Championing DevOps and DataOps: A Strategic Blueprint
The report highlights that DataOps can be viewed as a natural extension of DevOps principles applied to the data lifecycle. This means organizations already invested in DevOps have a significant advantage, as the cultural and procedural foundations are largely transferable.


DevOps represents a collaborative methodology that integrates development and operations teams to automate and streamline the software development lifecycle, thereby ensuring faster and more reliable delivery of applications and services. Its fundamental aim is to reduce the time required for software development and to facilitate the continuous delivery of high-quality software products to clients and users, achieving these objectives through enhanced efficiency and increased velocity.
Complementing this, DataOps comprises a set of collaborative data management practices specifically designed to accelerate data delivery, uphold data quality, foster inter-team collaboration, and extract maximum value from an organization's data assets. This approach seeks to optimize the entire data lifecycle, from initial ingestion to final delivery, ensuring real-time data availability and strengthening cross-functional teamwork.
The combined value of DevOps and DataOps is substantial. When these two methodologies are integrated, they establish a holistic framework for managing both software and data-driven processes. This synergy is particularly vital for modern applications, especially those powered by artificial intelligence (AI) and machine learning (ML) models or complex e-commerce platforms, where the continuous uptime of software and the accuracy and reliability of underlying data are equally paramount.
Both DevOps and DataOps are deeply rooted in Agile and Lean principles, underscoring iterative development, continuous feedback, and the elimination of waste. They share a strong emphasis on core tenets such as collaboration, extensive automation, continuous improvement, and comprehensive observability across their respective pipelines. Successful adoption of these methodologies significantly depends on a profound cultural transformation within the organization, necessitating strong leadership commitment, the dismantling of organizational silos, and the cultivation of an environment that champions continuous learning and shared accountability. Ultimately, the integrated implementation of DevOps and DataOps leads to an accelerated time-to-market for both software and data-derived insights, enhanced reliability and quality, improved scalability and operational efficiency, and a fortified security and compliance posture.
The Dual Pillars of Modern Enterprise Agility
In the contemporary digital landscape, organizations are increasingly recognizing the critical importance of agility, efficiency, and reliability in their technological operations. This recognition has propelled two distinct yet interconnected methodologies to the forefront: DevOps and DataOps. While each addresses specific domains—software development and data management, respectively—their underlying philosophies and strategic objectives reveal a powerful convergence that is essential for achieving comprehensive enterprise agility.
Defining DevOps: Core Principles and Purpose
DevOps is a transformative approach designed to significantly reduce the duration of the software development lifecycle while simultaneously ensuring the continuous delivery of high-quality software applications. This is accomplished by enhancing efficiency and increasing the velocity at which applications are created, deployed, tested, and managed. A fundamental aspect of this methodology is its emphasis on communication, collaboration, and integrated teamwork between development and IT operations teams, effectively dismantling traditional organizational silos that historically hindered progress.
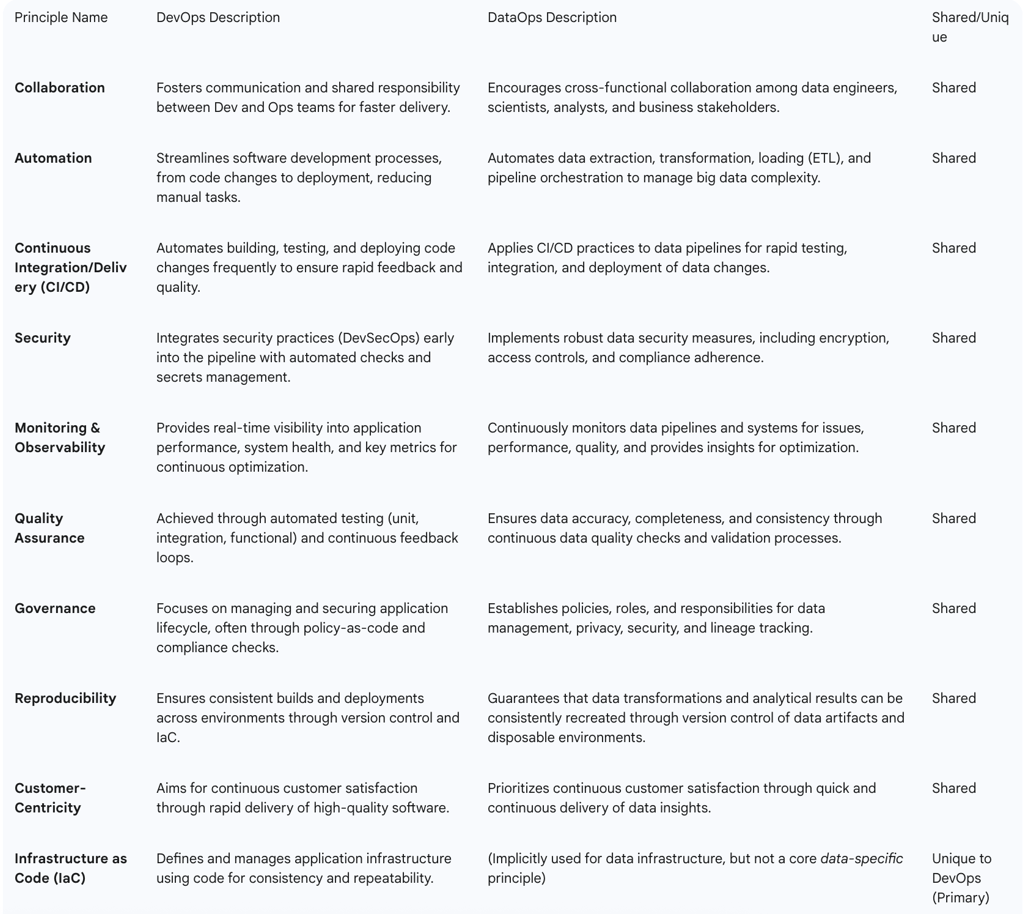
The DevOps methodology is built upon five key principles: collaboration, automation, continuous improvement, customer satisfaction, and designing with the end-user in mind. Automation, in particular, serves as a cornerstone, streamlining processes such as building and testing code to boost velocity and alleviate bottlenecks. By incorporating automation and structured processes, DevOps accelerates the velocity of product releases and workflows. This includes automating code changes and expediting the crucial stages of building, testing, and deployment.
Defining DataOps: Core Principles and Purpose
DataOps represents a complementary set of collaborative data management practices aimed at accelerating data delivery, maintaining data quality, fostering collaboration, and maximizing the value derived from data assets. This methodology is explicitly modeled after DevOps practices, with the intention of automating and introducing agility into data development functions that were previously isolated. Its overarching purpose is to streamline the entire data lifecycle, spanning from initial ingestion to final delivery, thereby ensuring real-time data availability and enhancing collaboration among diverse data teams and business stakeholders.
Central to DataOps are key principles such as data quality monitoring, data pipeline orchestration, and data transformation, all of which are critical for guaranteeing that data is clean, well-organized, and readily available for analysis. Additional foundational elements of DataOps include the creation of robust data products, the alignment of organizational cultures, the operationalization of analytics and data science initiatives, and the systematic application of structured methodologies and processes. The DataOps Manifesto further expands on these concepts, articulating 18 principles that underscore continuous customer satisfaction through the rapid delivery of insights, the prioritization of functional analytics, adaptability to change, fostering teamwork, facilitating daily interactions, promoting self-organization, minimizing "heroism," encouraging continuous reflection, treating "analytics as code," emphasizing orchestration, ensuring reproducibility, utilizing disposable environments, advocating simplicity, viewing "analytics as manufacturing," prioritizing quality, continuous monitoring, promoting reuse, and striving to improve cycle times.
The Strategic Convergence: Why DevOps and DataOps are Intertwined
DevOps and DataOps originate from remarkably similar philosophical underpinnings, sharing a fundamental commitment to collaboration, extensive automation, and comprehensive observability. DataOps, in essence, is a strategic amalgamation of Lean manufacturing, Agile development, and the core principles of DevOps, specifically adapted for the unique challenges of the data domain. Much like DevOps, DataOps embraces an agile methodology, prioritizing the continuous delivery of analytical insights to meet customer needs. This profound philosophical and methodological overlap makes their combined adoption a logical and powerful progression for modern enterprises seeking to enhance their digital capabilities.
