that captures broader context and interconnections within the graph structure. This capability is particularly effective for addressing challenges like Query-Focused Summarization (QFS), where a holistic understanding of related entities and their relationships is required.
Key Limitations and Challenges
Despite its advancements, GraphRAG faces several limitations and challenges:
Dynamic and Adaptive Graphs: Most current GraphRAG methods are built upon static graph databases. However, real-world knowledge is constantly evolving with new entities and relationships emerging. Rapidly updating these dynamic changes in a graph database presents a significant challenge.
Multi-Modality Information Integration: The majority of knowledge graphs are primarily textual, lacking other modalities such as images, audio, and videos. Integrating such diverse data types could enrich the database significantly, but it introduces considerable challenges due to the exponential growth in complexity and size.
Scalable and Efficient Retrieval Mechanisms: Industrial-scale knowledge graphs can contain millions or even billions of entities. Most current GraphRAG methods are tailored for smaller-scale graphs, making efficient retrieval of pertinent entities in such massive graphs a substantial practical challenge.
Lossless Compression of Retrieved Context: When retrieved graph information is transformed into a sequence for LLMs, it can still result in very long contexts. LLMs struggle with processing excessively long sequences, and extensive computation during inference can be a hindrance. Designing lossless compression techniques is challenging, as current works often involve a trade-off between compression efficiency and information preservation.
Standard Benchmarks: GraphRAG is a relatively nascent field that currently lacks unified and standard benchmarks for evaluating different methods. This absence hinders consistent comparison and objective progress across various research efforts.
Integration of GNNs and LMs (Hybrid Models): Effectively integrating information from these two distinct modalities (graph structures and natural language text) remains a significant technical challenge in hybrid GraphRAG models.
Graph Embeddings Limitations: While graph embedding methods offer the advantage of avoiding long text inputs, they face challenges such as difficulty in preserving precise information (e.g., specific entity names) and exhibiting poor generalization capabilities to new or unseen graph structures.
Typical Application Scenarios
GraphRAG is widely applicable across various downstream tasks, particularly in Natural Language Processing (NLP), and in diverse application domains:
Downstream Tasks:
Question Answering (QA):
Knowledge Base Question Answering (KBQA): Addresses questions related to specific knowledge graphs, where answers involve entities, relationships, or operations within the graph structure.
Commonsense Question Answering (CSQA): Primarily involves multiple-choice questions that require the use of external commonsense knowledge graphs (e.g., ConceptNet) to find relevant knowledge and derive correct answers.
Information Retrieval (IR):
Entity Linking (EL): Focuses on identifying entities within text and linking them to corresponding entities in a knowledge graph.
Relation Extraction (RE): Aims to identify and classify semantic relationships between entities within a given text.
Other Tasks: Includes fact verification, link prediction, dialogue systems, and recommendation systems, all benefiting from the structured relational knowledge provided by graphs.
Application Domains:
E-Commerce: Improves customer shopping experiences and increases sales through personalized recommendations and intelligent customer services by leveraging historical user-product interactions structured as a graph.
Biomedical: Enhances medical decision-making in question answering systems by constructing or utilizing knowledge graphs related to diseases, symptoms, treatments, and medications, where complex relationships are critical.
Academic: Facilitates academic exploration, such as predicting collaborators or identifying research trends, by structuring papers, authors, institutions, and their relationships into a graph.
Literature: Enhances smart library applications by constructing knowledge graphs of books, authors, publishers, and series, enabling more sophisticated search and recommendation.
Legal: Aids lawyers and legal researchers in case analysis and legal consultation by structuring citation connections between cases, judicial opinions, and courts into a graph, providing a clear map of legal precedents.
Other Real-World Scenarios: Includes intelligence report generation, patent phrase similarity detection, and software understanding (e.g., chatbots for software dependencies), all benefiting from the ability to navigate and leverage interconnected data.
Credibility-aware Generation (CAG): Addressing Information Quality
Core Principles and Mechanisms
The rapid adoption of Retrieval-Augmented Generation (RAG) has been instrumental in alleviating knowledge bottlenecks and mitigating hallucinations in Large Language Models (LLMs). However, a significant vulnerability of the existing RAG paradigm is its susceptibility to flawed information introduced during the retrieval phase. This can inevitably diminish the reliability and correctness of the generated outcomes.
