4. The Next Frontier: Advanced Concepts and Emerging Trends
The landscape of data integration is continuously evolving, driven by the escalating complexity of data environments and the demand for more intelligent, agile, and automated solutions. Several advanced concepts and emerging trends are shaping this next frontier.
4.1. The Role of Artificial Intelligence (AI) and Machine Learning (ML) in Automating and Optimizing Integration
Artificial Intelligence (AI) and Machine Learning (ML) are increasingly being infused into data integration processes to enhance automation, efficiency, and intelligence. Their role spans multiple facets of the integration lifecycle:
Automation of Core Tasks: AI/ML algorithms can automate traditionally manual and time-consuming tasks such as data extraction, complex transformations, and loading (ETL). This includes intelligent pattern recognition in data to suggest or execute mappings and transformations, and automated metadata generation to describe data assets.
Enhanced Data Quality and Accuracy: AI can significantly improve data accuracy by automatically identifying and rectifying errors, inconsistencies, missing values, and duplicate records within datasets. ML models can learn data quality rules and apply them consistently.
Intelligent Data Mapping and Transformation: AI can assist in mapping data fields between source and target systems by learning from historical mappings and recognizing semantic similarities. It can also suggest or even generate transformation rules based on data patterns and business logic, reducing manual effort.
Optimization and Performance Tuning: ML can be used to analyze data pipeline performance, predict bottlenecks, and suggest or automate optimizations, such as dynamically allocating resources or reordering operations.
Augmented Capabilities: Industry analysts like Gartner highlight "augmentation"—the use of AI/ML to assist users—as a key capability for modern data integration tools. This includes features like AI-generated code for integration tasks, natural language querying for data discovery, and automated data classification. Google's BigQuery platform, for instance, incorporates AI-assisted capabilities to automate manual data management tasks and accelerate generative AI use cases. Forrester also points to the rise of AI-enabled data integration for automating functions like ingestion, classification, processing, and security.
Facilitating Real-time Insights: AI can enable more sophisticated real-time data integration and analysis, continuously learning from streaming data to provide timely insights or trigger automated actions.
As data volumes and the complexity of integration scenarios continue to grow, manual approaches become increasingly unsustainable. AI and ML offer the potential to scale data integration efforts, free up skilled data engineers from repetitive tasks to focus on higher-value activities, and accelerate the delivery of trusted, analysis-ready data.
However, the efficacy of AI in data integration is not without prerequisites. The performance of AI and ML algorithms is heavily dependent on the volume and quality of the data they are trained on—in this context, data about the integration processes themselves. Algorithms learn from past data mappings, transformation logic, encountered data quality issues, and their resolutions. Organizations that have mature, well-documented integration practices, rich metadata repositories, and a history of consistent data governance will find that their AI initiatives in data integration yield more significant benefits, and more quickly, than those with ad-hoc, poorly understood, or undocumented processes. This creates a scenario where organizations with strong data management foundations are better positioned to leverage AI, potentially widening the gap with less mature counterparts. Thus, foundational investments in metadata management and process documentation are crucial for unlocking the full potential of AI in this domain.
4.2. Data Fabric: Architecting for Agility and Unified Data Access
A data fabric is an architectural approach and an emerging set of technologies designed to address the challenges of increasingly distributed and diverse data landscapes. It focuses on automating data integration, data engineering, and data governance processes across an enterprise. A key characteristic of a data fabric is its use of "active metadata," often augmented by knowledge graphs, semantics, and machine learning, to continuously analyze various types of metadata (e.g., system logs, data dictionaries, usage patterns). This analysis is then used to discover patterns, infer relationships, and automate various aspects of the data lifecycle, including ingestion, integration, transformation, and delivery.
The overarching goal of a data fabric is to create a unified, intelligent, and flexible data layer that allows users and applications to find, access, query, and utilize data from multiple heterogeneous sources as if it were a single, cohesive resource, thereby reducing data silos. This is achieved without necessarily requiring all data to be physically moved to a central repository. Gartner has suggested that implementing data fabrics can lead to significant reductions in the time required for integration design, deployment, and ongoing maintenance.