The consistent framing of DataOps as being "modeled after DevOps practices" and as "essentially a mix of these methodologies: Lean manufacturing, Agile development, DevOps" indicates a clear relationship. The success and principles established by DevOps in software delivery have provided a direct blueprint for applying similar efficiencies and collaborative approaches to the complex domain of data and analytics. DataOps is not merely a parallel or competing methodology; rather, it is a specialized application and evolution of DevOps thinking tailored to the data lifecycle. For organizations that have already embarked on a DevOps journey, there is a significant advantage in adopting DataOps. The existing cultural understanding of collaboration, automation, and continuous improvement, along with established Continuous Integration/Continuous Delivery (CI/CD) practices, can be directly leveraged and extended to data pipelines. This can potentially reduce the learning curve and help overcome initial resistance to change, making the transition smoother and more effective.
Key Differences and Overlaps
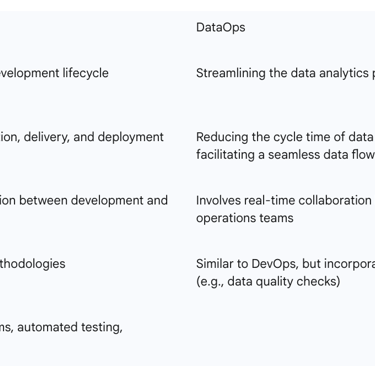
While deeply related, DevOps and DataOps are differentiated by their primary areas of focus. DevOps centers on streamlining the software development lifecycle to automate application development, with an emphasis on faster delivery, improved user experience, and product consistency. Its success is often measured by metrics such as deployment frequency, mean time to recovery (MTTR), and change failure rate.
Conversely, DataOps concentrates on streamlining the data analytics pipeline. Its objective is to ensure data quality, accuracy, and reliability, thereby facilitating faster and more impactful data-driven decisions. DataOps success metrics include ingestion speeds, error rates, mean time to decision, and source performance consistency.
Despite these distinct focuses, significant commonalities exist. Both methodologies champion collaboration between teams, extensive automation of processes, the implementation of CI/CD principles, embedding security throughout their respective pipelines (DevSecOps for software, data security and governance for data), and comprehensive observability.
The research consistently highlights that when combined, DataOps and DevOps can create a holistic approach to managing software and data-driven processes. This is exemplified in scenarios where DevOps ensures application uptime while DataOps feeds accurate data into AI models, or where DevOps manages site reliability while DataOps ensures data-driven features like personalized recommendations for e-commerce platforms. This illustrates that in the contemporary digital landscape, particularly with the rise of data-intensive applications, software functionality is intrinsically linked to and often dependent on the quality and availability of data. Therefore, achieving true digital transformation and maintaining a competitive edge is no longer about optimizing just one aspect—software or data—but requires a unified, integrated strategy that ensures excellence across the entire "full stack" of digital operations, from code to insight. Businesses aspiring to leverage advanced capabilities such as AI-powered applications, real-time analytics, or highly personalized customer experiences cannot afford to optimize only their software delivery or only their data pipelines in isolation. A truly effective strategy necessitates a unified approach to both, ensuring that the software is robust and the data fueling it is reliable and timely.
Table 1 provides a concise comparison of the key differentiators and overlaps between DevOps and DataOps.
Table 1: Key Differentiators and Overlaps: DevOps vs. DataOps

2. Core Principles and Best Practices for DevOps
DevOps is not merely a set of tools or processes; it is a cultural and operational paradigm shift underpinned by several core principles and best practices. These elements collectively aim to enhance the speed, quality, and reliability of software delivery.
Collaboration and Shared Responsibility
The most fundamental requirement for successful DevOps implementation is the cultivation of an environment that prioritizes collaboration and continuous improvement. This involves establishing a shared responsibility between development and operations teams, supported by rapid, automated feedback loops and proactive communication. Essential cultural practices to foster this environment include clearly aligning on objectives, ensuring all team members understand the goals and the challenges DevOps seeks to address. Additionally, it is advisable to initiate the DevOps journey by starting small, perhaps with a pilot team or a specific project, to allow for experimentation and process refinement before scaling practices organization-wide. Furthermore, utilizing a data-driven approach to improvement, by tracking progress with baseline metrics such as build times and deployment frequency, is crucial for iterative enhancement.
This collaborative culture serves as the bedrock for trust and accountability, effectively mitigating communication gaps, enhancing transparency, and eliminating inefficiencies that typically arise from traditional siloed processes. The consistent emphasis on collaboration as "the most fundamental requirement" and as the builder of a "foundation of trust and accountability" suggests its foundational role. Without genuine collaboration, the technical benefits derived from automation, CI/CD, and monitoring will be significantly hampered. For instance, automated tests might execute, but if developers and operations personnel do not communicate effectively about the feedback received, issues will persist. Similarly, if Infrastructure as Code (IaC) is implemented without a shared understanding across teams, it can lead to misconfigurations and deployment failures. Therefore, collaboration is not merely a principle but an essential prerequisite that enables the effective implementation and sustained success of all other DevOps technical practices. Organizations must prioritize cultural initiatives to foster collaboration and shared responsibility before or alongside significant technical investments in DevOps tools, as a failure to address cultural barriers will limit the return on investment of technical solutions.
Continuous Integration and Continuous Delivery (CI/CD)
Automation and CI/CD are central pillars of DevOps, empowering teams to minimize manual tasks, standardize processes, and significantly increase delivery speed.
Continuous Integration (CI) involves the practice of continually checking code changes before merging them into a central source code repository. The primary objective of CI is to rapidly validate changes and provide prompt feedback to software engineers, enabling them to identify and resolve issues early in the development cycle, ideally before the code is merged into the main codebase. Best practices for CI include committing code early and frequently to facilitate rapid feedback, and ensuring that the artifact is built only once to guarantee consistent test results across various stages.
Continuous Delivery (CD), often extended to Continuous Deployment, is the practice of rapidly deploying changes, typically after thorough validation in test and staging environments. Continuous Delivery specifically requires a manual approval or trigger before deployment to production, whereas Continuous Deployment is fully automated, moving changes directly to production upon successful validation. Automated CI/CD pipelines enable continuous testing and deployment, providing swift feedback on code changes and ensuring quality without impeding development velocity. Implementing automated tests at each stage of the pipeline is paramount. This embodies the "shift left" approach, wherein issues are identified and addressed earlier in the development cycle, thereby minimizing downstream risks and costs.
Security-First (DevSecOps)
Integrating security practices directly into DevOps pipelines is critical, particularly given the extensive access CI/CD systems often have to sensitive information and production environments. This "security-first" approach, often termed DevSecOps, mandates that security, testing, and time-to-release are prioritized from the very beginning of the development process. Key practices include robust secrets management to protect sensitive data such as credentials and tokens, implementing automated security checks (including static analysis and policy enforcement) to detect vulnerabilities early, and ensuring end-to-end encryption to secure data throughout the entire pipeline. CI/CD pipelines provide an excellent mechanism for automating regular security checks, not only for application binaries but also for infrastructure files like Kubernetes manifests or Terraform configurations.
Infrastructure as Code (IaC)
Infrastructure as Code (IaC) is a foundational DevOps principle that enables teams to define and manage their infrastructure using code. This approach renders infrastructure version-controlled, repeatable, and consistent across environments. Tools such as Terraform and CloudFormation allow developers to describe and provision infrastructure resources in a declarative manner. This practice facilitates the decentralization of infrastructure management, leading to streamlined and decoupled change management across teams. Furthermore, IaC ensures consistency and reproducibility across multiple production environments, drastically reducing manual errors and maintaining configuration uniformity.
While IaC is frequently highlighted for its automation capabilities, its benefits extend beyond mere automation. The ability to define infrastructure as code makes it "repeatable and consistent" , and it contributes to the "decentralization of infrastructure management, leading to streamlined and decoupled change management across teams" and "ensures consistency and reproducibility across multiple production environments". This indicates that IaC's value transcends initial setup automation; it fundamentally transforms how infrastructure is managed. It enables rapid, error-free scaling and ensures that environments—development, testing, and production—are identical, which is crucial for predictable deployments, effective debugging, and maintaining system stability in complex, distributed systems. For organizations operating at scale or with dynamic infrastructure needs, IaC is not just a technical convenience but a strategic imperative. It directly impacts the reliability, security, and agility of the entire software delivery pipeline, allowing for faster innovation by providing a stable, version-controlled foundation.
