Analysis of Speech-to-Text Technology, Market Dynamics, and Future Trajectories
This article provides a comprehensive strategic analysis of the Voice AI ecosystem, deconstructing its technological underpinnings, mapping the competitive landscape, examining its transformative impact across key sectors, and projecting its future trajectory.


The rapid proliferation of voice-activated technologies has embedded spoken language at the core of human-computer interaction. From ubiquitous virtual assistants to sophisticated enterprise analytics, Voice AI is no longer a futuristic concept but a foundational technology reshaping industries and consumer behavior. This report provides a comprehensive strategic analysis of the Voice AI ecosystem, deconstructing its technological underpinnings, mapping the competitive landscape, examining its transformative impact across key sectors, and projecting its future trajectory. At the heart of this revolution lies the ability to convert the spoken word into structured, machine-readable data—a process that initiates a complex value chain of interpretation, understanding, and action. This foundational part of the report establishes a precise lexicon for the Voice AI landscape, clarifying the distinct yet interconnected roles of its core components to provide a clear framework for the subsequent technical and market analysis.
From Spoken Word to Digital Text: The Fundamentals of Speech Recognition
The initial and most critical step in any voice-driven system is the conversion of analog sound waves into digital text. This process is enabled by a set of technologies that, while often used interchangeably, serve distinct functions in the voice ecosystem. A clear understanding of these fundamental concepts is essential to appreciating the architecture and capabilities of modern Voice AI.
Defining Speech-to-Text (STT) and Automatic Speech Recognition (ASR)
Speech-to-Text (STT), also commonly referred to as voice-to-text, is the core technology that converts spoken language into its written equivalent. It is primarily delivered as a software-based service that employs computational linguistics to facilitate the recognition and translation of spoken words into text. The technical engine that powers STT is known as Automatic Speech Recognition (ASR). ASR comprises the specific models and algorithms that allow computers to process human speech, enabling a natural, conversational mode of interaction.
In industry and academic literature, the terms STT and ASR are frequently used synonymously to describe this fundamental process of transcription. The primary objective of any ASR system is to answer the question:
what was said? It achieves this by producing an automated, verbatim transcript of spoken audio, which then serves as the foundational data input for a vast array of subsequent applications, from simple voice commands to complex data analytics.
Distinguishing Speech Recognition from Voice Recognition (Speaker Identification)
A critical distinction, and a common point of confusion, lies between speech recognition and voice recognition. While the two are related, they perform fundamentally different tasks. As established, speech recognition (ASR) identifies the content of the speech—the words themselves. In contrast, voice recognition, more accurately termed speaker identification or verification, focuses on identifying who is speaking.
Voice recognition technology analyzes the unique acoustic patterns of an individual's voice, such as pitch, cadence, and tone, to create a distinct vocal fingerprint. Its primary applications are in security and personalization. For example, voice biometrics can be used as a secure method for authenticating a user's identity to access a bank account or a secure system. In the consumer realm, it allows a virtual assistant like Amazon's Alexa to recognize different users in a household and provide personalized responses, calendars, or music playlists. In essence, ASR captures what is said, while voice recognition identifies who said it. Though often deployed in tandem within a single system, they are distinct technologies serving separate but complementary functions.
The Broader Concept of Voice AI: An Integrated System of Interaction
Voice AI is the comprehensive term for any artificial intelligence system designed to simulate and engage in human-like communication through speech. It represents an integrated technological stack that goes far beyond simple transcription. A complete Voice AI system not only listens to and transcribes spoken language via STT/ASR but also comprehends the user's commands or intent and then acts upon them accordingly.
The full architecture of a modern Voice AI system includes several key components working in concert:
Speech-to-Text (STT/ASR): Captures and converts the user's spoken input into text.
Natural Language Processing/Understanding (NLP/NLU): Analyzes the text to decipher its meaning, intent, and context.
Action/Dialogue Management: Determines the appropriate action or response based on the understood intent.
Text-to-Speech (TTS) / Speech Synthesis: Generates a natural-sounding, spoken response if required, completing the conversational loop.
The user's point of interaction with this complex system is the Voice User Interface (VUI), exemplified by assistants like Apple's Siri and Google Assistant. The VUI provides the hands-free, conversational experience that has made Voice AI a mainstream technology.
The structure of this technological stack reveals a clear value chain. STT/ASR forms the foundational layer, performing the essential but increasingly commoditized task of transforming unstructured audio data into structured text data. The real strategic and commercial value, however, is unlocked in the subsequent layers, particularly in the cognitive processing performed by Natural Language Understanding. While STT provides the "what," NLU provides the "so what," extracting actionable business intelligence such as customer intent, sentiment, and key entities from the raw text. This is precisely why high-value enterprise applications, such as contact center analytics, do not merely transcribe calls but analyze them to identify "customer pain points and sentiments" and "uncover existing service gaps". This higher-level analysis is a function of NLU. Consequently, competitive differentiation in the Voice AI market is increasingly shifting from the quality of transcription alone to the sophistication of the understanding and insights that can be derived from it. The most dominant market players will be those who can either provide a flawlessly accurate STT layer to ensure clean input or, perhaps more powerfully, a superior NLU layer capable of deriving robust insights even from the imperfect, noisy transcriptions characteristic of real-world environments.
The Brains of the Operation: Natural Language Processing and Understanding
If Speech-to-Text is the "ears" of a Voice AI system, then Natural Language Processing and its subfield, Natural Language Understanding, constitute the "brain." These technologies provide the cognitive capabilities that elevate a system from a simple dictation tool to an intelligent conversational partner, enabling it to comprehend meaning, infer intent, and respond appropriately.
The Foundational Role of Natural Language Processing (NLP)
Natural Language Processing (NLP) is a broad and multifaceted field of artificial intelligence dedicated to enabling computers to process, analyze, and generate human language, both in text and speech form. It serves as the core engine that allows machines to interpret the complexities of human communication. In the context of Voice AI, NLP is the bridge between the raw text output of an STT system and the machine's ability to perform a useful task.
Once speech is converted to text, NLP applies a series of techniques to structure and prepare the data for analysis. These include:
Tokenization: Breaking down sentences into individual words or "tokens."
Stemming and Lemmatization: Reducing words to their root forms to standardize them.
Part-of-Speech Tagging: Identifying nouns, verbs, adjectives, etc., to understand grammatical structure.
Parsing: Analyzing the grammatical structure of a sentence to understand the relationships between words.
This pre-processing is a critical step that transforms a simple string of characters into a structured format that a machine can comprehend. NLP is the essential technology that allows voice assistants like Siri and Alexa to understand the fundamental components of a user's request and act upon it.
The Critical Function of Natural Language Understanding (NLU)
Natural Language Understanding (NLU) is a specialized and more advanced subset of NLP. Its primary focus is not just on processing language but on truly comprehending its meaning, including the nuances of context, intent, and sentiment. While NLP might parse the grammar of a sentence, NLU aims to grasp what the user actually meant to convey. This distinction is crucial: NLP processes what was said, while NLU determines what was meant.
The core function of NLU is to interpret the user's underlying goal. It achieves this through two key processes:
Intent Recognition: This identifies the primary objective or purpose of the user's utterance. For example, in the phrase "What's the weather like in London tomorrow?", the intent is "get_weather_forecast".