Data fabric architectures aim to make data more findable, accessible, interoperable, and reusable (FAIR principles) across the enterprise, which is particularly crucial in today's hybrid and multi-cloud environments where data is often scattered.
The concept of "active metadata" is central to the functioning and intelligence of a data fabric. Unlike passive metadata, which primarily serves as a static description of data assets (e.g., data definitions in a catalog), active metadata is dynamic. It is continuously collected, augmented, analyzed, and used to drive actions and automate processes within the data ecosystem. For example, active metadata about data usage patterns could trigger automated optimizations of query plans or data placement strategies. Metadata about data lineage, when actively monitored, could automatically alert downstream systems or processes if a source schema changes. This "activeness," often powered by AI/ML, enables the data fabric to be adaptive, responsive, and intelligent, rather than a static collection of integration pipelines and data stores. It transforms metadata from a descriptive artifact into an operational component that orchestrates and optimizes data flows.
4.3. Data Mesh: Decentralizing Data Ownership and Fostering Data as a Product
Data mesh is a sociotechnical approach that proposes a paradigm shift from centralized data ownership and infrastructure to a decentralized model. In a data mesh architecture, the responsibility for data is distributed to domain-specific teams—teams that are closest to the data and have the deepest understanding of its context and business value.
Key principles of data mesh include:
Domain Ownership: Business domains (e.g., marketing, sales, finance, logistics) own their data, including its quality, governance, and lifecycle management.
Data as a Product: Data is treated as a product that domain teams create, maintain, and serve to other consumers (both human and automated) within the organization. These data products are designed to be discoverable, addressable, trustworthy, self-describing, interoperable, and secure.
Self-Serve Data Infrastructure as a Platform: A central platform team provides the underlying infrastructure, tools, and services that enable domain teams to easily build, deploy, and manage their data products.
Federated Computational Governance: A global governance model establishes enterprise-wide standards, policies, and interoperability protocols, while allowing domains to implement these standards in a way that suits their specific needs. This ensures a balance between domain autonomy and global consistency.
The primary motivation behind data mesh is to overcome the bottlenecks and scalability limitations often associated with centralized data teams and monolithic data platforms in large, complex organizations. By empowering domains to manage their own data, data mesh aims to increase agility, improve data quality (as domain experts are responsible), and foster a stronger sense of data ownership and accountability throughout the business.
Implementing a data mesh is as much an organizational and cultural transformation as it is a technical one. It requires a fundamental shift in how data is perceived and managed—moving from viewing data as a technical asset managed primarily by a central IT or data team, to considering it a valuable product owned and curated by the business domains that create and understand it best. This necessitates the development of new roles and responsibilities within domain teams (e.g., data product owners), a higher degree of data literacy across the organization, and new models for collaboration between domain teams and the central data platform team. Without this cultural shift and the associated changes in organizational structure and incentives, a data mesh initiative is unlikely to succeed, regardless of the technology implemented.
4.4. Synergies and Differences: Data Fabric vs. Data Mesh in an Integration Context
While data fabric and data mesh are distinct concepts, they are not mutually exclusive and can be complementary within a broader data strategy.
Core Focus: A data fabric primarily focuses on creating a unified and automated data integration and management layer across disparate systems, often leveraging metadata and AI to achieve this. Its emphasis is on technological capabilities to connect and make data accessible intelligently. A data mesh, conversely, is more focused on the organizational and ownership aspects, decentralizing data responsibility to business domains and treating data as a product.
Relationship: A data fabric can provide some of the underlying technological infrastructure and integration capabilities that support a data mesh implementation. For example, the automated data discovery, integration pipelines, and metadata management services of a data fabric can help domain teams create and serve their data products more effectively. The metadata-driven approach of a data fabric is particularly helpful in creating and managing the data products that are central to a data mesh.