Continuous Monitoring and Observability
Observability is crucial for DevOps teams to gain deep control over system performance, providing actionable insights that reduce downtime and enhance reliability. Key metrics for measuring success and guiding improvements include deployment frequency, change lead time, and mean time to recovery (MTTR). Unified dashboards are essential for consolidating data from various sources, offering a single, transparent view of system health. This allows teams to establish benchmarks and continuously optimize performance. Regularly reviewing pipeline performance, typically on a monthly basis, helps identify trends and pinpoint which tests are most likely to cause failures, enabling proactive adjustments and improvements.
The consistent emphasis on "continuous improvement" and the importance of "fast, automated feedback" or "rapid feedback to developers" reveals a critical underlying pattern: DevOps is fundamentally driven by robust feedback loops. Automated testing provides immediate feedback on code quality, while continuous monitoring and observability offer real-time insights into system performance and user experience. This constant stream of information directly informs subsequent iterations and improvements, creating a virtuous cycle of learning and adaptation. Implementing comprehensive monitoring and feedback mechanisms is therefore not merely a technical requirement but a strategic enabler for fostering a culture of continuous learning and adaptation. This iterative learning process, fueled by data, is a core competitive advantage derived from DevOps, allowing organizations to quickly identify and rectify issues, and continuously optimize their processes and products.
Table 2 provides a comparative overview of foundational principles shared and distinct between DevOps and DataOps.
Table 2: Foundational Principles of DevOps and DataOps
3. Core Principles and Best Practices for DataOps
DataOps extends the agile and lean principles of DevOps to the complex domain of data management and analytics. It emphasizes a structured approach to ensure data quality, streamline pipelines, and foster collaboration across the data lifecycle.
Data Quality Management and Validation
Data quality stands as a central pillar of DataOps, ensuring that data is clean, well-organized, and readily available for analysis. It is paramount for guaranteeing that data is accurate, complete, and relevant for effective decision-making and analytical purposes. Best practices within DataOps involve implementing automated abnormality detection, often referred to as "jidoka," and providing continuous feedback, known as "poka-yoke," to proactively prevent errors from propagating through the data pipeline. This necessitates implementing rigorous data quality tests at each stage of the data pipeline, utilizing techniques such as data profiling, schema validation, and outlier identification to detect anomalies and mistakes early. DataOps also advocates for continuously testing and monitoring data pipelines to ensure their correct functioning and adherence to governance standards. Key data quality metrics to monitor include freshness (the recency of data updates), distribution (whether data values fall within acceptable boundaries and are correctly formatted), volume (identifying missing data or successful ingestion rates), schema (tracking structural changes and their intentionality), and lineage (understanding the upstream source, transformations, and downstream consumers of data).
Multiple sources consistently emphasize data quality as a central and critical component of DataOps, ensuring data is "clean, well-organised, and ready for analysis" and "reliable and trustworthy". In the context of modern enterprises increasingly relying on AI/ML models and advanced analytics for strategic decisions, the quality of the output—insights and model predictions—is directly dependent on the quality of the input data. Flawed or untrustworthy data can lead to erroneous models, poor business decisions, and a significant erosion of confidence in data-driven initiatives. DataOps' rigorous and automated focus on data quality, from ingestion to consumption, is therefore not just a technical best practice but a fundamental prerequisite for building and maintaining trust in an organization's data assets and the insights derived from them. Organizations cannot achieve reliable AI/ML capabilities or truly data-driven decision-making without a robust DataOps strategy that rigorously prioritizes and automates data quality across the entire data lifecycle. This investment is critical for competitive advantage in an increasingly data-centric world.
Automated Data Pipelines and CI/CD for Data
Automation is a crucial best practice in DataOps, enabling businesses to streamline operations, significantly reduce manual errors, and effectively manage the inherent complexity and vast volume of big data. Implementing Continuous Integration and Delivery (CI/CD) procedures is a critical best practice within DataOps, empowering enterprises to test and apply improvements to their data operations rapidly and efficiently. This capability allows teams to make data-driven decisions more quickly while simultaneously reducing errors and enhancing overall data quality.
DataOps involves the automation of repetitive and manual data processing operations, such as data extraction, transformation, and loading (ETL). Tools like Apache Airflow, Kubernetes, or generic CI/CD pipelines are utilized to automate data intake, transformation, and loading processes. Pipeline orchestration tools are essential for managing the flow of data, automating tasks like extraction schedules, data transformation, and loading processes, and ensuring that complex data workflows execute smoothly, thereby saving data teams considerable time and resources. The research consistently highlights that automation "aids firms in managing the complexity and amount of big data and scaling their data operations" and "reduces errors and boosts productivity by automating repetitive and manual data processing operations". This establishes a clear relationship: the sheer volume, velocity, and variety of modern "big data" inherently overwhelm manual processes. Automation, by providing efficient and repeatable workflows, removes these human-imposed bottlenecks, making sustainable growth and adaptation to fluctuating demands possible without a proportional increase in human effort. For any organization dealing with significant or rapidly growing datasets, automation of data pipelines is not a luxury but a strategic necessity. It underpins the ability to maintain agility, derive continuous value from data, and support large-scale analytical initiatives.
Data Governance and Security
Data security is an essential best practice in DataOps, particularly given that extensive data often contains sensitive and private information. It enables businesses to safeguard their information against illegal access, modification, and misuse, while ensuring that data is maintained and utilized in accordance with organizational policies, legal mandates, and regulatory standards. Governance processes within DataOps are crucial for protecting data and ensuring alignment with various regulations and internal organizational policies. These processes define accountability for specific data assets, regulate permissions for accessing or modifying data, and meticulously track data origins and transformations (lineage) to provide greater transparency throughout the data lifecycle. The process transparency inherent in DataOps directly addresses governance and security concerns by providing clear visibility into who is using data, where it is flowing, and who possesses permissions upstream or downstream.
The research consistently links DataOps with robust data security and compliance. One document specifically mentions that "governance processes make sure data is protected and aligns to various regulations and organizational policies" and that they "track origins and transformations as data flows through pipelines for greater transparency". This implies that DataOps is not solely about speed and efficiency; it is about embedding compliance and security into the data lifecycle itself, rather than treating them as external, post-processing audits. This proactive, integrated approach significantly reduces legal, financial, and reputational risks associated with data breaches, misuse, or non-compliance (e.g., GDPR, HIPAA). For organizations operating in highly regulated industries, such as finance or healthcare, or those handling sensitive customer data, DataOps is a strategic necessity. It ensures continuous adherence to regulatory standards and simplifies audit processes by providing inherent transparency and control over data assets, transforming compliance from a reactive burden to an integrated capability.
Data Version Control and Reproducibility
A key DataOps best practice is the systematic use of version control for data artifacts, mirroring established software development practices. This allows for the meticulous tracking of changes and data transformations throughout the data lifecycle. The principle of "make it reproducible" is fundamental, dictating that all components—including code and configurations—must be versioned to ensure that analytical results and data products can be consistently recreated at any point in time. Additionally, the concept of "disposable environments" is crucial. This practice advocates for technical environments and Integrated Development Environments (IDEs) that can be easily provisioned and de-provisioned, keeping experimental costs to a minimum and facilitating rapid iteration and testing without impacting production systems.
The emphasis on "data version control" , "make it reproducible" , and "disposable environments" within DataOps strongly aligns with the principles of scientific rigor. In data science and analytics, the ability to reproduce results is paramount for validating models, debugging issues, ensuring the integrity of findings, and building trust in data products. Versioning not only the code but also the data and configurations, combined with the use of ephemeral environments for experimentation, allows data teams to conduct rigorous, controlled experiments, trace back any anomalies, and ensure that insights are robust and verifiable, much like a scientific experiment. DataOps fosters a more scientific, transparent, and trustworthy approach to data analytics and machine learning. By ensuring reproducibility, organizations can build higher confidence in their data-driven insights and accelerate innovation through systematic, controlled experimentation, reducing the risk of "black box" outcomes.
Continuous Improvement and Customer-Centricity
DataOps is fundamentally understood as a continuous process rather than a one-time implementation. It necessitates ongoing evaluation and adjustment of data pipelines for performance, scalability, and efficiency. A critical aspect of this continuous improvement is actively soliciting feedback from both team members and stakeholders to drive necessary enhancements.