Credibility-aware Generation (CAG) is proposed as a universally applicable framework specifically designed to mitigate the impact of such flawed information in RAG systems. At its core, CAG aims to equip LLMs with the ability to discern and process information based on its credibility. This means the model does not merely retrieve and integrate information, but critically evaluates its trustworthiness before incorporating it into the generation process.
The primary mechanism by which CAG achieves this is through an innovative data transformation framework. This framework is designed to generate data that is specifically annotated with credibility information. By training models on this credibility-annotated data, the framework effectively endows them with the capability of credibility-aware generation. The process involves transforming existing Question Answering (QA) and dialogue datasets into a format that incorporates credibility, thereby guiding the model to generate responses based on this credibility assessment.
A key observation motivating CAG's design is that existing LLMs are not inherently sensitive to directly provided credibility information within the prompt. This deficiency limits their capacity to optimally employ credibility for discerning and processing information. Therefore, the data transformation framework is crucial for explicitly training the model to utilize credibility in addressing flawed information, rather than assuming an innate ability.
Advantages in Mitigating Flawed Information and Enhancing Robustness
CAG offers distinct advantages in improving the reliability and robustness of LLM-generated content, particularly in environments where information quality is variable:
Effective Understanding and Employment of Credibility for Generation: Experimental results consistently demonstrate that models trained with CAG can effectively understand and utilize credibility information during the generation process. This allows them to make informed decisions about which pieces of retrieved information to prioritize or discard based on their assessed trustworthiness.
Significant Outperformance of Other Models with Retrieval Augmentation: CAG models show superior performance compared to other Retrieval-Augmented Generation (RAG) models, especially when faced with the challenge of flawed input. This suggests that the explicit incorporation of credibility awareness provides a critical edge in maintaining output quality.
Robustness Despite Increasing Noise in the Context: A notable advantage of CAG is its resilience. The framework maintains its effectiveness and robust performance even when faced with increasing levels of flawed or noisy information within the input context. This is crucial for real-world applications where data quality cannot always be guaranteed. This framework's ability to discern and process information based on credibility allows it to exhibit resilience against the disruption caused by noisy documents.
Key Limitations and Challenges
The primary limitation of Credibility-aware Generation lies in the foundational challenge that existing Large Language Models are not inherently sensitive to directly provided credibility information within the prompt. This inherent deficiency restricts their capacity to optimally employ credibility for discerning and processing information without explicit training. Consequently, the efficacy of CAG heavily relies on the innovative data transformation framework that generates data specifically annotated with credibility, thereby training the model to utilize this crucial attribute. This dependence on external data engineering for credibility awareness highlights a challenge in achieving truly autonomous credibility assessment within LLMs.
Typical Application Scenarios
To rigorously assess the capabilities of credibility-aware generation in managing flawed information, a comprehensive benchmark has been developed, encompassing three critical real-world scenarios :
Open-domain Question Answering (QA): This scenario aims to accurately answer questions across a wide variety of topics without being limited to any particular area. It encompasses a broad spectrum of real-world applications that urgently require the integration of external knowledge to enhance the language model's ability to address diverse queries. In such settings, the ability to effectively identify and process noisy or unreliable information is paramount for maintaining factual accuracy.
Time-sensitive QA: This scenario focuses on providing answers that are both correct and up-to-date, utilizing the most recent information available. It poses a significant challenge for LLMs due to the rapidly changing nature of internet information. The inevitable inclusion of outdated documents when incorporating external sources further complicates matters. Even with timestamps provided for each document, LLMs might still erroneously prioritize outdated documents. This situation underscores the critical need for credibility assessment in time-sensitive QA scenarios to ensure the relevance and accuracy of responses.
Misinformation-polluted QA: This scenario aims to tackle the issue of ensuring accurate answers in an environment polluted with misinformation. The proliferation of fake news and misinformation, often exacerbated by the misuse of LLMs, presents a substantial challenge. Consequently, in this scenario, it is crucial to carefully consider the quality and credibility of any introduced external information to prevent the propagation of false narratives.