Entity Recognition: This extracts the key pieces of information, or "entities," that are necessary to fulfill the intent. In the same example, the entities are "London" (location) and "tomorrow" (date).
By identifying both the intent and the relevant entities, NLU enables a system to respond accurately and intelligently. It can understand a request for assistance like, "I'm having trouble with my order," and correctly classify the intent as needing customer support, even though the word "help" was never explicitly used. This ability to infer meaning from conversational language is the hallmark of a sophisticated Voice AI system.
Synergy in Action: How STT, NLP, and NLU Create Intelligent Voice Experiences
The creation of a seamless and intelligent voice experience is the result of a tightly integrated, multi-stage pipeline where each component builds upon the last. The typical flow of a voice interaction is as follows:
Speech Capture and Transcription (STT/ASR): The user speaks a command or query. The device's microphone captures the audio, and an STT engine converts the sound waves into a raw text string. For example, the user says, "Alexa, turn on the kitchen light." The STT system outputs the text: "alexa turn on the kitchen light".
Language Processing (NLP): The raw text is then passed to the NLP layer, which cleans and structures it. This involves processes like tokenization (breaking the sentence into words: "alexa", "turn", "on", "the", "kitchen", "light") and parsing its grammatical structure.
Meaning Extraction (NLU): The structured text is analyzed by the NLU engine to determine its meaning. It identifies the intent ("turn_on_device") and the entities ("device": "light", "location": "kitchen"). The wake word "Alexa" is also recognized to activate the system.
Action Execution: Based on the extracted intent and entities, the system's logic determines the appropriate action. In this case, it sends a command to the smart home API to activate the light bulb designated as "kitchen light".
Response Generation (NLG/TTS) (Optional): For many interactions, the system provides a spoken confirmation. A Natural Language Generation (NLG) module formulates a human-like response, such as "Okay, turning on the kitchen light." This text is then fed to a Text-to-Speech (TTS) engine, which synthesizes the audio for the user to hear, completing the conversational exchange.
This entire, intricate process—from sound wave to intelligent action and back to sound wave—occurs in a fraction of a second, creating the illusion of a seamless conversation. It is this powerful synergy between transcription, processing, and understanding that underpins the entire modern Voice AI ecosystem, from consumer virtual assistants to the most advanced enterprise analytics platforms.
The Technological Evolution of Speech Recognition
The journey of Automatic Speech Recognition from a laboratory curiosity to a ubiquitous technology is a story of decades of research, punctuated by transformative breakthroughs in computing and algorithmic theory. The exponential increase in accuracy and capability witnessed in recent years is the culmination of a long evolutionary process. This part of the report provides a deep technical analysis of this evolution, tracing the major paradigm shifts from early rule-based systems to the sophisticated deep learning architectures that define the state of the art today.
A Historical Perspective: From "Audrey" to Deep Learning
Understanding the historical context of ASR is crucial for appreciating the scale and pace of recent advancements. The technology's development can be broadly categorized into three distinct eras, each defined by its dominant technological approach.
Pioneering Efforts (1950s-1980s): Rule-Based and Early Statistical Models
The origins of speech recognition can be traced back to the mid-20th century with early, highly constrained systems. The first recognizable ASR system was Bell Laboratories' "Audrey," developed in 1952. This groundbreaking device could recognize spoken digits from zero to nine, but only when spoken by its creator, and required the user to pause between each word. A decade later, in 1962, IBM demonstrated its "Shoebox" machine, which expanded the vocabulary to 16 English words and could perform simple mathematical calculations.
The 1970s marked a period of accelerated progress, largely fueled by significant funding from the U.S. Department of Defense's Advanced Research Projects Agency (DARPA). The DARPA Speech Understanding Research (SUR) program spurred the development of more capable systems. A key outcome of this initiative was Carnegie Mellon University's "Harpy" system, which represented a monumental leap forward. "Harpy" could recognize a vocabulary of over 1,000 words—roughly equivalent to that of a three-year-old child—and could understand complete sentences. These early systems primarily relied on hand-crafted phonetic rules and template-based pattern matching, which were laborious to create and brittle in the face of speech variability.
The Rise of Statistical Dominance (1980s-2000s): The Impact of HMMs
The 1980s heralded a fundamental paradigm shift away from deterministic rules and toward probabilistic, statistical methods. The cornerstone of this new era was the adoption of the Hidden Markov Model (HMM). An HMM is a statistical model that treats speech as a sequence of states (like phonemes) that are not directly observable but can be inferred from the acoustic signal. By modeling the probabilities of transitioning between these hidden states, HMMs provided a robust mathematical framework for handling the inherent variability of human speech.
When paired with Gaussian Mixture Models (GMMs) to model the acoustic characteristics within each state, the HMM-GMM approach became the dominant architecture in ASR for nearly three decades. This statistical revolution, combined with the development of n-gram language models to predict word sequences, allowed vocabularies to expand dramatically from thousands to tens of thousands of words. The increasing power of personal computers made these computationally intensive models viable for commercial applications. In 1990, Dragon launched "Dragon Dictate," the first consumer-grade STT product, making the technology accessible outside of research labs for the first time. By the turn of the millennium, HMM-based systems had achieved respectable accuracy levels of around 80% on clean speech tasks, but further progress had begun to slow, suggesting the approach was reaching its theoretical limits.
The Deep Learning Disruption (2010s-Present): Neural Networks Revolutionize Accuracy
The 2010s witnessed a second, even more profound paradigm shift: the deep learning revolution. The introduction of Deep Neural Networks (DNNs) shattered the performance plateau of HMM-GMM systems. DNNs, with their ability to learn complex, hierarchical patterns from vast amounts of data, proved far superior at modeling the intricate relationship between acoustic signals and phonetic units.
This disruption was enabled by a confluence of factors: the availability of massive datasets for training (e.g., Google's use of billions of anonymized voice searches) and the parallel processing power of Graphics Processing Units (GPUs), which made it feasible to train these large, computationally expensive models. The result was a dramatic and rapid improvement in accuracy, sparking an "arms race" among major technology companies. Throughout the mid-to-late 2010s, Microsoft, IBM, and Google repeatedly announced new records for low Word Error Rates (WER) on industry benchmarks, with performance steadily approaching, and in some cases surpassing, human parity on specific tasks.
The most recent phase of this era is the move towards end-to-end ASR. These systems employ a single, deep neural network to directly map a sequence of raw audio features to a sequence of text characters, completely replacing the complex, multi-stage pipeline of acoustic modeling, language modeling, and decoding found in traditional HMM and even early hybrid DNN-HMM systems. This end-to-end approach has simplified ASR system design while pushing the boundaries of accuracy even further.
Anatomy of Modern ASR Systems
State-of-the-art ASR systems are complex, multi-stage pipelines that leverage sophisticated deep learning architectures to transform sound into text. While end-to-end models have streamlined the process, the fundamental tasks of processing audio, modeling acoustics, and incorporating language context remain central to their operation.
The End-to-End Pipeline: From Signal to Text
The journey from a spoken utterance to a final text transcription involves several key stages:
Audio Processing & Feature Extraction: The process begins with an analog-to-digital converter capturing the sound waves and transforming them into a digital signal. This raw audio is then pre-processed to remove background noise and normalize volume levels. The signal is segmented into small, overlapping frames, typically 10-25 milliseconds long. From each frame, key acoustic features are extracted to create a compact, numerical representation of the speech. The most common technique for this is the extraction of
Mel-Frequency Cepstral Coefficients (MFCCs), which are designed to capture the phonetically relevant characteristics of the sound in a way that mimics human auditory perception.