Data Management Approach: Data fabric tends towards a more centralized or logically centralized view of data management and governance, even if data remains physically distributed. Data mesh explicitly advocates for decentralized data ownership and federated governance.
Governance: Governance in a data fabric is often centrally defined and enforced through the fabric's capabilities. In a data mesh, governance is federated, with global standards set centrally but implemented and adapted by individual domains. A blended approach is possible, where a data fabric enforces overarching enterprise-wide compliance policies, while domain-specific policies are managed within the mesh structure.
Understanding how these two paradigms can coexist is crucial. A data fabric can act as the technological enabler for the data products that form the nodes of a data mesh. For instance, the fabric's automated integration services could be used by domain teams to ingest and prepare data for their data products, and its unified catalog could serve as the discovery mechanism for these products.
The interplay between data fabric and data mesh offers a pathway to a 'federated data ecosystem.' In such an ecosystem, the data fabric could provide the 'interconnectivity fabric'—common infrastructure, shared services like a universal data catalog, automated data quality checks, and consistent security enforcement. The data mesh, then, would define the 'domain-specific products and ownership' that leverage this fabric. This model allows for centralized efficiencies and standards provided by the fabric, combined with the decentralized agility and domain expertise fostered by the mesh. This potentially resolves the long-standing tension in data management between complete centralization (which can lead to bottlenecks) and complete decentralization (which can lead to chaos and silos). By strategically combining these approaches, organizations can aim for the best of both worlds: a system that is both centrally governed and enabled, yet locally agile and owned by those closest to the data.
5. Strategic Pathways: Selecting and Implementing Data Integration Technologies
The selection and implementation of data integration technologies are critical decisions that can significantly impact an organization's ability to leverage its data assets. A strategic, well-considered approach is essential.
5.1. Aligning Technology Choices with Business Objectives and Data Strategy
The choice of data integration technologies should never be made in isolation or driven purely by technical preferences. Instead, it must be fundamentally aligned with clear business objectives and the organization's overarching data strategy. Before any architectural design or tool selection, it is imperative to define the specific business goals the integration efforts are intended to support. These could range from enabling real-time customer personalization, improving operational efficiency through automation, ensuring regulatory compliance, or empowering specific analytical initiatives like fraud detection or supply chain optimization.
A robust data integration strategy, born from these objectives, forms the foundation for building an architecture that can maintain data quality, ensure consistency, uphold governance standards, and ultimately facilitate data-driven decision-making. Forrester's research also emphasizes the importance of evaluating data integration technologies based on their potential business value and their maturity level within the market and the organization.
A common misstep in technology acquisition is the pursuit of "technology for technology's sake," where the allure of the newest or most advanced tool overshadows a pragmatic assessment of actual business needs. As advocated , a thorough understanding of current and future business requirements acts as a critical filter. This prevents over-engineering solutions that are unnecessarily complex or costly, and avoids selecting tools that, despite their advanced features, do not effectively address the core strategic priorities. This underscores the necessity for business analysts, data strategists, and key stakeholders from business units to be integral participants in the data integration technology selection process, working in close collaboration with IT and data architecture teams. Their input ensures that the chosen solutions are not only technically sound but also directly contribute to achieving desired business outcomes.
