Continuous Integration, Unit Testing Tools in Data Engineering
This report examines the adaptation of CI/CD principles, the role of unit testing, and related practices within data engineering workflows. It delves into the unique challenges posed by data—such as large datasets, schema drift, and non-determinism—and presents strategic solutions and specialized tools designed to overcome these hurdles.


The modern data landscape necessitates robust methodologies to ensure data quality, reliability, and rapid delivery. Continuous Integration (CI) and Continuous Delivery/Deployment (CD) practices, originally foundational in software engineering, have become indispensable for data engineering. This report examines the adaptation of CI/CD principles, the role of unit testing, and related practices within data engineering workflows. It delves into the unique challenges posed by data—such as large datasets, schema drift, and non-determinism—and presents strategic solutions and specialized tools designed to overcome these hurdles. Through an exploration of comprehensive testing strategies and real-world case studies from leading technology companies, this analysis underscores how a disciplined approach to CI/CD and automated testing transforms data engineering from a manual, error-prone process into an automated, reliable, and scalable operation, ultimately enhancing data integrity and accelerating business value.
Bridging Software Engineering CI/CD with Data Engineering
1.1. Defining Continuous Integration and Continuous Delivery/Deployment (CI/CD)
Continuous Integration (CI) is a foundational practice in software development that involves developers frequently merging their code changes into a shared source code repository, often multiple times per day. This process is immediately followed by automated builds and tests to detect integration issues at an early stage. The primary objective of CI is to reduce risk by highlighting problems earlier in the software development lifecycle (SDLC) and minimizing code conflicts that can arise from infrequent merging.
Building upon CI, Continuous Delivery (CD) ensures that code changes, after successfully passing automated tests, are automatically prepared for release to a production-like environment, commonly referred to as a staging environment. While the code is consistently in a deployable state, actual deployment to production may still require manual approval. Extending this, Continuous Deployment (CD) takes automation a step further by automatically deploying all code changes that pass all tests directly to the production environment without any human intervention.
Collectively, a CI/CD pipeline represents an automated workflow that encompasses these stages, guiding software development through a structured path of building, testing, and deploying code. The overarching aim is to streamline and accelerate the software development lifecycle. This consistent emphasis on automation as the core of CI/CD directly leads to higher quality code, faster delivery, and reduced human error. The benefits explicitly include the development of "higher quality code, faster and more securely" and the ability for "errors to be found early and quickly corrected". This establishes a clear cause-and-effect relationship where automation enables early detection and rapid correction, which in turn improves overall quality and accelerates delivery. This is not merely a feature; it constitutes the fundamental purpose of CI/CD.
The CI/CD pipeline is also a direct reflection of the DevOps methodology, a set of ideas and practices that fosters collaboration between development and IT operations teams through extensive automation. The evolution from manual, error-prone deployments to automated CI/CD pipelines signifies a fundamental shift in software delivery. This transformation aims to eliminate the inherent uncertainty and potential disasters associated with manual release management, marking a necessary progression in managing complexity and risk across all development domains.
1.2. The Imperative for CI/CD in Data Engineering: Benefits and Unique Value
The principles of Continuous Integration and Continuous Delivery/Deployment, initially developed for traditional software engineering, are increasingly being applied to data engineering practices. This adaptation involves automating the testing, integration, and deployment of data processing code and the underlying infrastructure.
The core benefits derived from implementing CI/CD in data engineering are substantial:
Improved Data Integrity and Quality: Automated testing, a cornerstone of CI/CD, ensures that errors are identified and corrected early in the pipeline, thereby preserving high-quality data. Rigorous auditing, particularly through data-specific paradigms, guarantees that only verified and trustworthy data is released for consumption.
Enhanced Reliability and Consistency: CI/CD streamlines iteration cycles, ensures consistent code quality, and fosters enhanced collaboration among teams. This approach significantly reduces the risk of errors and improves the overall reliability of data systems. For example, Netflix reported a 92% reduction in production incidents and near-zero downtime for critical data flows after implementing CI/CD for their data pipelines.
Faster Iteration and Deployment: The automation inherent in CI/CD allows for frequent, small updates to data pipelines to be made with confidence. This can lead to dramatic reductions in deployment time, such as a major retail company reporting a drop from two days to just 30 minutes after adopting CI/CD.
Increased Efficiency and Productivity: By automating repetitive tasks, CI/CD frees data engineers to concentrate on more complex and value-adding activities. This also translates to a significant reduction in time spent on manual testing.
Better Collaboration and Visibility: CI/CD establishes a standardized development and deployment process that improves visibility, making it easier for teams to track changes, identify issues, and maintain comprehensive documentation.