Acoustic Modeling: The sequence of feature vectors is then fed into the acoustic model, which is the core of the ASR system. In modern systems, this is a deep neural network. The acoustic model's primary function is to calculate the probability of observing a particular sequence of acoustic features given a sequence of linguistic units, such as phonemes (the basic sounds of a language). For example, it learns to map the acoustic features corresponding to the sound "k" to the phoneme /k/.
Language Modeling: The output of the acoustic model is often a lattice of possible phoneme or character sequences. The language model's role is to evaluate these sequences and determine which one is most likely to be a valid and meaningful sentence in the target language. It does this by leveraging statistical knowledge learned from vast amounts of text data. This is critical for disambiguating acoustically similar phrases. For instance, an acoustic model might struggle to distinguish between "I scream" and "ice cream." A language model, knowing that "ice cream" is a much more common phrase, will assign it a higher probability, leading to the correct transcription.
Decoding: The final stage is decoding, where a search algorithm, such as a Viterbi search or beam search, combines the probability scores from both the acoustic model and the language model. It searches through all possible word sequences to find the single path with the highest overall probability, which is then output as the final text transcription.
The evolution of ASR technology reveals a pattern not of simple replacement, but of compounding advancements. The deep learning era did not discard the conceptual framework established during the statistical era; rather, it supercharged its components. Modern systems still adhere to the fundamental logic of extracting acoustic features and modeling them in the context of language. However, they have replaced the relatively simple statistical models like HMMs and GMMs with vastly more powerful and expressive deep neural network architectures. Even as end-to-end models merge these stages into a single, unified network, the underlying tasks of mapping acoustics to phonetic representations and then to probable word sequences are still being performed—they are simply learned implicitly by the network rather than being engineered as separate, explicit stages. This suggests that future breakthroughs will likely continue this trend, integrating new architectures to enhance or replace specific components within this proven conceptual framework, leading to an evolutionary path of progress rather than a complete reinvention.
Architectural Breakthroughs: The Power of Deep Learning
The dramatic performance gains in modern ASR are a direct result of breakthroughs in neural network architectures. Several key innovations have been pivotal:
Transformer-Based Models: Originally developed for machine translation, the Transformer architecture has become the dominant force in ASR. Its key innovation is the self-attention mechanism, which allows the model to weigh the importance of different parts of the input audio sequence when processing a particular segment. This enables it to effectively capture long-range dependencies and contextual information, a significant advantage over previous architectures like Recurrent Neural Networks (RNNs) that could struggle with long sequences. Models like OpenAI's Whisper, which leverage a Transformer-based encoder-decoder structure, have set new standards for accuracy and robustness across a wide range of languages and acoustic conditions.
Connectionist Temporal Classification (CTC): CTC is a loss function and decoding algorithm that was a critical enabler for end-to-end ASR. A major challenge in speech recognition is that the alignment between the audio frames and the corresponding text characters is not known in advance. CTC cleverly solves this by introducing a special "blank" token and allowing the network to output a sequence of predictions (including blanks) for each audio frame. It then collapses repeated characters and removes blanks to produce the final transcription. This allows the network to be trained directly on audio-text pairs without needing a pre-aligned dataset, greatly simplifying the training process for end-to-end models. Many state-of-the-art systems now use a hybrid CTC-attention architecture, which combines the alignment-free training benefits of CTC with the superior context modeling of attention-based decoders.
Sequence-to-Sequence (S2S) Architectures: Most modern end-to-end ASR systems are based on a sequence-to-sequence (or encoder-decoder) model. The encoder, often a stack of Transformer layers, processes the input audio features and compresses them into a high-level numerical representation that captures the essential information. The decoder, also typically Transformer-based, then takes this representation and generates the output text sequence one character or word at a time. This flexible architecture forms the foundation for the most powerful ASR systems today.
This shift towards end-to-end deep learning models has had a profound impact on the competitive dynamics of the ASR field. The complexity of building high-performance systems has moved from requiring deep, specialized expertise in phonetics and statistical signal processing to requiring massive computational resources and access to vast, diverse datasets. This has democratized access to the technology to some extent, as open-source models like Whisper can provide state-of-the-art performance out of the box. However, it has also concentrated power in the hands of large technology corporations like Google, Microsoft, Amazon, and OpenAI, who possess the unique ability to amass the enormous datasets and deploy the large-scale GPU clusters necessary to train these foundational models from scratch.
The Cutting Edge: Emerging Architectures
Research in ASR is advancing at a breakneck pace, with new architectures emerging that promise to push the boundaries of performance even further.
State-Space Models (SSMs): A new class of deep learning architecture, exemplified by models like Mamba, is gaining traction as a potential successor to the Transformer for modeling long sequences. SSMs are inspired by classical state-space models from control theory and are designed to capture temporal dependencies with linear complexity, in contrast to the Transformer's quadratic complexity with respect to sequence length. This makes them highly efficient for processing very long audio inputs. ASR systems built with this architecture, such as Samba-ASR, have demonstrated superior accuracy and efficiency on standard benchmarks, suggesting that SSMs may become a key component of next-generation ASR.
Speech-Native and Speech-to-Speech (STS) Models: The most transformative trend on the horizon is the development of models that bypass the intermediate text representation entirely. These "speech-native" or speech-to-speech models process audio input directly and can generate a spoken response in real-time. OpenAI's gpt-realtime is a leading example of this approach, capable of achieving ultra-low latency (under 300 milliseconds) that makes conversations with an AI feel truly natural and fluid. This represents a paradigm shift for conversational AI, moving from a multi-step "transcribe-then-understand-then-synthesize" pipeline to a single, direct audio-to-audio interaction model.
Applications and Industry Impact
The maturation of Speech-to-Text and Voice AI technologies has catalyzed their adoption across a broad spectrum of industries, moving them from niche applications to mission-critical components of digital transformation. The ability to seamlessly convert spoken language into actionable data has unlocked significant value, enhancing user experiences, streamlining operations, and creating entirely new product categories. This part of the report examines the specific applications and operational impacts of Voice AI in key sectors, analyzing the distinct value propositions that are driving its widespread deployment.
The Conversational Home and Office: Consumer Electronics
The consumer electronics sector has been the primary beachhead for Voice AI, introducing the technology to hundreds of millions of users and normalizing conversational interaction with devices.
The Ubiquity of Virtual Assistants
Virtual assistants are the most prominent and recognizable application of Voice AI. Platforms such as Amazon's Alexa, Apple's Siri, and Google Assistant have become integrated into the daily lives of consumers worldwide. These assistants serve as the central hub for a vast ecosystem of voice-activated services. They leverage a full stack of Voice AI technologies: STT is used to transcribe the user's spoken command, NLU processes the underlying intent, and TTS provides a natural-sounding verbal response. This enables them to perform a diverse range of tasks, including answering general knowledge questions, setting timers and reminders, initiating phone calls, and controlling a wide array of connected devices. The integration of these assistants across a multitude of hardware platforms—including smartphones, smart speakers, tablets, smart displays, and personal computers—has been a key factor in their widespread adoption.