5.2. Key Considerations for Selection and Implementation
Beyond strategic alignment, several practical considerations should guide the selection and implementation of data integration technologies:
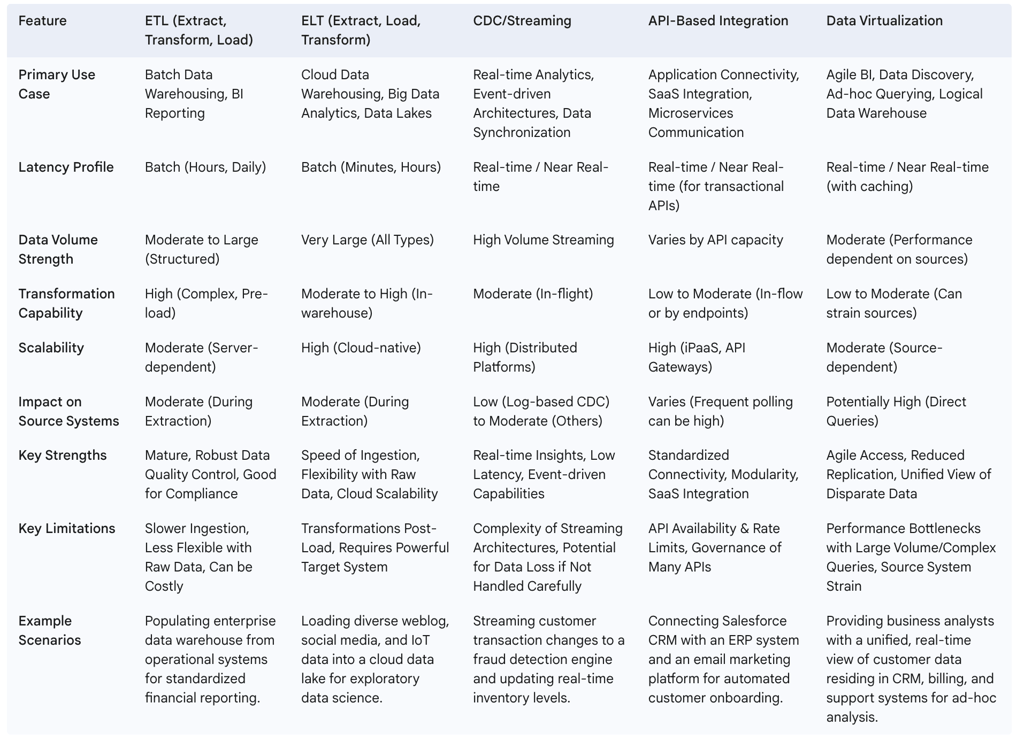
Data Characteristics: The nature of the data itself is a primary determinant. This includes its Volume (how much data), Velocity (how fast it arrives or changes), Variety (the range of data types and formats – structured, semi-structured, unstructured), Veracity (its accuracy and trustworthiness), and its Value to the business. For example, ETL is often suited for well-understood structured data requiring complex transformations, while ELT and streaming are better for high-volume, high-velocity, and varied data types.
Architectural Fit: The chosen technology must integrate seamlessly with the existing IT landscape, including legacy systems and modern applications. It should also align with the organization's cloud strategy (e.g., preference for cloud-native services, hybrid cloud deployments). Furthermore, consideration should be given to the future architectural vision, such as plans to adopt data fabric or data mesh paradigms.
Skillsets and Resources: The availability of internal personnel with the requisite expertise to implement, manage, and maintain the chosen tools and technologies is crucial. Some modern platforms offer low-code or no-code interfaces, aiming to empower "citizen integrators" with less technical backgrounds. Others, such as those requiring custom development in Spark for AWS Glue or intricate configurations, demand specialized data engineering skills.
Governance and Security Requirements: Stringent requirements for data quality, regulatory compliance (e.g., GDPR, HIPAA, CCPA), data lineage tracking, and security (encryption, access control, auditing) must be met. For instance, ETL's ability to perform transformations before loading data into a warehouse can be advantageous for ensuring compliance by masking or tokenizing sensitive data prior to its wider availability. Modern platforms increasingly incorporate features for robust governance and security.
Total Cost of Ownership (TCO): A comprehensive assessment of TCO should include not only initial software licensing or subscription fees but also costs related to infrastructure (hardware, cloud services), development and implementation effort, ongoing maintenance, operational overhead, and training.
Vendor Viability and Ecosystem: As highlighted by industry evaluation frameworks like Gartner's Magic Quadrant , the stability of the vendor, their market responsiveness, product vision, customer support, and the strength of their partner ecosystem are important factors for long-term success and risk mitigation.