DataOps places a high priority on the customer, striving to provide the highest value through the quick and continuous delivery of data insights. This methodology encourages organizations to embrace change and adapt swiftly to evolving customer needs, which frequently requires data engineers to continuously learn and integrate new technologies, such as AI tools, in real-time. Regular reflection on performance—whether it pertains to individual contributions, customer satisfaction, or operational statistics—is vital for identifying areas for improvement and continuously enhancing the value delivered to the customer. The DataOps Manifesto explicitly lists "Continually satisfy your customer" and "Embrace change" as core principles , directly linking them to "real-time learning about changing customer behaviors" and adapting to evolving needs. This is reinforced by the emphasis on continuous evaluation and feedback from stakeholders. This establishes a direct relationship: the evolving needs and feedback from internal and external customers are the primary drivers for continuous improvement within DataOps. Unlike traditional, often static, data warehousing approaches, DataOps is designed to be highly responsive and adaptive, constantly refining data products and insights to maximize their value and relevance to the business and its end-users. DataOps elevates data initiatives from a purely technical backend function to a strategic, customer-facing asset. By embedding customer-centricity and continuous feedback into the data lifecycle, organizations can significantly enhance their business agility and competitive responsiveness, ensuring that data insights are always aligned with current and future business demands.
4. Strategic Benefits of Integrated DevOps and DataOps Adoption
The adoption of DevOps and DataOps, both individually and in combination, yields a multitude of strategic benefits that are crucial for modern enterprises seeking to thrive in a rapidly evolving digital landscape. These benefits collectively contribute to enhanced operational efficiency, accelerated innovation, and strengthened market competitiveness.
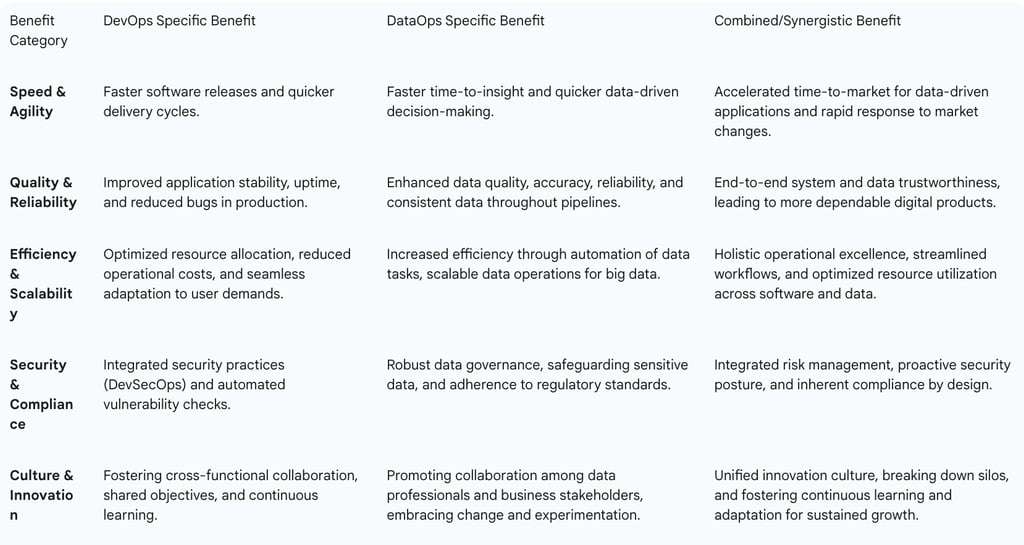
Accelerated Time-to-Market for Software and Insights
DevOps significantly shortens the software development lifecycle, leading to faster product releases and quicker software delivery. Concurrently, DataOps reduces the time required to access and analyze data, thereby enabling quicker decision-making and a faster time-to-insight. The integration of both methodologies results in a powerful synergy, delivering quicker releases of applications alongside faster, more reliable insights. This combined acceleration allows organizations to respond to dynamic business needs and leverage data-driven decisions with unprecedented speed.
Both DevOps and DataOps individually promise accelerated delivery. However, the available information emphasizes that their combination creates a "holistic approach" leading to "quicker releases" and "faster insights". This indicates a synergistic effect: rapid software delivery (enabled by DevOps) means new features and applications can be launched quickly, while rapid data insights (enabled by DataOps) ensure those features are informed by real-time data and can adapt swiftly based on user behavior and market shifts. This combined acceleration translates directly into a profound enhancement of overall business agility, enabling organizations to outmaneuver competitors and capitalize on opportunities with greater speed and precision. In today's dynamic markets, true business agility is not solely about rapid software deployment but equally about the ability to rapidly derive and act upon data-driven intelligence. Therefore, integrating DevOps and DataOps becomes a strategic imperative for organizations seeking a sustainable competitive advantage and the capacity for continuous innovation.
Enhanced Reliability and Quality Across Applications and Data
DevOps leads to improved reliability, enhanced application stability, and increased uptime, significantly reducing the occurrence of bugs in production environments. Simultaneously, DataOps ensures improved data quality, accuracy, and reliability, resulting in a reduction in data errors and consistent data quality throughout the data pipeline. The integration ensures that while DataOps provides reliable, trustworthy, and high-quality data to fuel applications, DevOps ensures the software itself is reliable, stable, and consistently available. This creates a highly dependable digital ecosystem.
Traditional software and data development often treat quality assurance as a distinct, often late-stage, activity. However, the information consistently shows that both DevOps (through "shift-left" testing and automated tests ) and DataOps (through continuous data quality checks ) embed quality throughout their respective lifecycles. This reveals a fundamental paradigm shift: quality is not "tested in" at the end, but rather continuously "built-in" and monitored from the very beginning. The result is a consistently higher quality output for both software applications and data assets. Organizations adopting these methodologies move beyond reactive bug fixing and data cleansing to a proactive, continuous quality assurance model. This leads to inherently more stable systems, trustworthy data, and ultimately, greater confidence in digital products and data-driven decisions.
Improved Scalability and Operational Efficiency
DevOps enables systems to adapt seamlessly to growing infrastructure and user demands. It optimizes resource allocation, leading to reduced operational costs and enhanced organizational agility. DataOps achieves increased efficiency by automating repetitive tasks, resulting in significant savings of resources and costs. It also facilitates the effective scaling of data operations to handle increasing data volumes and complexity. Integrated DevOps and DataOps lead to streamlined workflows, drastically reduced manual errors, and increased overall productivity. This allows for optimized resource allocation across both application and data ecosystems.
The information repeatedly links automation to scalability. One document states that automation "replaces manual tasks with efficient, repeatable processes" and "allows teams to allocate resources more effectively". Other sources explicitly highlight automation's role in "managing the complexity and amount of big data and scaling their data operations". This demonstrates a clear relationship: manual processes are inherently limited in their capacity to handle increasing loads and complexity. Automation, by providing efficient and repeatable workflows, removes these human-imposed bottlenecks, making sustainable growth and adaptation to fluctuating demands possible without a proportional increase in human effort. For organizations anticipating significant growth in user base, data volume, or application complexity, automation is not merely a cost-saving measure but a fundamental enabler for future expansion. It ensures that operations can scale efficiently and reliably, preventing performance degradation and resource exhaustion.
Strengthened Security and Compliance Posture
DevOps integrates security practices throughout the development pipeline (DevSecOps), automating security checks and ensuring proactive protection against vulnerabilities. DataOps implements robust data governance frameworks that safeguard sensitive data and ensure adherence to legal and regulatory standards such as GDPR and HIPAA. The integrated approach leads to a more proactive and comprehensive security posture, reducing overall risks and improving operational stability across both software and data assets. This "security by design" philosophy embeds compliance and protection into the very fabric of operations.
Both methodologies emphasize integrating security and compliance directly into their respective processes. DevOps promotes DevSecOps, embedding security checks early in the CI/CD pipeline. DataOps mandates robust data governance, ensuring data protection and regulatory alignment from ingestion to consumption. This signifies a shift from a reactive, perimeter-based security model or post-development compliance audits to a proactive, continuous, and embedded approach. This "security by design" ensures that vulnerabilities are identified and mitigated earlier, and compliance is an ongoing state rather than a periodic scramble, significantly reducing both the attack surface and the burden of regulatory adherence. Adopting integrated DevOps and DataOps helps organizations build inherently more secure and compliant systems. This is particularly crucial in an environment of escalating cyber threats and increasingly stringent data privacy regulations, providing a competitive edge through enhanced trust and reduced risk.