Smart Home Automation and Hands-Free Control
One of the most powerful drivers for the adoption of virtual assistants has been their role in smart home automation. Voice AI provides an intuitive and natural interface for controlling an ever-expanding ecosystem of connected devices. Users can issue simple voice commands to manage lighting, adjust thermostats, control televisions and media playback, and operate smart appliances, all without physical interaction. This hands-free operation provides a significant boost in convenience and is also a critical accessibility feature, making the modern smart home ecosystem more usable for all individuals.
Productivity and Communication
Beyond home control, Voice AI is increasingly being positioned as a powerful productivity tool. Voice typing and dictation features are now standard in most operating systems and productivity applications, allowing users to compose emails, draft documents, and take notes by speaking. This is often significantly faster and more ergonomic than manual typing, and can result in more natural and conversational written communication. The technology is also used for hands-free messaging and calling, which is particularly valuable in mobile or in-car contexts. In a novel workflow, some advanced users are even employing STT to dictate complex prompts for other generative AI tools like ChatGPT, creating a new form of AI-to-AI interaction that streamlines creative and analytical processes.
Transforming Patient Care and Clinical Documentation: Healthcare
The healthcare industry, traditionally burdened by extensive administrative and documentation requirements, has emerged as a prime sector for Voice AI-driven transformation. The technology is being deployed to alleviate clinician burnout, improve operational efficiency, and enhance patient engagement.
Alleviating Administrative Burden: AI-Powered Medical Transcription
A primary pain point in modern medicine is the significant time clinicians spend on documentation. Voice AI offers a powerful solution by enabling AI-powered medical transcription. Using STT, physicians, nurses, and other healthcare providers can dictate clinical notes, patient histories, and prescriptions directly into Electronic Health Record (EHR) systems. This hands-free, real-time documentation drastically reduces the time spent on manual data entry, which in turn allows clinicians to dedicate more time to direct patient care, thereby improving both the quality of the interaction and overall productivity.
The success of this application hinges on accuracy, as medical documentation is a high-stakes environment. This has led to the development of specialized, domain-specific STT models. Services like Amazon Transcribe Medical are trained extensively on medical terminology, jargon, and clinical language, enabling them to achieve significantly higher accuracy on medical dictation compared to general-purpose models. Some systems function as "virtual scribes," ambiently capturing the natural conversation between a doctor and patient and automatically converting it into a structured clinical note.
Enhancing Patient Engagement and Operations
Voice AI is also being used to reshape how healthcare organizations interact with their patients. Voice-enabled patient portals and virtual health assistants allow individuals, especially those managing chronic conditions, to access health information, receive medication reminders, and communicate with their care providers from the comfort of their homes. This is particularly beneficial for patients with mobility or accessibility challenges. On the administrative side, AI voice agents are being deployed to automate routine tasks such as appointment scheduling, patient intake, and follow-up communications. This not only lowers operational costs but has also been shown to improve patient outcomes; some hospitals report a 25-30% reduction in patient no-show rates after implementing voice AI for scheduling.
Improving Accessibility and Diagnostics
Voice AI serves as a critical accessibility tool within healthcare, enabling patients with visual impairments or limited mobility to interact with digital health platforms and telehealth services using only their voice. Beyond interaction, an emerging and potentially revolutionary application lies in diagnostics. Researchers are discovering that vocal patterns can contain subtle biomarkers for various health conditions. Advanced Voice AI systems are being developed to analyze these vocal biomarkers to detect early signs of neurological disorders like Parkinson's and Alzheimer's disease, as well as cardiovascular conditions and even respiratory illnesses, often before clinical symptoms become apparent.
The New Frontier of Customer Experience: Enterprise and Contact Centers
The enterprise contact center has become one of the most impactful arenas for Voice AI deployment. The technology is being used to transform customer service from a cost center into a source of rich business intelligence and a driver of customer loyalty.
Voice Analytics: Deriving Actionable Business Intelligence
Historically, the vast majority of voice-based customer interactions were ephemeral data points, lost after the call ended. By deploying STT to transcribe 100% of customer calls, enterprises can create a massive, searchable, and analyzable dataset of customer conversations. Applying sophisticated NLP and NLU to these transcripts unlocks a new category of business intelligence known as voice analytics. This allows businesses to:
Perform Sentiment Analysis at Scale: Automatically gauge customer emotion (frustration, satisfaction, confusion) on every call to track overall customer satisfaction and identify drivers of negative experiences.
Identify Customer Intent and Trends: Discover the primary reasons customers are calling, spot emerging product issues or service gaps, and track trends in customer queries over time.
Ensure Quality and Compliance: Automatically monitor calls for agent script adherence, compliance with regulatory disclosures, and overall quality of service.
Real-Time Agent Assist
Voice AI is also being used to augment the capabilities of human agents during live calls. Real-time agent assist platforms listen to the conversation as it happens, providing a live transcription on the agent's screen. More powerfully, the system uses NLU to understand the context of the conversation and proactively help the agent. It can automatically retrieve and display relevant articles from a knowledge base, suggest the next-best action to resolve the customer's issue, provide real-time coaching on tone or empathy, and issue alerts for compliance risks. This real-time support helps agents resolve issues faster and more accurately, leading to significant improvements in key contact center metrics like First-Call Resolution (FCR) and Average Handle Time (AHT).
Automation and Efficiency
A significant portion of contact center volume is driven by simple, repetitive inquiries. AI voice agents and intelligent Interactive Voice Response (IVR) systems are being deployed to automate the handling of these routine queries, such as checking an account balance, tracking an order, or resetting a password. This provides customers with 24/7 self-service options and frees up human agents to focus their expertise on more complex, high-value, or empathetic interactions. Furthermore, Voice AI can automate many of the post-call tasks that consume agent time, such as writing call summaries, categorizing the interaction, and logging follow-up actions. This automation is a major driver of operational efficiency and cost savings in the modern contact center.
The broad applicability of Voice AI across these diverse sectors highlights a crucial strategic trend: verticalization is the key to both monetization and accuracy. While general-purpose STT models provide a baseline level of performance, high-value, mission-critical applications invariably demand specialized, domain-adapted models. A healthcare system needs a model that understands complex medical terminology, not just conversational English. A contact center analyzing low-fidelity telephone audio requires a model tuned for that specific acoustic environment. This is evident in the product strategies of major providers, who offer specialized models for medicine, telephony, and video. The path to superior accuracy and, consequently, premium pricing lies in this deep verticalization. The market is therefore unlikely to be a single, monolithic STT market, but rather a collection of highly specialized niches where domain expertise provides a strong competitive advantage.
Fostering an Inclusive Digital World: Accessibility and Translation
Beyond commercial applications, Voice AI is playing a profound role in making the digital world more accessible and breaking down communication barriers. Its ability to mediate between spoken and written language provides powerful tools for individuals with disabilities and facilitates global interaction.
Real-Time Captioning and Transcription
For individuals who are Deaf or Hard of Hearing, STT technology is a vital accessibility tool. It provides real-time closed captioning for a wide range of content, including live events, online meetings, university lectures, and broadcast media, ensuring that spoken information is accessible to all. Transcription applications like Otter.ai go a step further, creating searchable and shareable notes from meetings and conversations. This not only benefits the hearing-impaired but also provides a valuable resource for individuals with auditory processing disorders, learning disabilities, or anyone who needs a detailed record of spoken content for review.