Enhanced Security and Compliance: A structured CI/CD pipeline can incorporate security testing and audits, which are vital for preserving application and data security. Furthermore, by isolating audited and raw data, it prevents sensitive and unvalidated information from being prematurely exposed, which is crucial for maintaining security requirements and data compliance.
The application of CI/CD to data engineering holds unique value due to the specific characteristics of data. It orchestrates the smooth evolution of the entire data ecosystem, ensuring accuracy and efficiency in rapidly changing business environments. Data pipelines operate in dynamic, ever-changing environments where upstream dependencies, such as APIs, databases, and business logic, can shift without warning. This inherent volatility and non-deterministic nature of data, coupled with challenges like schema drift and the sheer volume of datasets, make CI/CD not just beneficial but essential for data engineering. It is arguably more critical than for traditional software development, where code changes are often the primary variable. The consistent emphasis on automation and early detection in CI/CD directly addresses the core instability inherent in data itself, making it a critical safeguard.
Moreover, the application of CI/CD principles to data engineering implicitly drives the adoption of "data as code" and "infrastructure as code" for data assets. This represents a broader trend towards treating all components of the data ecosystem—not just the processing logic, but also data schemas, infrastructure provisioning, and even data itself (through versioning)—with the same rigor as application code. This philosophical shift enables the full benefits of the CI/CD paradigm to be realized in data environments.
1.3. The Write-Audit-Publish (WAP) Paradigm in Data Pipelines
The Write-Audit-Publish (WAP) paradigm is a methodological pattern specifically designed to adapt CI/CD to the unique challenges of data engineering. It gives teams greater control over data quality by addressing the "data first" nature of data engineering, where the data itself, not just the code, requires validation before exposure. The main goal of WAP is to guarantee data reliability for users by verifying data after processing but before customer access.
The WAP approach unfolds in three distinct phases:
Write: In this initial step, the data being processed is placed in a format that is not yet accessible to customers. This typically involves writing the data to a temporary branch, a staging location, or another isolated area, ensuring it is prepared for subsequent validation.
Audit: Following the write phase, the data undergoes a rigorous audit to ensure that all data quality requirements are met. This is a crucial step for verifying correctness, completeness, and compliance with established standards. Any inconsistencies or abnormalities are identified and fixed during this phase, aligning directly with comprehensive data quality checks.
Publish: Once the data has been thoroughly verified through the audit process, it is published to the location where downstream users will read it. This makes the validated and trustworthy data available for consumption, ensuring that only high-quality data reaches end-users.
The benefits of implementing the WAP approach in CI/CD for data pipelines are manifold: it leads to improved data integrity and quality through rigorous examination of data for correctness, completeness, and compliance, ensuring only verified data sources are released into production. It enhances data security by isolating audited and raw data, preventing sensitive and unvalidated data from premature exposure, which is vital for maintaining security requirements and data compliance. Furthermore, the clear division of writing, auditing, and publishing phases enhances reliability by allowing for better error management and recovery procedures, making it easier to find and fix problems at every stage. Finally, the modular architecture of WAP patterns provides operational flexibility and scalability, allowing individual components to be changed, upgraded, or scaled independently without compromising the stability of the entire pipeline. This pattern ensures that code tests, including unit and integration tests, have data to run against by writing data to a buffer before running tests on it. Data contracts can also be integrated within this pattern to check data schema and quality.
2. Foundations of Unit Testing in Data Engineering
2.1. Core Principles and Scope of Unit Testing for Data Transformations
Unit testing in data engineering involves creating isolated tests that verify the correctness of individual components or "units" within data processing workflows. These units can range from a single SQL query, a data processing function written in Python, to a specific component of a larger data pipeline. The fundamental purpose of unit testing is to identify and fix errors early in the development cycle, thereby enhancing the quality of data products and facilitating agile development methodologies.
A foundational principle of unit testing is test isolation, which ensures that each test runs independently without affecting or being affected by other parts of the system. The scope of unit testing in data engineering extends to both the transformation logic (the code itself) and the data that is the output of these transformations or the source data being processed.
While unit testing is highly effective for validating code logic, its application to data transformations introduces critical nuances. It applies to both the transformation code and the data itself. The challenges highlighted in various discussions, such as handling malformed input data, dealing with missing input data, ensuring proper de-duplication, correctly inferring schema, and verifying idempotency (where re-runs produce the same output as a single run), indicate that data-centric unit tests require different considerations than purely code-centric ones. The dual focus on code and data is a key distinction from traditional software unit testing, where the "unit" is almost exclusively code.