Fostering a Culture of Innovation and Collaboration
Both DevOps and DataOps fundamentally emphasize and promote cross-functional collaboration, shared objectives, and a culture of continuous learning. These methodologies actively work to dismantle organizational silos, leading to improved communication, greater transparency, and enhanced accountability across teams. They encourage experimentation and embrace a "blameless retrospective" approach to failures, viewing them as valuable learning opportunities rather than sources of blame. This psychological safety fosters an environment where innovation can thrive.
While the technical and operational benefits of DevOps and DataOps are compelling, the information repeatedly and strongly emphasizes the "cultural shift" as a critical, if not the most critical, element. This suggests that the deepest and most sustainable benefit derived from these methodologies is the fundamental reshaping of organizational culture. Moving from siloed, blame-oriented teams to collaborative, learning-oriented, and empathetic teams is what truly unlocks continuous innovation, resilience, and adaptability. It is not merely about doing things faster or more reliably, but about doing them
smarter through collective intelligence and shared responsibility, creating a self-improving ecosystem. The long-term success and sustained competitive advantage derived from DevOps and DataOps are less about the specific tools or processes adopted and more about the profound cultural transformation they enable. Organizations must recognize and actively cultivate this cultural shift as the ultimate differentiator, as it directly impacts their capacity for sustained innovation and market leadership.
Table 3 provides a comprehensive summary of the benefits derived from adopting DevOps and DataOps, both individually and synergistically.
Table 3: Comprehensive Benefits of DevOps and DataOps Adoption

5. Navigating Implementation Challenges and Anti-Patterns
While the benefits of DevOps and DataOps are compelling, their successful implementation is not without significant challenges and the need to avoid common anti-patterns. Addressing these obstacles proactively is crucial for realizing the full potential of these methodologies.
Common DevOps Challenges
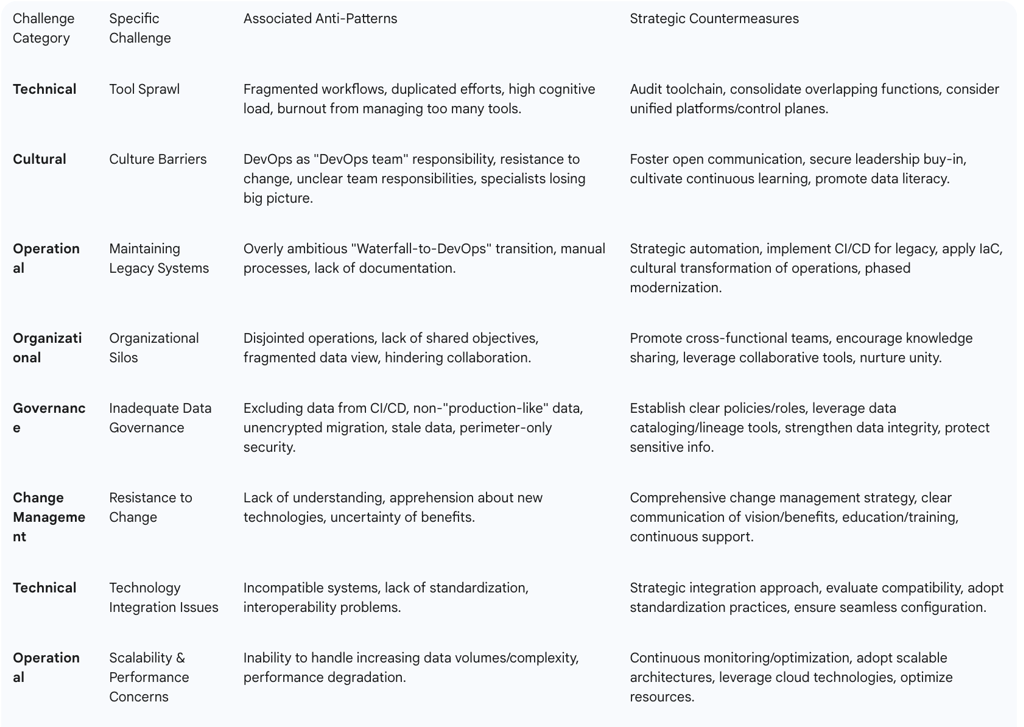
One prevalent challenge is tool overload, where managing a proliferation of disparate tools across the CI/CD pipeline becomes overwhelming. This often leads to inefficiencies, increased costs, and fragmented workflows. This situation frequently arises from prioritizing short-term fixes by adding new tools for immediate pain points, which, over time, accumulates into duplicated efforts, siloed data, and a high cognitive load for engineers, ultimately leading to slower incident response, reduced focus, and burnout. The observation that tool sprawl leads to cognitive overload and reduced productivity indicates that simply acquiring more "best-of-breed" tools without a strategic integration or consolidation plan is counterproductive. The complexity introduced by managing disparate tools negates the very efficiency and speed that DevOps aims to achieve, transforming a supposed enabler into a significant impediment.
Cultural barriers represent another substantial hurdle. Aligning traditionally separate development and operations teams is challenging due to inherent differences in mindset, workflow, and priorities. Resistance to change, especially when transitioning from established legacy systems and processes, is a significant obstacle. Common anti-patterns include the misconception that DevOps is solely the responsibility of a dedicated "DevOps team" rather than a shared organizational culture. Other pitfalls involve a failure to deploy code to production due to poor integration or communication between teams , team members lacking clear scopes of responsibility, leading to interference or incompatible decisions , specialists losing sight of the broader ecosystem while focusing only on their individual tasks , and a pervasive lack of proper documentation or the prevalence of manual, undocumented changes.
Finally, maintaining legacy systems while simultaneously implementing new DevOps practices is often a complex and time-consuming endeavor. A common anti-pattern in this context is being overly ambitious and attempting a direct, large-scale "Waterfall-to-DevOps" transition, which many organizations find difficult to handle effectively.
Common DataOps Challenges
Organizational silos severely impede the seamless flow of information, ideas, and strategies, directly hindering the collaborative spirit essential for DataOps. This results in disjointed operations, a lack of shared objectives, and a fragmented view of data, making it difficult to derive meaningful insights.
Inadequate data governance mechanisms can lead to a myriad of problems, including data inconsistencies, significant security vulnerabilities, and critical compliance issues. Associated anti-patterns include excluding data from existing DevOps or CI/CD methods, treating data as a separate concern. Other issues arise from provisioning non-"production-like" data for testing, which restricts thorough system exercise and can lead to missed bugs. Migrating data without proper encryption or masking leaves it vulnerable. Allowing data to become stale prevents accurate AI learning and effective testing. Furthermore, relying solely on perimeter information security can leave non-production environments—which often contain copies of production data—unprotected. While the term "data debt" is mentioned as a challenge without explicit definition , the DataOps anti-patterns described provide strong indicators of its nature. Anti-patterns such as "allowing Data to become stale," "provisioning of non 'production-like' data," and "migrating Data without encrypting (or masking)" directly reflect accumulated issues in data pipelines and assets due to past shortcuts, neglect, or insufficient investment. This parallels the concept of "technical debt" in software development, where poor design or quick fixes in the past lead to increased costs and reduced agility in the future. Data debt, similarly, slows down data initiatives, increases operational risk, and diminishes the value derived from data assets over time. Organizations must proactively recognize and address data debt by adopting DataOps practices. This involves not only implementing automation and quality checks but also investing in proper data governance and security from the outset. Failure to manage data debt will result in increasingly complex, unreliable, and costly data operations, ultimately hindering the organization's ability to innovate and make informed decisions.
Resistance to change is another common obstacle. Implementing DataOps often encounters resistance, stemming from a lack of understanding, apprehension about new technologies, or uncertainty regarding the perceived benefits. Effectively managing this resistance is crucial for a smooth transition.
Technology integration issues pose a daunting task, particularly when integrating various disparate technologies, tools, and platforms. Challenges include incompatible systems, a lack of standardization, and interoperability issues, all of which can hinder the smooth functioning of DataOps processes.
Finally, scalability and performance concerns represent a critical ongoing challenge. As organizations grapple with ever-increasing volumes of data and complex analytics, ensuring that DataOps processes remain scalable and performant requires continuous monitoring and optimization.
Strategies for Overcoming Obstacles and Avoiding Anti-Patterns
Overcoming the challenges and avoiding anti-patterns in DevOps and DataOps implementation requires a multifaceted and strategic approach, addressing both cultural and technical dimensions.