Voice Commands and Dictation
Speech recognition is a transformative technology for users with physical or mobility impairments that make using a keyboard or mouse difficult or impossible. Voice commands enable hands-free control of computers, smartphones, and other devices, providing a critical pathway to digital independence. Dictation software allows these users to compose text, send messages, and interact with applications using only their voice, a function that is essential for both personal communication and professional productivity.
Breaking Language Barriers: Real-Time Translation
The powerful combination of STT, Neural Machine Translation (NMT), and Text-to-Speech (TTS) is on the verge of enabling seamless, real-time multilingual communication. This technology can create a fluid conversational experience across language divides. In a business meeting, for example, a participant's speech can be captured by STT, the resulting text can be instantly translated by an NMT engine, and the translated text can be synthesized into speech by a TTS engine in the listener's native language. This capability is set to revolutionize global business, international diplomacy, tourism, and cross-cultural collaboration, making language less of a barrier and more of an opportunity for connection.
The evolution of these applications also points to a subtle but significant shift in how Voice AI is being integrated into our lives. The initial paradigm was one of active, command-based interaction, where the user explicitly directs an assistant to perform a task ("Hey Siri, call Mom"). However, the most advanced enterprise and productivity applications are moving towards a model of passive, ambient assistance. In a meeting, the AI transcribes and summarizes in the background without being prompted for every action. In a contact center, it listens to the conversation and provides contextual help to the agent without being asked. In a clinical setting, it documents the patient encounter ambiently. The technology is becoming an invisible, intelligent layer that captures, analyzes, and augments human interaction. This implies a future where the focus of Voice AI design shifts from crafting explicit command structures to creating systems that can intelligently and unobtrusively derive value from the ambient conversational data present in any given environment. This shift, while powerful, also carries profound implications for user privacy and consent, which will be examined later in this report.
The Competitive and Research Landscape
The Voice AI market is a dynamic and fiercely competitive arena, characterized by the dominance of large cloud platform providers, the rapid innovation of specialized startups, and the foundational research contributions of world-leading academic institutions. Understanding this complex ecosystem is critical for any organization seeking to leverage, invest in, or compete in the voice technology space. This part of the report provides a detailed analysis of the key players, their strategic positioning, and a direct comparison of the leading commercial offerings.
The Titans of the Cloud: A Comparative Analysis
The market for enterprise-grade Speech-to-Text services is largely dominated by the three major cloud hyperscalers: Google, Amazon, and Microsoft. These companies leverage their vast infrastructure, massive datasets, and deep AI research capabilities to offer scalable, feature-rich STT platforms that are deeply integrated into their broader cloud ecosystems.
Google Cloud Speech-to-Text
Google's Speech-to-Text service is built on the company's long history of leadership in AI and search. It is powered by advanced foundation models like "Chirp," which are trained on millions of hours of audio data.
Features: The platform is known for its extensive language support, covering over 125 languages and variants. It offers models for synchronous (short audio), asynchronous (long audio), and real-time streaming transcription. Key features include a selection of pretrained models optimized for specific use cases like voice control, phone call audio, and video transcription. It provides robust customization capabilities through model adaptation, which allows the system to be biased towards specific words or phrases, and class tokens for formatting numbers, currencies, and addresses. Google also emphasizes enterprise-grade security with features like data residency controls, customer-managed encryption keys, and an on-premise deployment option for maximum data control.
Market Position: Google is often lauded for its quick real-time transcription capabilities and the sheer breadth of its language coverage. However, some independent benchmarks have suggested that its real-time accuracy can sometimes lag behind more specialized competitors, making it a strong choice for applications requiring broad language support or deep integration with the Google Cloud ecosystem, but potentially less so for use cases where absolute lowest latency and accuracy are paramount.
Amazon Transcribe (AWS)
Amazon Web Services (AWS) has positioned its Amazon Transcribe service as a core component of its comprehensive suite of AI and machine learning tools.
Features: Transcribe supports both real-time streaming and batch transcription. Its standout features are particularly strong for analyzing conversational audio. These include automatic language identification, highly accurate speaker diarization (the ability to distinguish and label different speakers in a single audio stream), and channel identification (separating audio from different channels in a contact center recording). The service also offers custom vocabularies and custom language models for domain-specific adaptation. A key offering is Amazon Transcribe Call Analytics, a specialized service for contact centers that provides turn-by-turn transcripts enriched with insights like customer sentiment, detected issues, and automatic content redaction for personally identifiable information (PII).
Market Position: Amazon Transcribe's greatest strength lies in its seamless integration with the vast AWS ecosystem, making it a natural choice for the millions of businesses already built on AWS. It is widely regarded as a leader in handling multi-speaker conversational audio, making it a top contender for use cases like meeting transcription and call center analytics.
Microsoft Azure Speech to Text
Microsoft's offering is part of its Azure AI services, leveraging decades of research from Microsoft Research and, more recently, its strategic partnership with OpenAI.
Features: The Azure service provides a full suite of transcription capabilities, including real-time, batch, and a unique "fast transcription" API for rapid, synchronous processing of audio files. A core differentiator is its "Custom Speech" feature, which allows for deep model customization by training on user-provided text data (for vocabulary) and audio data with human-labeled transcripts (for acoustic adaptation). The service also integrates OpenAI's powerful Whisper model as an option for transcription. Other advanced features include real-time diarization and pronunciation assessment, which is valuable for educational applications.
Market Position: Azure Speech to Text is a formidable competitor, especially for the large number of enterprises heavily invested in the Microsoft ecosystem (e.g., Office 365, Teams, Dynamics). It is generally considered a solid, reliable, all-around performer that offers strong enterprise-grade security and compliance features.
Other Major Players
Beyond the big three, other large technology companies offer compelling enterprise-grade STT solutions:
IBM Watson Speech to Text: As one of the pioneers in commercial AI, IBM offers a mature and robust STT service. It provides fast and accurate transcription with key enterprise features like speaker diarization, keyword spotting, and smart formatting. A significant advantage of the Watson platform is its deployment flexibility, with options for public cloud, private cloud, and fully on-premises installations to meet stringent data sovereignty and security requirements.
NVIDIA Riva: NVIDIA's Riva is not a simple API but a comprehensive SDK for building high-performance, customizable conversational AI pipelines. It leverages NVIDIA's dominance in GPU hardware to offer highly optimized, low-latency microservices for ASR, TTS, and Neural Machine Translation (NMT). Riva is designed for demanding real-time applications and can be deployed across a wide range of environments, from cloud data centers to edge devices and embedded systems, giving developers maximum control over performance and deployment architecture.