Comparative Analysis and Future Directions
Comparative Overview of RAG, CoT-RAG, GRAG, and CAG
The evolution of context-aware AI generation techniques, from foundational RAG to specialized variants like CoT-RAG, GRAG, and CAG, reflects a progressive effort to address the inherent limitations of LLMs and enhance their utility in complex, real-world applications. Each paradigm focuses on distinct aspects of context awareness and knowledge integration:
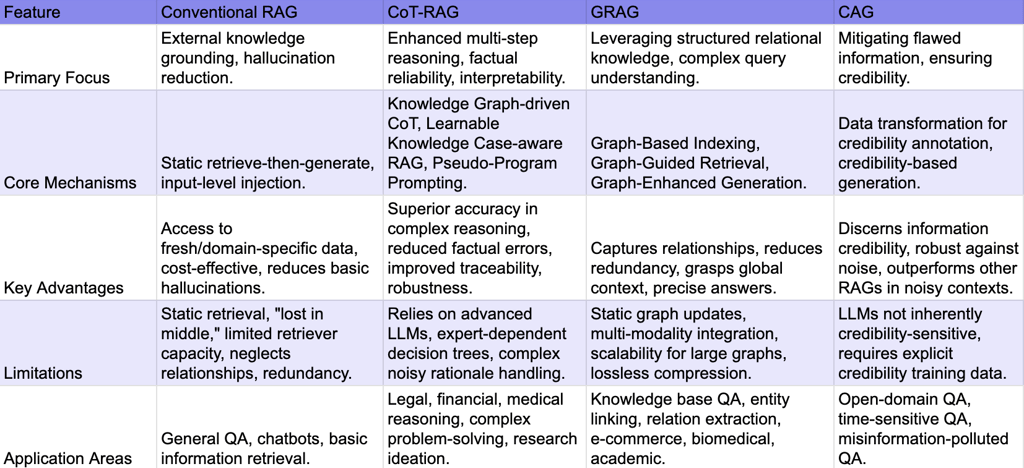
Conventional RAG provides the foundational capability, enabling LLMs to access external knowledge and mitigate basic hallucinations. Its simplicity and effectiveness for many applications have driven widespread adoption. However, its static nature and reliance on flat document structures limit its performance on intricate tasks.
CoT-RAG extends this by integrating structured reasoning paths. It moves beyond merely augmenting context to guiding the LLM's thought process with external knowledge graphs and programmatic logic. This addresses the unreliability of purely LLM-generated reasoning, providing a more robust and auditable framework for complex problem-solving. The emphasis shifts from simply providing information to structuring how that information is used in a logical progression.
GRAG tackles the inherent limitation of RAG in handling interconnected data. By leveraging knowledge graphs, GRAG can retrieve not just relevant documents, but specific entities, relationships, and subgraphs, allowing for a deeper understanding of relational knowledge. This is crucial for queries that require multi-hop reasoning or an understanding of complex interdependencies, areas where traditional RAG struggles with isolated textual snippets.
CAG addresses the critical issue of information quality. While RAG, CoT-RAG, and GRAG focus on what information is retrieved and how it's used, CAG introduces a layer of credibility assessment. This is vital in real-world scenarios where retrieved information might be outdated, biased, or outright false. CAG's mechanism of training LLMs to discern credibility helps ensure that the generated responses are not only factually grounded but also trustworthy.
Synergies and Hybrid Approaches
These advanced context-aware generation techniques are not mutually exclusive; rather, they represent complementary advancements that can be combined for enhanced performance. The limitations of one approach often highlight the strengths of another, suggesting fertile ground for hybrid architectures.
For instance, a system could integrate the structured reasoning of CoT-RAG with the relational knowledge capabilities of GRAG. This would allow for complex multi-hop reasoning (CoT-RAG's strength) to be performed over a rich, interconnected knowledge graph (GRAG's strength), leading to more accurate and comprehensive answers for highly intricate queries. Furthermore, incorporating CAG into such a hybrid system would add a crucial layer of trustworthiness, ensuring that both the retrieved graph data and the intermediate reasoning steps are evaluated for credibility. This would be particularly valuable in domains like legal or medical research, where both complex reasoning and verifiable, high-quality information are paramount.
The evolution towards Dynamic RAG, with its adaptive and iterative retrieval, provides a foundational framework for these more specialized methods. A Dynamic RAG system could, for example, employ a GRAG retriever when a query indicates a need for relational knowledge, or trigger a CoT-RAG reasoning chain when multi-step logical deduction is required. Simultaneously, a CAG component could continuously monitor the credibility of all retrieved and generated information, providing feedback to refine retrieval strategies or generation outputs.