Cultural Transformation
To foster a conducive environment, organizations must cultivate open communication and collaboration. This involves actively encouraging the transparent sharing of information, ideas, and strategies across all teams and departments. Promoting the formation of cross-functional teams and encouraging knowledge sharing through various mechanisms are also vital steps.
Securing leadership commitment is crucial for driving organizational change. Leaders must champion DevOps and DataOps initiatives by clearly articulating their vision and the tangible benefits—such as faster time to market, improved quality, reduced costs, and enhanced customer satisfaction—to secure commitment from all levels of the organization. It is also essential to cultivate a culture of continuous learning and experimentation. This means creating a safe environment where failure is viewed as an opportunity to learn and grow, fostering a "blameless retrospective" approach. Providing ample opportunities for continuous training and skill development in new tools and methodologies is also key. Furthermore, organizations should promote data literacy and accessibility by implementing comprehensive training programs to equip employees with the skills to interpret and use data effectively. Dismantling data silos to ensure shared access to information is critical for fostering collaboration and informed decision-making.
Process and Technical Refinement
For effective implementation, it is advisable to start small and iterate. Organizations should begin the adoption journey with pilot teams or specific projects to experiment, identify effective strategies, and refine processes before attempting to scale across the entire organization. A gradual transition from traditional methodologies, such as Waterfall, to Agile-like approaches is recommended before attempting full DevOps implementation. It is crucial to automate everything possible, identifying and automating repetitive and time-consuming tasks across both software and data lifecycles. This includes CI/CD pipelines, Infrastructure as Code (IaC), configuration management, container orchestration, and monitoring/logging. Organizations must prioritize security and testing by embedding security checks and rigorous testing from the early stages of development and data pipeline creation (a "shift-left" approach) to proactively catch issues. Implementing robust data governance is non-negotiable, requiring the establishment of clear policies, roles, and responsibilities for data management, quality, privacy, and security. Leveraging technologies for data cataloging, lineage tracking, and automated quality checks is also essential. A strategic approach to technology integration is necessary, involving the evaluation of compatibility and the implementation of standardization practices (e.g., consistent data formats, APIs) to improve interoperability and ensure seamless configuration. For scalability, continuous monitoring of data workflows and infrastructures is vital to meet evolving demands, leveraging scalable architectures and cloud technologies to ensure robustness and agility. Finally, organizations must actively address tool sprawl by regularly auditing their toolchain, identifying and removing overlapping functionalities, and consolidating where possible. Considering unified control planes or integrated platforms can streamline workflows and reduce cognitive overhead.
Legacy System Modernization
When dealing with legacy systems, a DevOps-driven approach emphasizes strategic automation of manual processes, particularly testing, deployment, and monitoring, to improve efficiency and reliability. Implementing CI/CD for legacy components helps achieve high velocity in developing and deploying changes to modernized parts of the system. Applying IaC for infrastructure supporting legacy applications ensures consistency and reproducibility. Acknowledging that legacy modernization is also a cultural transformation of operations is key, as DevOps principles help bridge the gap between development and operations teams during this transition. Finally, adopting
phased modernization approaches involves evaluating existing legacy systems, defining specific problems, and choosing appropriate strategies (e.g., retain, rehost, replatform, refactor, rearchitect, rebuild) based on factors like cost, risk, and future growth potential.
The comprehensive strategies for overcoming challenges consistently demonstrate that neither purely technical solutions nor purely cultural interventions are sufficient in isolation. For instance, tool sprawl, a technical challenge, is often exacerbated by a lack of strategic alignment or a "short-term wins" mindset. Similarly, modernizing legacy systems, while technical, requires a significant shift in operational models and team mindsets to be effective. The solutions presented intertwine leadership commitment, communication, and a learning culture with automation, governance frameworks, and integrated tooling. A successful and sustainable transformation with DevOps and DataOps demands a holistic approach that simultaneously addresses both the human (cultural, organizational) and technological aspects. Neglecting either dimension will significantly undermine the effectiveness of implementation efforts and prevent the realization of full benefits. Strong change management strategies are therefore paramount.
Table 4 summarizes common challenges, associated anti-patterns, and strategic countermeasures for DevOps and DataOps implementation.
Table 4: Common Challenges and Strategic Countermeasures
Essential Tools and Technologies for DevOps and DataOps Ecosystems
The successful implementation of DevOps and DataOps relies heavily on a robust ecosystem of tools and technologies that automate processes, enhance collaboration, and provide critical visibility. These tools span various categories, supporting different phases of the software and data lifecycles.
Key DevOps Tool Categories and Examples
DevOps tools are specifically designed to automate manual tasks and manage complex environments, enabling engineers to work efficiently and scale operations effectively.
CI/CD Systems: These platforms automate the build, test, and deployment processes, forming the backbone of rapid software delivery. Prominent examples include Jenkins, an open-source and extensible CI server that evolved into a full-featured CD platform; CircleCI, known for its automated testing and pipelines; GitLab CI/CD, which offers integrated source code management; Azure Pipelines, providing CI/CD capabilities across various platforms, languages, and cloud services; CloudBees, an integrated DevSecOps platform; Harness; and Octopus Deploy, which simplifies complex software deployments across diverse environments.
Infrastructure as Code (IaC): These tools enable the definition and management of infrastructure using code, ensuring consistency and repeatability. Key examples include Terraform, an open-source tool for provisioning infrastructure; CloudFormation, specifically for Amazon Web Services (AWS) environments; and Pulumi.
Configuration Management: These tools automate software installation, server and network configuration, and user management. Popular choices include Puppet, Chef, Ansible, and SaltStack.
Containerization & Orchestration: These technologies are used for packaging and deploying applications in isolated environments. Docker is a prominent containerization platform, while Kubernetes and Docker Swarm are leading tools for container orchestration, managing the architecture, configuration, provisioning, deployment, and management of containerized applications.
Monitoring and Logging: These solutions are critical for collecting metrics, generating alerts, and analyzing logs to gain deep visibility into IT infrastructure and application performance. Examples include Sematext Monitoring/Logs, Prometheus, Datadog, the ELK Stack (Elasticsearch, Logstash, Kibana), and Splunk.
Build Tools: These tools automate the software build process. Examples include Apache Ant, Maven, and Gradle.
Artifact Repositories: These solutions serve as centralized repositories for binary data, ensuring stability of builds by reducing dependency on external repositories. JFrog Artifactory and Sonatype Nexus are widely used.
Incident, Change, and Problem Tracking Software: Tools that facilitate team collaboration and work management, essential for tracking issues and project progress. Asana and Jira are common examples.
Key DataOps Tool Categories and Examples
DataOps platforms act as command centers, orchestrating people, processes, and technology to deliver a trusted data pipeline to users. They integrate various data management software into a unified environment.
Automation & Orchestration: These tools are crucial for automating machine learning workflows and managing complex data flows. Examples include Apache Airflow, Kubeflow, MLflow, Composable.ai (an Analytics-as-a-Service platform), and DataKitchen (for DataOps orchestration).
Data Quality Monitoring: Tools and frameworks for continuous testing across pipelines to validate data quality metrics like completeness, accuracy, and consistency. RightData provides practical services for data testing, reconciliation, and validation.
Data Governance: Tools that operationalize data governance by automating lineage tracking, metadata management, access controls, and audit logs. K2View focuses on making customer data accessible for analytics while adhering to security.
Data Version Control: Systems like lakeFS are used to track changes and data transformations for data artifacts, similar to code version control.
Data Integration & Transformation: Tools for managing real-time data flow and automating data preparation. Examples include Apache NiFi, Azure Data Factory (for hybrid data integration), HighByte (for industrial data integration), StreamSets (for real-time data movement), and Alteryx (for data prep automation with a drag-and-drop interface).
DataOps Platforms: Integrated suites that unify development and operations in data workflows, providing flexibility to support various tools. Notable platforms include Databricks Data Intelligence Platform (excelling in large-scale data analytics), 5X (easiest to use), Hightouch (best free software), and Tengu (a low-code DataOps tool). The AWS DataOps Development Kit is also an open-source framework for building data workflows on AWS.