Table 2: Comparative Analysis of Leading Cloud STT Platforms
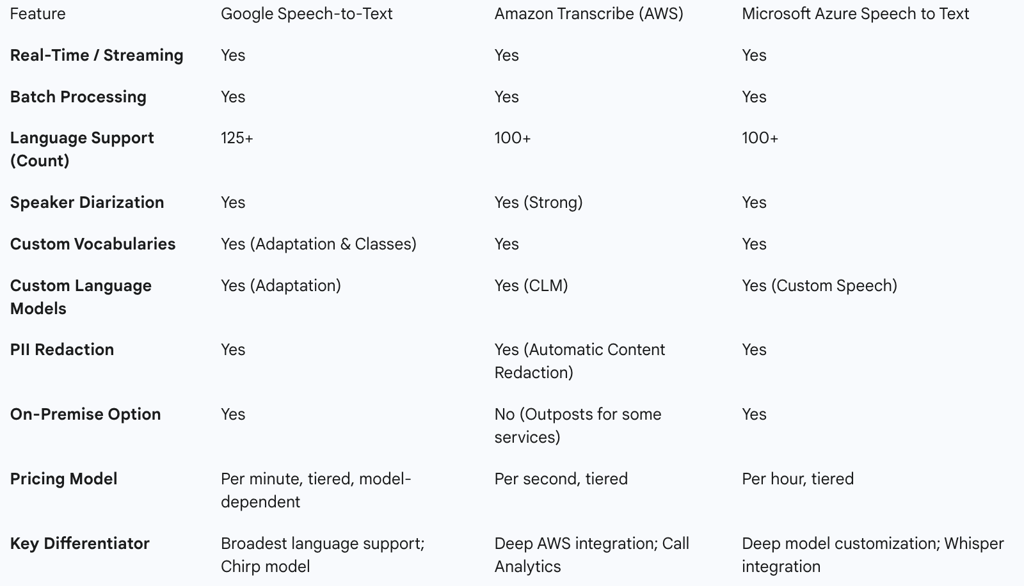
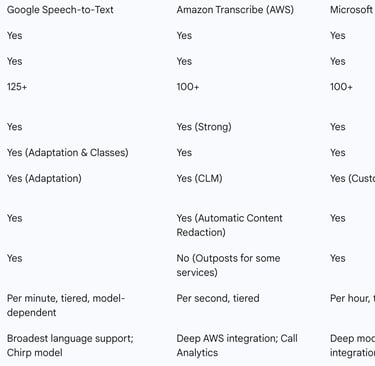
The competitive strategies of these major players reveal a clear market bifurcation. The cloud titans are engaged in a "platform play." For them, STT is one critical service in a vast portfolio. Their primary value proposition is not just the quality of the transcription but the convenience of a single vendor, seamless integration with other cloud services (e.g., storage, databases, analytics), unified billing, and enterprise-wide security and compliance. A developer using AWS for their infrastructure will find it far easier to use Transcribe than to integrate a third-party service. In contrast, a growing number of specialized companies are executing a "performance play." These companies, which will be detailed in the next section, focus on being the absolute best in one specific area—typically raw accuracy (WER) or latency. Their strategy is to win over customers for whom voice is a mission-critical component of their product, and for whom a few percentage points of accuracy or a few hundred milliseconds of latency make a significant business difference. This creates a strategic choice for customers: opt for the convenience and integration of a platform provider, or seek out the superior performance of a specialist, potentially at the cost of greater integration complexity.
The Innovators and Specialists
While the cloud giants define the broad market, a vibrant ecosystem of startups and specialized companies is driving much of the cutting-edge innovation in Voice AI. These firms often focus on solving specific problems or outperforming the incumbents on key performance metrics.
Leaders in Accuracy and Speed
A number of companies compete directly with the hyperscalers on the core metrics of transcription accuracy and processing speed, often targeting developers of real-time voice applications who demand the lowest possible latency.
Deepgram: This company has built its reputation on a foundation of speed and accuracy. It develops its own end-to-end deep learning models, such as its Nova architecture, which it claims can achieve significantly lower Word Error Rates (WER) and process audio many times faster than competing cloud providers. With a focus on low-latency (<300ms) real-time streaming, Deepgram is a popular choice for building responsive voice agents and other time-sensitive applications.
AssemblyAI: Another leader in the performance-focused segment, AssemblyAI provides a highly accurate transcription API built on state-of-the-art models like Conformer-2. Beyond core transcription, it offers a rich suite of advanced features, including highly accurate speaker diarization, sentiment analysis, PII redaction, and automatic summarization, positioning itself as a comprehensive platform for understanding audio data.
Pioneers in Generative Voice and Synthesis
This category includes companies that are not just transcribing voice but creating it, pushing the boundaries of synthetic media.
OpenAI: As a leading AI research lab, OpenAI's contributions are foundational. Its open-source Whisper ASR model has become a de facto industry benchmark for accuracy, forcing commercial providers to justify their value proposition against a powerful free alternative. More recently, with its
gpt-realtime model, OpenAI is pioneering the shift to direct speech-to-speech interaction, a potential game-changer for conversational AI.
ElevenLabs: This company has rapidly emerged as a leader in AI-powered voice synthesis and text-to-speech. It is renowned for its ability to create highly realistic, emotive, and contextually aware synthetic voices. Its technology also includes advanced voice cloning, allowing for the creation of a digital replica of a specific person's voice from a small audio sample. This has applications in everything from audiobook narration and video game character voicing to personalized digital avatars.
Other Key Niche Players
The market also includes a variety of other players targeting specific use cases or technological challenges.
Speechmatics: This UK-based company focuses on the core challenge of understanding every voice, with a particular emphasis on achieving high accuracy across a wide range of global accents, dialects, and languages, tackling the problem of algorithmic bias head-on.
Otter.ai: Rather than providing a raw API, Otter.ai is an application-focused company that has built a popular product for transcribing and summarizing meetings in real-time. It integrates with popular calendar and video conferencing platforms to provide automated meeting notes, making it a leader in the productivity space.
VocaliD: This company occupies a unique and important niche, specializing in creating personalized, high-quality synthetic voices. Its technology is particularly impactful in the accessibility space, where it is used to create custom voices for individuals who have lost their ability to speak due to medical conditions, allowing them to communicate with a voice that is uniquely their own.
The rise of a powerful open-source model like OpenAI's Whisper has been a significant disruptive force in this competitive landscape. By providing state-of-the-art transcription capabilities for free, Whisper has effectively commoditized the basic act of converting speech to text. This has fundamentally altered the value proposition for commercial providers. It is no longer sufficient to simply offer a transcription API. To compete, commercial players must now differentiate on factors that go beyond raw transcription. These include providing enterprise-grade reliability (e.g., uptime SLAs), massive scalability, enhanced security and compliance features, dedicated customer support, and a suite of advanced, integrated functionalities like real-time diarization, sentiment analysis, or PII redaction. The value has irrevocably moved up the stack from the core algorithm to the managed, reliable, and feature-rich service that solves a complete business problem.
Table 3: Key Players in the Specialized Voice AI Market
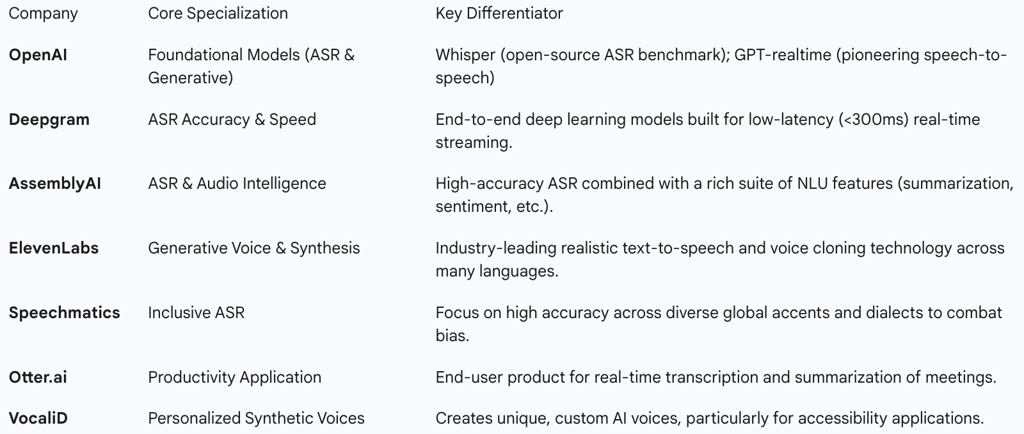
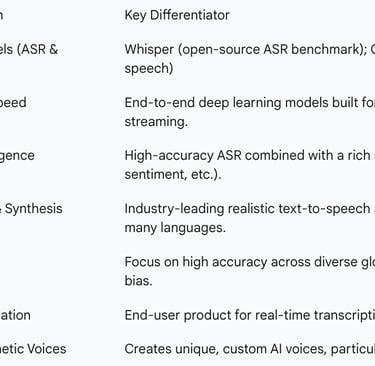
The Academic Vanguard
The commercial boom in Voice AI was built on decades of foundational research conducted in academic laboratories. These institutions laid the theoretical groundwork and developed many of the seminal algorithms and systems that paved the way for today's technology.