The increasing prevalence of "low-code/no-code" data integration platforms is a direct market response to the persistent shortage of highly skilled data engineers and the relentless business demand for faster delivery of integration solutions. These platforms aim to empower a broader range of users, often termed "citizen integrators" or citizen technologists , to build and manage data pipelines. While this democratization of integration capabilities can accelerate development and foster innovation within business units, it also introduces a critical need for robust, centralized governance. Without appropriate oversight, policies, and technical guardrails provided by IT or a central data governance body, the proliferation of user-driven integrations can lead to "integration sprawl"—a chaotic landscape of redundant, inconsistent, insecure, or poorly performing data flows. Therefore, organizations embracing low-code/no-code integration must simultaneously invest in establishing strong governance frameworks to ensure data quality, security, and architectural coherence.
5.3. Building a Future-Ready Data Integration Architecture
A future-ready data integration architecture is one that is not only effective for current needs but also adaptable and scalable to meet the evolving demands of the business and the changing technological landscape. Key principles for building such an architecture include:
Prioritizing Real-time and Scalable Design: Modern business operations increasingly require real-time or near-real-time data. The architecture should be designed to handle streaming data efficiently and process it with low latency. Equally important is scalability, ensuring the architecture can accommodate growing data volumes, an increasing number of data sources, and more complex processing requirements without needing significant re-architecture.
Building a Modular, Cloud-Native Architecture: A modular design, where the integration process is broken down into smaller, independent, and reusable components (e.g., microservices-based approaches), enhances maintainability, flexibility, and the ability to update or replace individual components without disrupting the entire system. Leveraging cloud-native services and architectures further promotes scalability, elasticity, and cost-effectiveness. Modern architectures frequently utilize cloud platforms to break down traditional data silos.
Centralizing Data Governance and Ensuring Data Consistency: Data governance should be an integral part of the architectural design from the outset, not an afterthought. This involves establishing clear, centralized data governance policies (covering data ownership, access controls, privacy rules, quality standards, retention policies) and embedding mechanisms to enforce these policies throughout all data pipelines. Implementing robust data validation and cleansing processes is essential for ensuring data consistency across all systems and destinations.
Enabling Observability Across the Stack: Comprehensive observability—through logging, monitoring, alerting, and tracing—is critical for understanding the health, performance, and behavior of data integration pipelines. This provides visibility into data flows, helps identify bottlenecks or errors quickly, facilitates troubleshooting, and ensures the reliability and trustworthiness of the data being delivered.
Supporting Diverse Data Delivery Styles: As highlighted by Gartner, a modern integration platform should support a variety of data delivery styles, including batch, bulk, streaming, replication, synchronization, and virtualization, and allow these styles to be combined seamlessly.
Anticipating Hybrid and Multicloud Environments: Forrester anticipates a continued proliferation of data integration solutions designed to support insights across complex distributed environments, including hybrid cloud, multi-cloud, and edge computing scenarios.
The concept of "observability" in data integration pipelines is rapidly gaining importance, mirroring its criticality in application performance monitoring (APM) for software systems. As integration workflows become increasingly complex, distributed across various platforms (on-premises, multiple clouds), and operate in real-time, the ability to deeply monitor data flows, detect anomalies or deviations from expected behavior, trace data lineage accurately, and rapidly troubleshoot issues becomes paramount. This level of insight is essential for maintaining data trust, ensuring operational stability, and meeting service level objectives. The growing complexity and mission-critical nature of data pipelines, especially those feeding AI models or real-time decisioning systems , imply a corresponding need for investment in specialized monitoring, logging, and diagnostic tools specifically designed for the unique challenges of data pipeline observability.
6. Concluding Perspectives and Future Outlook
The field of data integration is characterized by dynamic evolution, driven by technological innovation and the ever-increasing strategic importance of data. Organizations must navigate this landscape with a forward-looking perspective to build resilient and effective data ecosystems.