The underlying trend in these developments is a move towards more intelligent, agentic LLM systems that can not only access external knowledge but also actively manage, reason over, and evaluate the quality of that knowledge.
Emerging Trends and Future Directions
The trajectory of context-aware AI generation points towards several key emerging trends and future directions:
Increased Autonomy and Agentic Capabilities: The shift from static to dynamic RAG, where LLMs play a more active role in determining their information needs, is a clear indicator of growing agentic capabilities. Future systems will likely feature LLMs that can autonomously plan retrieval strategies, formulate complex queries, and even self-correct based on the quality of retrieved information. This will move LLMs beyond passive generators to proactive problem-solvers.
Deeper Integration of Structured and Unstructured Knowledge: While GRAG makes strides in leveraging structured knowledge, the challenge of seamlessly integrating diverse data types (text, images, audio, video) into a unified knowledge representation remains. Future research will likely focus on more sophisticated multi-modal knowledge graphs and retrieval mechanisms that can process and reason over information from disparate sources in a cohesive manner.
Enhanced Explainability and Auditability: CoT-RAG's reliance on expert-built decision trees and pseudo-programs offers a blueprint for more transparent AI. The demand for explainable AI (XAI) will drive further innovation in making the internal reasoning processes of LLMs more interpretable and auditable, especially for high-stakes applications. This could involve developing standardized frameworks for representing reasoning paths and providing granular provenance for every piece of information used in generation.
Robustness to Noisy and Adversarial Information: CAG highlights the critical need for LLMs to handle flawed information. As AI systems become more pervasive, they will inevitably encounter biased, outdated, or maliciously crafted data. Future systems will need more sophisticated mechanisms for real-time credibility assessment, anomaly detection, and adversarial robustness, potentially incorporating external verification services or human-in-the-loop feedback loops.
Optimized Context Management: The "quantity vs. quality" trade-off in context retrieval remains a challenge. Future advancements will prioritize intelligent context compression, summarization, and dynamic re-ranking techniques to ensure that LLMs receive the most pertinent and concise information, optimizing both performance and computational efficiency. Approaches that can dynamically adjust the "k" (number of retrieved documents) based on query complexity and context quality will become standard.
Personalization and Adaptive Learning: As RAG bridges the gap to continual learning, future systems will increasingly adapt to individual user preferences, domain-specific nuances, and evolving real-time information. This will involve more sophisticated user profiling, adaptive indexing, and personalized retrieval strategies, making AI generation highly tailored and responsive.
Conclusion
The landscape of context-aware AI generation techniques is rapidly evolving, driven by the imperative to enhance the capabilities of Large Language Models beyond their inherent parametric knowledge. Retrieval-Augmented Generation (RAG) established the foundational principle of leveraging external knowledge to mitigate issues like hallucination and outdated information. However, the limitations of its static retrieve-then-generate pipeline and input-level knowledge injection quickly became apparent for more complex tasks.
The emergence of advanced paradigms such as Chain-of-Thought RAG (CoT-RAG), Graph Retrieval-Augmented Generation (GRAG), and Credibility-aware Generation (CAG) represents a significant leap forward. CoT-RAG addresses the challenge of unreliable LLM-generated reasoning by integrating structured knowledge graphs and programmatic logic, thereby enhancing reasoning reliability, factual grounding, and interpretability. GRAG specifically tackles the limitations of traditional RAG in processing complex relational knowledge, enabling more precise retrieval and understanding of interconnected data. Concurrently, CAG introduces a crucial dimension of information quality, equipping models with the ability to discern and process information based on its credibility, a vital capability in an era of abundant and often flawed data.
The progression from basic RAG to these specialized, context-aware variants underscores a fundamental shift in AI development: moving beyond mere information retrieval to sophisticated knowledge management, structured reasoning, and critical evaluation of information. These approaches are not isolated but offer significant synergistic potential, allowing for the construction of hybrid systems that combine their respective strengths. The ongoing development points towards increasingly autonomous, explainable, and robust AI systems capable of navigating and reasoning over vast, dynamic, and potentially noisy information landscapes. The future of AI generation lies in these sophisticated, context-aware frameworks that empower LLMs to not only generate human-like text but also to do so with greater accuracy, reliability, and understanding of the underlying knowledge.