Carnegie Mellon University (CMU): CMU has been a dominant force in speech recognition research since the 1970s. Its early work, funded by DARPA, produced the "Harpy" system. Its most famous contribution is arguably the "Sphinx" system, developed in the late 1980s and early 1990s. Sphinx was a landmark achievement, being one of the first systems to successfully demonstrate speaker-independent, large-vocabulary, continuous speech recognition, and it established many of the principles of HMM-based ASR that would dominate the field for years.
MIT Spoken Language Systems (SLS) Group: The SLS group at MIT's Computer Science and Artificial Intelligence Laboratory (CSAIL) takes a holistic view of human-machine interaction. Their research spans the entire conversational pipeline, from paralinguistic analysis ("who is talking," including speaker and language ID) to core ASR ("what is said") and deep understanding ("what is meant"). Their work has made significant contributions to areas like noise robustness, unsupervised learning for low-resource languages, and the development of sophisticated dialogue systems.
Stanford Natural Language Processing (NLP) Group: The Stanford NLP Group is world-renowned for its work at the intersection of computer science, linguistics, and AI. While their focus is broad, their research in speech has been highly influential. They have explored the use of advanced machine learning models for acoustic modeling and have done pioneering work on understanding and modeling prosody (the rhythm, stress, and intonation of speech) and disfluencies (the "ums" and "ahs" of natural speech), bringing a deeper linguistic sophistication to ASR systems.
Challenges, Ethics, and the Path Forward
Despite its remarkable progress and widespread adoption, Voice AI is not a solved problem. The technology faces persistent technical limitations that can impact its reliability in real-world scenarios. Furthermore, its ability to capture and analyze one of the most personal forms of human data—our voice—raises profound ethical challenges related to privacy, bias, and the potential for misuse. This final part of the report provides a critical assessment of these hurdles, explores the ethical imperatives facing the industry, and offers a forward-looking analysis of the trends that will define the future of voice technology.
The Persistent Hurdles: Limitations of Current Technology
While modern ASR systems can achieve impressive accuracy under ideal conditions, their performance can degrade significantly when faced with the complexities of real-world audio. Understanding these limitations is crucial for any organization implementing voice technology.
The Accuracy Problem: Understanding Word Error Rate (WER)
The industry-standard metric for measuring the accuracy of an ASR system is the Word Error Rate (WER). WER provides a quantitative measure of a system's performance by comparing its machine-generated transcript (the hypothesis) to a perfect, human-verified transcript (the ground truth). It is calculated by summing the number of errors—substitutions (a wrong word), deletions (a missed word), and insertions (an added word)—and dividing by the total number of words in the ground truth transcript.
Where S is the number of substitutions, D is the number of deletions, I is the number of insertions, and N is the number of words in the reference transcript. A lower WER indicates higher accuracy. State-of-the-art systems can achieve a WER below 5% on clean, standardized benchmark datasets like LibriSpeech.
However, WER is an imperfect metric. Its primary limitation is that it treats all errors as equal. A substitution of "a" for "the" is penalized the same as a substitution of "guilty" for "not guilty," even though the latter has a dramatically different semantic impact. WER also typically ignores errors in punctuation, capitalization, and speaker labeling, all of which are critical for the readability and utility of a transcript.
Real-World Challenges: The "Messy" Audio Problem
The impressive WER scores reported on benchmark datasets often do not translate to real-world performance. The "messy" nature of audio captured outside of a recording studio presents a formidable challenge for ASR systems.
Noise and Acoustic Environment: This is the most significant factor affecting accuracy. Background noise from cafes, offices, or cars; reverberation in a large room; overlapping speech or cross-talk in a meeting; and the use of low-quality or poorly positioned microphones can all dramatically increase error rates. An ASR engine that performs flawlessly on high-quality audiobook narration may be functionally useless when transcribing a low-fidelity conversational phone call.
Accents, Dialects, and Speaker Variability: ASR models are only as good as the data they are trained on. When a model is trained predominantly on data from speakers of a mainstream accent (e.g., General American English), it will almost invariably exhibit a higher error rate when encountering speakers with different regional dialects (e.g., Scottish English) or non-native accents. This is a major technical hurdle and a significant source of algorithmic bias.
Spontaneous Speech Phenomena: Unlike scripted speech, natural conversation is filled with disfluencies (e.g., "um," "ah," repetitions), slang, domain-specific jargon, and code-switching (mixing multiple languages in one conversation). Handling these phenomena gracefully remains a significant challenge for many ASR systems.
Algorithmic Bias: The Data-Driven Divide
The performance disparities related to accents and dialects are part of a larger, more troubling issue: algorithmic bias. Numerous studies have shown that commercial ASR systems often perform significantly worse for certain demographic groups. This includes not only speakers with non-mainstream accents but also women and people of color. Furthermore, individuals with speech disabilities represent a particularly underserved population, with most ASR systems performing inadequately on atypical speech patterns.
This bias is not inherent to the algorithms themselves but is a direct reflection of the data used to train them. If the training dataset is not sufficiently diverse and representative of the global population of speakers, the resulting model will be biased, performing best for the groups that are overrepresented in its training data. This is not merely a technical flaw; it is a critical ethical failure that can lead to the exclusion of marginalized groups from the benefits of voice technology and perpetuate existing social inequalities.
The Trust Imperative: Ethical Considerations and Risks
The power of Voice AI to capture, process, and understand human speech brings with it a host of profound ethical responsibilities and risks. As the technology becomes more deeply integrated into our personal and professional lives, establishing trust through responsible development and deployment is paramount.
Data Privacy and Surveillance
Voice AI systems are, by their very nature, data collection devices. They capture not only the explicit content of our conversations but also a wealth of implicit, highly personal information contained within our vocal patterns. This raises significant privacy concerns regarding unintended data collection, the security of stored voice data, and the potential for surveillance.
Beyond the words spoken, analysis of voice data can be used to infer a user's emotional state, health conditions, age, gender, and other sensitive attributes, often without their explicit awareness or consent. This creates detailed user profiles that can be used for targeted advertising or other purposes the user never intended. The continuous listening required by "always-on" devices like smart speakers also creates the potential for conversations to be inadvertently recorded and transmitted. In response to these concerns, stringent data privacy regulations like the EU's General Data Protection Regulation (GDPR) now classify voice recordings as personal data, requiring companies to obtain explicit consent, provide transparency about data usage, and implement robust security measures.