Conclusion: The Path Forward for Digital Leadership
The analysis underscores that DevOps and DataOps are not merely buzzwords but foundational methodologies critical for modern enterprises seeking to accelerate software delivery and foster data-driven innovation. While distinct in their primary focus—DevOps on software development and DataOps on data analytics—their shared philosophical roots in Agile and Lean principles, coupled with their emphasis on collaboration, automation, and continuous improvement, make their integrated adoption a powerful strategic imperative.
The report highlights that DataOps can be viewed as a natural extension of DevOps principles applied to the data lifecycle. This means organizations already invested in DevOps have a significant advantage, as the cultural and procedural foundations are largely transferable. The combined approach creates a holistic management framework that ensures both robust software applications and reliable, high-quality data to fuel them. This synergy is essential for advanced capabilities like AI-powered applications and real-time analytics, where the performance of software is intrinsically linked to the integrity and availability of data.
The benefits of this integrated approach are multifaceted and profound. Organizations can expect accelerated time-to-market for both software products and data-driven insights, leading to enhanced business agility. Quality and reliability are no longer afterthoughts but are continuously built into processes, resulting in more stable systems and trustworthy data. Operational efficiency and scalability are significantly improved through extensive automation, enabling organizations to manage growing complexity and data volumes without proportional increases in manual effort. Furthermore, the embedded security and governance practices transform compliance from a reactive burden to a proactive, "security by design" capability. Perhaps most crucially, the adoption of DevOps and DataOps fosters a profound cultural transformation, breaking down silos and cultivating an environment of open communication, shared responsibility, continuous learning, and innovation. This cultural shift is arguably the ultimate differentiator, enabling sustained adaptability and leadership in dynamic markets.
However, the path to successful implementation is not without its challenges. Organizations must proactively address common obstacles such as tool sprawl, cultural resistance, and the complexities of modernizing legacy systems. Anti-patterns, like viewing DevOps as a standalone team's responsibility or neglecting data governance in non-production environments, must be identified and systematically countered. Overcoming these challenges requires a holistic strategy that simultaneously addresses both the human (cultural, organizational) and technological aspects.
For organizations aspiring to champion these practices and secure their position as digital leaders, several actionable recommendations emerge:
Prioritize Cultural Transformation and Leadership Commitment: Recognize that these methodologies represent a fundamental shift in how work is done. Secure unwavering support from senior leadership to champion the vision, articulate the benefits, and actively foster a culture of collaboration, psychological safety, and continuous learning across all teams.
Adopt an Iterative, Data-Driven Implementation: Begin with pilot projects to experiment and refine processes, gradually scaling successful practices. Utilize data-driven metrics to track progress, identify bottlenecks, and inform continuous improvements, rather than attempting a monolithic, "big bang" transition.
Invest Strategically in Integrated Tooling and Automation: Embrace automation as a core enabler for scalability and efficiency across both software and data pipelines. Actively manage tool sprawl by auditing existing toolchains, consolidating redundant functionalities, and considering unified platforms or control planes that streamline workflows and reduce cognitive overhead.
Embed Security and Governance from the Outset: Shift from reactive security and compliance audits to a proactive, "security by design" approach. Integrate automated security checks into CI/CD pipelines (DevSecOps) and establish robust data governance frameworks that ensure data quality, privacy, and lineage from ingestion to consumption.
Foster Continuous Learning and Cross-Functional Collaboration: Provide ongoing training and development opportunities for all team members to adapt to new tools and methodologies. Actively break down organizational silos by promoting cross-functional teams, shared objectives, and transparent communication channels.
Proactively Address Data Debt and Legacy System Modernization: Recognize that accumulated issues in data pipelines (data debt) and outdated legacy systems can significantly hinder agility. Implement structured strategies for modernizing these components, leveraging automation and iterative approaches to mitigate risks and unlock value.
FAQ
What are DevOps and DataOps, and how do they relate to each other?
DevOps is a collaborative methodology that integrates software development and IT operations teams to automate and streamline the software development lifecycle. Its main goal is to accelerate the delivery of high-quality software through increased efficiency and velocity. DataOps, on the other hand, is a complementary set of collaborative data management practices specifically designed to accelerate data delivery, uphold data quality, and maximise value from an organisation's data assets. It optimises the entire data lifecycle, from ingestion to delivery, ensuring real-time data availability and strengthening teamwork.
DataOps is explicitly modelled after DevOps practices, extending its principles of collaboration, automation, continuous improvement, and observability to the data domain. Both methodologies are rooted in Agile and Lean principles, focusing on iterative development and continuous feedback. While DevOps centres on the software development lifecycle, and DataOps on the data analytics pipeline, their combined adoption creates a holistic framework for managing both software and data-driven processes. This synergy is crucial for modern applications, especially those powered by AI/ML, where continuous software uptime and data accuracy are paramount.
What are the core principles and best practices of DevOps?
DevOps is underpinned by several core principles and best practices aimed at enhancing the speed, quality, and reliability of software delivery:
Collaboration and Shared Responsibility: This is the most fundamental requirement, fostering an environment where development and operations teams work together with shared objectives and continuous feedback. This dismantles traditional silos and builds trust.
Continuous Integration and Continuous Delivery (CI/CD): Automation is central here. Continuous Integration (CI) involves frequently checking code changes into a central repository, with rapid validation and feedback. Continuous Delivery (CD) (or Continuous Deployment, if fully automated) rapidly deploys validated changes to production, often after automated testing. This "shift-left" approach identifies issues early.
Security-First (DevSecOps): Security practices are integrated directly into DevOps pipelines from the outset. This includes robust secrets management, automated security checks (e.g., static analysis), and end-to-end encryption. CI/CD pipelines automate regular security checks for both application and infrastructure files.
Infrastructure as Code (IaC): This principle defines and manages infrastructure using code, making it version-controlled, repeatable, and consistent across environments. Tools like Terraform and CloudFormation are used to provision resources declaratively, reducing manual errors and ensuring uniformity.
Continuous Monitoring and Observability: This provides deep control over system performance and actionable insights, reducing downtime and enhancing reliability. Key metrics like deployment frequency and mean time to recovery (MTTR) guide improvements. Unified dashboards consolidate data for a transparent view of system health, enabling continuous optimisation through feedback loops.
What are the core principles and best practices of DataOps?
DataOps extends Agile and Lean principles to data management and analytics, ensuring data quality, streamlining pipelines, and fostering collaboration:
Data Quality Management and Validation: This is a central pillar, ensuring data is accurate, complete, and relevant for analysis. It involves automated abnormality detection ("jidoka") and continuous feedback ("poka-yoke") to prevent errors. Rigorous quality tests are implemented at each pipeline stage, utilising techniques like data profiling and schema validation. Key metrics include data freshness, distribution, volume, schema, and lineage.
Automated Data Pipelines and CI/CD for Data: Automation is crucial for streamlining operations, reducing manual errors, and managing big data complexity. CI/CD procedures are applied to data pipelines, allowing rapid testing and improvements. Tools like Apache Airflow automate repetitive processes like data extraction, transformation, and loading (ETL), orchestrating complex data workflows.
Data Governance and Security: This ensures data is protected against unauthorised access and used in accordance with policies and regulations. Governance processes define accountability, regulate access, and meticulously track data origins and transformations (lineage), providing transparency. This proactive, integrated approach embeds compliance into the data lifecycle.
Data Version Control and Reproducibility: DataOps systematically uses version control for data artefacts and transformations, mirroring software practices. The principle of "make it reproducible" ensures analytical results can be consistently recreated. "Disposable environments" allow for easy provisioning and de-provisioning of technical environments for experimentation, keeping costs low.
Continuous Improvement and Customer-Centricity: DataOps is an ongoing process of evaluating and adjusting data pipelines for performance and scalability. It prioritises providing high value to the customer through the quick and continuous delivery of data insights. This involves actively soliciting feedback and adapting swiftly to evolving customer needs, fostering a culture of continuous learning and reflection.
What are the strategic benefits of integrating DevOps and DataOps?
Integrating DevOps and DataOps offers significant strategic benefits for modern enterprises:
Accelerated Time-to-Market for Software and Insights: DevOps speeds up software releases, and DataOps accelerates access to and analysis of data. Their combination leads to quicker releases of applications alongside faster, more reliable insights, enabling organisations to respond rapidly to dynamic business needs and leverage data-driven decisions.
Enhanced Reliability and Quality Across Applications and Data: DevOps improves application stability and reduces bugs, while DataOps ensures high data quality, accuracy, and reliability. The integration means DataOps fuels applications with trustworthy data, and DevOps ensures the software itself is stable and available, creating a dependable digital ecosystem where quality is continuously "built-in."