6.1. The Evolving Data Integration Landscape
Data integration has journeyed far from its origins, which were heavily dominated by batch ETL processes for structured data warehousing. Today, it encompasses a diverse and sophisticated ecosystem of technologies and approaches. This includes the widespread adoption of cloud-centric ELT, the rise of real-time data streaming and Change Data Capture (CDC) for immediate insights, the ubiquity of API-based integration for connecting a sprawling digital world, and the agile access patterns offered by Data Virtualization.
Looking ahead, the landscape is being further reshaped by several key trends:
Continued Shift to Cloud-Native Solutions: The agility, scalability, and cost-effectiveness of cloud platforms are driving the adoption of cloud-native integration tools and services.
Emphasis on Real-Time Processing: The demand for instant data and immediate actionability is making real-time integration capabilities a standard expectation rather than a niche requirement.
Increased Automation through AI/ML: Artificial intelligence and machine learning are poised to automate many aspects of data integration, from pipeline generation to data quality management and optimization.
Growing Importance of Data Democratization and Self-Service: Tools and architectures are evolving to empower a broader range of users to access and work with data, reducing reliance on central IT teams.
Centrality of Metadata Management and Governance: As data environments become more complex and distributed, robust metadata management and comprehensive data governance are recognized as critical enablers for advanced architectures like data fabric and data mesh, as well as for effective AI implementation.
Emergence of Advanced Architectural Paradigms: Concepts like Data Fabric and Data Mesh are gaining traction as organizations seek more scalable, agile, and intelligent ways to manage and leverage their distributed data assets.
An interesting development in this evolving landscape is the blurring of lines between previously distinct data integration technologies. Many modern platforms now offer a suite of capabilities that span multiple traditional patterns. For example, a single data integration platform might provide robust support for both ETL and ELT processes, incorporate CDC connectors for real-time data capture, offer streaming data processing engines, and include API gateways for application integration. While this convergence offers organizations greater flexibility and the potential to consolidate their tooling, it also necessitates careful evaluation. It is important to scrutinize whether a "unified" platform truly excels in all the specific integration patterns critical to the organization's needs, or if it has particular strengths in some areas and relative weaknesses in others. Buyers must look beyond marketing claims to assess the depth, performance, and maturity of the specific capabilities they intend to use most heavily.
6.2. Preparing for an Interconnected, Data-Driven Future
To thrive in an increasingly interconnected and data-driven future, organizations must adopt a strategic and adaptable posture towards data integration. This involves more than just selecting the right tools; it requires a holistic approach that encompasses strategy, culture, and governance.
Key recommendations for organizations include:
Embrace Strategic Adaptability: Recognize that data integration is not a static field. Continuously evaluate evolving business needs, emerging technologies, and the effectiveness of current integration practices. Be prepared to adapt and evolve tools, techniques, and architectures as necessary.
Foster Data Literacy and Stewardship: As data becomes more democratized and decentralized models like data mesh gain traction, it is crucial to cultivate a strong data culture across the organization. This includes promoting data literacy among all employees and instilling a sense of data stewardship and accountability within business domains.
Invest in Foundational Governance and Metadata Management: Robust data governance frameworks and comprehensive metadata management are no longer optional extras but foundational pillars for any modern data integration strategy. They are essential for ensuring data quality, compliance, security, and for enabling advanced capabilities like AI-driven integration and architectures such as data fabric.
Ultimately, the future of data integration is not merely about connecting disparate systems more efficiently. It is about architecting a dynamic, intelligent, and accessible "data ecosystem" that empowers innovation, accelerates insights, and drives tangible business value. The technologies and methodologies discussed in this report are the enablers of this transformation. However, the true differentiation will come from how organizations strategically deploy these enablers, embedding data as an active, integral component of every decision, process, and customer interaction. This requires strong leadership with a clear vision for data as a strategic enterprise asset and a commitment to fostering a culture that can fully leverage its potential.