The Rise of Deepfakes: Voice Cloning, Misinformation, and Fraud
Perhaps the most alarming ethical risk associated with modern Voice AI is the malicious use of voice cloning technology, also known as audio deepfakes. The same advanced generative AI models that create natural-sounding TTS voices can be trained on a small sample of a person's voice to create a hyper-realistic digital replica. This technology can be weaponized for a variety of nefarious purposes:
Fraud and Financial Scams: Criminals can use a cloned voice to impersonate a CEO or senior executive in a phone call (a practice known as "vishing") and direct an employee to make an urgent, fraudulent wire transfer. They can also impersonate a family member in distress to trick individuals into sending money.
Disinformation and Political Manipulation: Malicious actors can create fake audio recordings of political leaders or public figures making inflammatory or false statements, with the intent of influencing elections, inciting unrest, or eroding trust in institutions.
Extortion and Harassment: Voice clones can be used to create fake, incriminating audio clips to blackmail individuals or to perpetrate personal harassment campaigns.
The increasing sophistication and accessibility of voice cloning technology pose a severe threat to social trust, digital media integrity, and the security of voice-based authentication systems.
Accountability and Transparency
When a Voice AI system causes harm—whether through a biased transcription that affects a legal outcome or a flawed voice command that causes an accident—determining accountability is a complex challenge. There is a growing demand for greater transparency in how AI models are trained, the data they use, and their known limitations and biases. Emerging ethical guidelines for AI development emphasize the critical need for robust data protection measures, clear consent mechanisms for data usage, and the establishment of human oversight and clear lines of responsibility for the outcomes produced by AI systems.
The confluence of these profound ethical risks is poised to impose a "trust tax" on the Voice AI industry. The escalating threat from deepfakes and growing public concern over surveillance are creating significant market demand for solutions that prioritize security, privacy, and bias mitigation. Consequently, companies will find that investing in these trust and safety features is no longer an optional compliance cost but a critical competitive differentiator. Those who lead in developing robust safeguards—such as verifiable voice authentication, transparent and user-centric data policies, and auditable bias mitigation frameworks—will be able to command a premium and build a defensible market advantage. In the future of Voice AI, trust will not be an afterthought; it will be a core product feature.
The Future of Voice: Emerging Trends and Predictions
The field of Voice AI is evolving at an extraordinary rate, driven by continuous breakthroughs in machine learning and a clear market demand for more natural, intelligent, and context-aware interactions. Several key trends are shaping the next generation of voice technology.
Beyond Words: Emotion Detection and Vocal Biomarkers
The next frontier for Voice AI is to move beyond simply understanding what is said to comprehending how it is said. Systems are becoming increasingly adept at analyzing paralinguistic cues in the human voice—such as pitch, tone, and cadence—to detect emotional states like stress, excitement, sarcasm, and frustration. This "emotional intelligence" will enable a new generation of more empathetic and effective virtual agents. In a customer service context, an AI could detect a customer's rising frustration and proactively escalate the call to a human agent or adapt its own conversational strategy. In healthcare, this same analytical capability is being applied to identify vocal biomarkers for remote diagnosis and monitoring of various health conditions.
Seamless Multilingual Communication: Real-Time Translation
The convergence of STT, NMT, and TTS is rapidly moving towards the goal of real-time, speech-to-speech translation that feels as fluid as a natural conversation. This will effectively dissolve language barriers in global business meetings, international conferences, and everyday cross-cultural interactions. Leading platforms are expanding their support to over 100 languages and are developing the ability to handle code-switching—the seamless mixing of languages within a single sentence—which is common in multilingual communities.
The Growth of Multimodal and Speech-Native AI
In the future, voice will not operate in isolation. It will be a central component of multimodal systems that fuse speech with other input streams like vision (what the user is looking at), text, and gesture to build a more complete and contextually aware understanding of the user's intent. This will be particularly transformative in augmented/virtual reality (AR/VR) and in next-generation automotive interfaces, where a combination of voice, gesture, and eye-tracking will enable seamless control. Concurrently, the architectural shift to speech-native models that operate with ultra-low latency will make AI-powered conversations virtually indistinguishable from human ones, leading to the displacement of rigid, scripted chatbots by truly dynamic and responsive Voice AI agents.
On-Device Processing: The Privacy-First Paradigm
In direct response to the significant privacy and security concerns surrounding cloud-based voice processing, there is a strong and accelerating trend towards on-device, or edge, processing. By performing ASR and NLU computations directly on the user's device (e.g., a smartphone or smart speaker), sensitive voice data never needs to leave the user's control. This approach dramatically enhances privacy and security, reduces latency by eliminating the round-trip to the cloud, and allows for offline functionality. This privacy-first paradigm will be essential for the adoption of Voice AI in highly regulated industries such as healthcare, finance, and government.
Synthesizing these emerging trends reveals a higher-order trajectory for the industry. The future of Voice AI is not merely "conversational" but deeply "contextual." The most valuable and powerful AI assistants of the future will move beyond simply processing a transcribed text string. They will integrate multiple streams of data to build a rich, holistic understanding of a situation. They will know who is speaking (voice recognition), what they are saying (ASR), how they are feeling (emotion detection), what they are looking at and gesturing towards (multimodal vision input), and what they have done previously (historical context). The fusion of these contextual streams is what will enable the shift from reactive, command-driven assistants to proactive, truly intelligent partners. The ultimate competitive advantage in the future Voice AI market will therefore belong not to the company with the single best ASR model, but to the one that can most effectively build systems that synthesize these disparate contextual layers into a coherent and actionable understanding of a user's world.
Conclusion
The journey of Speech-to-Text and Voice AI from nascent laboratory experiments to a globally integrated technological force has been remarkable. Driven by compounding advancements—from the statistical rigor of Hidden Markov Models to the transformative power of deep learning—the technology has achieved a level of accuracy and utility that has unlocked profound value across consumer and enterprise sectors alike. In the home, it has created a new paradigm of ambient, hands-free interaction. In healthcare, it is alleviating the crushing burden of administrative work and opening new frontiers in diagnostics. In the enterprise, it has converted the customer's voice from an ephemeral interaction into a rich stream of actionable business intelligence.
However, the industry now stands at a critical inflection point. The technical challenges of real-world accuracy, particularly for diverse and underrepresented populations, remain significant. More importantly, the technology's power brings with it a commensurate weight of ethical responsibility. The specter of mass surveillance, the tangible threat of malicious deepfakes, and the insidious problem of algorithmic bias are not peripheral issues but central challenges that will define the industry's future.
The path forward will be shaped by a dual pursuit. On one hand, the technological trajectory points towards a future that is increasingly contextual, not just conversational. The fusion of speech with emotion detection, visual understanding, and other data modalities will create AI systems that are more proactive, personalized, and seamlessly integrated into the fabric of our lives. On the other hand, this technological advancement must be balanced by a renewed commitment to ethical development. The companies that will lead the next era of Voice AI will be those that recognize that trust is not a compliance checkbox but a core product feature. They will compete not only on the accuracy of their models but on the transparency of their data practices, the fairness of their algorithms, and the robustness of their safeguards against misuse. The voice revolution is well underway, but its ultimate success will depend on the industry's ability to innovate responsibly, ensuring that this powerful technology serves to empower and connect humanity, safely and equitably.