Improved Scalability and Operational Efficiency: DevOps allows systems to adapt to growing demands, optimising resource allocation. DataOps increases efficiency by automating repetitive tasks and scaling data operations for increasing volumes and complexity. Together, they streamline workflows, drastically reduce manual errors, and boost overall productivity, enabling sustainable growth without proportional increases in human effort.
Strengthened Security and Compliance Posture: DevOps integrates security practices (DevSecOps) throughout the pipeline, automating vulnerability checks. DataOps implements robust data governance frameworks to safeguard sensitive data and ensure regulatory adherence. The combined approach leads to a proactive, "security by design" philosophy, embedding protection and compliance into the very fabric of operations, reducing risks.
Fostering a Culture of Innovation and Collaboration: Both methodologies promote cross-functional collaboration, shared objectives, and continuous learning, actively dismantling organisational silos. They encourage experimentation and a "blameless retrospective" approach to failures, fostering a psychologically safe environment where innovation can thrive through collective intelligence and shared responsibility. This cultural transformation is a key differentiator for sustained adaptability and leadership.
What are the common challenges and anti-patterns encountered during DevOps and DataOps implementation?
Implementing DevOps and DataOps successfully can be hindered by several common challenges and anti-patterns:
Tool Sprawl: Managing a proliferation of disparate tools across the CI/CD pipeline becomes overwhelming, leading to inefficiencies, increased costs, fragmented workflows, and high cognitive load for engineers. This often results from short-term fixes rather than strategic integration.
Cultural Barriers: Aligning traditionally separate development and operations teams is challenging due to inherent differences in mindset, workflow, and priorities. Resistance to change, especially when transitioning from legacy systems, is common. Anti-patterns include viewing DevOps as solely a "DevOps team's" responsibility, poor communication between teams, unclear responsibilities, and a lack of proper documentation.
Maintaining Legacy Systems: Simultaneously implementing new DevOps practices while managing existing legacy systems is complex and time-consuming. An anti-pattern is attempting an overly ambitious, direct "Waterfall-to-DevOps" transition, which is often difficult to manage effectively.
Organisational Silos (DataOps): These severely impede the seamless flow of information and strategies, hindering the collaborative spirit essential for DataOps. This results in disjointed operations, a lack of shared objectives, and a fragmented view of data, making insights difficult to derive.
Inadequate Data Governance (DataOps): This leads to data inconsistencies, security vulnerabilities, and compliance issues. Anti-patterns include excluding data from existing CI/CD, using non-"production-like" data for testing, migrating data without encryption, allowing data to become stale, and relying solely on perimeter security, leading to "data debt."
Resistance to Change (DataOps): Implementation often encounters resistance due to a lack of understanding, apprehension about new technologies, or uncertainty regarding perceived benefits. Effectively managing this resistance is crucial.
Technology Integration Issues (DataOps): Integrating various disparate technologies, tools, and platforms poses challenges, including incompatible systems, lack of standardisation, and interoperability problems, which hinder smooth DataOps processes.
Scalability and Performance Concerns (DataOps): As data volumes and analytical complexity increase, ensuring DataOps processes remain scalable and performant requires continuous monitoring and optimisation.
What strategies can organisations use to overcome implementation challenges and avoid anti-patterns?
Overcoming challenges and avoiding anti-patterns requires a multifaceted and strategic approach addressing both cultural and technical dimensions:
Cultural Transformation: Foster open communication and collaboration by encouraging transparent information sharing and forming cross-functional teams. Secure strong leadership commitment to champion the vision and articulate benefits. Cultivate a culture of continuous learning and experimentation, where failure is viewed as a learning opportunity ("blameless retrospective"). Promote data literacy and accessibility by dismantling data silos and providing training.
Process and Technical Refinement: Start small and iterate, beginning with pilot projects to experiment and refine processes before scaling. Automate everything possible, including CI/CD pipelines, Infrastructure as Code (IaC), and configuration management. Prioritise security and testing by embedding checks early ("shift-left"). Implement robust data governance with clear policies, roles, and responsibilities, leveraging tools for data cataloguing and lineage tracking. Adopt a strategic approach to technology integration, evaluating compatibility and standardising practices. Ensure scalability through continuous monitoring, scalable architectures, and cloud technologies. Actively address tool sprawl by auditing and consolidating overlapping functionalities.
Legacy System Modernisation: Employ a DevOps-driven approach, strategically automating manual processes like testing and deployment for legacy components. Implement CI/CD and IaC for supporting infrastructure. Recognise legacy modernisation as a cultural transformation, bridging dev and ops. Adopt phased modernisation approaches, evaluating existing systems and choosing appropriate strategies (e.g., rehost, refactor) based on cost, risk, and growth potential.
Which essential tools and technologies are vital for DevOps and DataOps ecosystems?
Both DevOps and DataOps rely on robust ecosystems of tools and technologies to automate processes, enhance collaboration, and provide visibility:
Key DevOps Tool Categories and Examples:
CI/CD Systems: Automate build, test, and deployment. Examples include Jenkins, CircleCI, GitLab CI/CD, Azure Pipelines, CloudBees, Harness, and Octopus Deploy.
Infrastructure as Code (IaC): Define and manage infrastructure as code. Examples include Terraform, CloudFormation (AWS), and Pulumi.
Configuration Management: Automate software installation and server/network configuration. Examples include Puppet, Chef, Ansible, and SaltStack.
Containerisation & Orchestration: Package and deploy applications in isolated environments and manage containerised applications. Examples include Docker (containerisation), and Kubernetes, Docker Swarm (orchestration).
Monitoring and Logging: Collect metrics, generate alerts, and analyse logs for system visibility. Examples include Sematext Monitoring/Logs, Prometheus, Datadog, ELK Stack, and Splunk.
Build Tools: Automate the software build process. Examples include Apache Ant, Maven, and Gradle.
Artifact Repositories: Centralised repositories for binary data. Examples include JFrog Artifactory and Sonatype Nexus.
Incident, Change, and Problem Tracking Software: Facilitate team collaboration and work management. Examples include Asana and Jira.
Key DataOps Tool Categories and Examples:
Automation & Orchestration: Automate machine learning workflows and complex data flows. Examples include Apache Airflow, Kubeflow, MLflow, Composable.ai, and DataKitchen.
Data Quality Monitoring: Tools for continuous testing and validation of data quality metrics. Example: RightData.
Data Governance: Operationalise data governance through lineage tracking, metadata management, and access controls. Example: K2View.
Data Version Control: Track changes and transformations for data artefacts. Example: lakeFS.
Data Integration & Transformation: Manage real-time data flow and automate data preparation. Examples include Apache NiFi, Azure Data Factory, HighByte, StreamSets, and Alteryx.
DataOps Platforms: Integrated suites unifying development and operations in data workflows. Examples include Databricks Data Intelligence Platform, 5X, Hightouch, Tengu, and AWS DataOps Development Kit.
What is the future outlook for organisations adopting integrated DevOps and DataOps?
The future outlook for organisations adopting integrated DevOps and DataOps is one of enhanced digital leadership and sustained competitive advantage. These methodologies are foundational for modern enterprises, allowing them to accelerate software delivery and foster data-driven innovation.
By creating a holistic management framework that ensures both robust software applications and reliable, high-quality data, organisations can achieve critical synergy. This integration is essential for advanced capabilities like AI-powered applications and real-time analytics, where software performance is intrinsically linked to data integrity.
Organisations can expect accelerated time-to-market for both software products and data-driven insights, leading to enhanced business agility. Quality and reliability will be continuously built into processes, resulting in more stable systems and trustworthy data. Operational efficiency and scalability will be significantly improved through extensive automation, enabling organisations to manage growing complexity and data volumes without proportional increases in manual effort. Furthermore, embedded security and governance practices will transform compliance from a reactive burden to a proactive, "security by design" capability.
Perhaps most crucially, adopting DevOps and DataOps fosters a profound cultural transformation, breaking down silos and cultivating an environment of open communication, shared responsibility, continuous learning, and innovation. This cultural shift is arguably the ultimate differentiator, enabling sustained adaptability and leadership in dynamic markets. Despite implementation challenges like tool sprawl and cultural resistance, proactive strategies addressing both human and technological aspects will lead to successful transformation and solidify an organisation's position in the competitive digital landscape.