There exists a nuanced discussion regarding the value of unit testing for transformations. Some perspectives suggest that painstakingly writing unit tests for simple "stupid mistakes" in transformations, such as accessing a missing column or calling a non-existent function, can be a "waste of time". This argument posits that for transformations operating on tables with many columns, much effort in unit testing goes into enumerating input and output columns rather than verifying business logic, potentially slowing down development. Instead, for such transformations, "integration" tests are often advocated, where the application runs in a simulated environment and results are checked against expectations for a given test case. However, other perspectives still include validating data transformation components as a core aspect of unit testing. This suggests that while the concept of unit testing is applied, the granularity and approach for complex data transformations might blur the lines between traditional unit and integration tests. The argument regarding "waste of time" points to the overhead of setting up isolated tests for simple code errors that might be better caught by integration tests with more realistic data.
2.2. Crafting Effective Test Cases and Managing Test Data
The creation of effective test cases in data engineering unit testing involves defining the inputs, executing the unit of data logic, and rigorously verifying the output against expected results. A thoughtful approach to selecting test data is paramount, as it must adequately cover the various scenarios the data logic may encounter, including critical edge cases.
Test data can be sourced in several ways: synthetic test data can be generated, or subsets of real data can be utilized. The use of mock data is particularly crucial for testing, as it allows for validation without affecting real production data or systems. For data unit tests, dummy data, such as CSV files containing various combinations of data values (including positive and negative scenarios), can be employed. When unit testing transformation functions, ensuring that the test has appropriate data to work with is critical. This can be achieved either by creating fake testing data based on the distribution and statistics of real data, or by replicating a sample of real data in development or staging environments.
A significant practical challenge in data engineering unit testing is the generation of representative and comprehensive test data. This task is notably more complex than simply mocking API responses in traditional software development, as it requires a deep understanding of data distributions, potential edge cases, and the sheer volume of data involved. This complexity often necessitates specialized tools or domain expertise to ensure the validity and coverage of tests. The ultimate goal of these meticulously crafted test cases and carefully managed test data is to catch errors early that could lead to data corruption, incorrect data analysis, or failures in downstream processes.
2.3. Seamless Integration of Unit Tests into CI/CD Workflows
Integrating unit tests into Continuous Integration/Continuous Deployment (CI/CD) pipelines automates the testing process, making it a seamless and integral part of the software development lifecycle. This automation is critical for maintaining the pace and quality of data engineering efforts.
Whenever new code is committed to the repository, the CI/CD system automatically triggers and runs the defined unit tests. This automated execution provides immediate feedback on the impact of the changes. The rapid notification of test failures helps development teams identify and resolve issues early in the development cycle, long before they can affect the production environment or end-users. This proactive approach significantly reduces the likelihood of errors, enhances overall data quality, and strongly supports agile development methodologies.
CI/CD pipelines are not merely a place to execute unit tests; they are the fundamental mechanism that makes unit testing truly effective in a dynamic data engineering environment. By enforcing frequent execution and providing rapid feedback, CI/CD ensures that unit tests remain relevant and are consistently run. Without this integration, unit tests can become stale, fall out of sync with evolving code, or be overlooked, diminishing their value. The automation provided by CI/CD transforms unit testing from an optional, manual step into an enforced, high-value practice that directly contributes to the reliability and integrity of data pipelines.
3. Comprehensive Testing Strategies for Data Pipelines
3.1. Beyond Unit Tests: Integration, End-to-End, and Data Quality Testing
Testing data pipelines is a multifaceted process that employs various strategies to ensure the overall health, performance, and reliability of data flows. While unit testing focuses on individual components, a comprehensive approach extends to cover interactions between components and the entire pipeline.
The primary types of testing for data pipelines include:
Unit Testing: As previously discussed, this verifies the functionality of individual components in isolation. Examples include testing the data ingestion component to ensure it correctly fetches data from the source, validating the data transformation component to confirm it applies the correct transformations, and checking the data loading component to verify it loads data into the target system accurately.
Integration Testing: This examines how different components interact with each other within the data pipeline. It is crucial for identifying issues that may arise when data flows from one component to another. In data pipelines, this specifically means testing interactions with external systems such as messaging queues or various data platforms during the extract and load stages.
End-to-End Testing: This comprehensive approach involves verifying the entire data pipeline from start to finish. It ensures that the pipeline functions correctly as a whole, from initial data ingestion to final data loading into the target system.
Beyond these primary types, a comprehensive testing strategy for data pipelines incorporates several specialized test categories:
Functional Tests: These validate whether the integration of all components performs as users would expect. They typically focus on happy paths and highly probable business scenarios, often using API endpoint or UI tests.
Source Tests: These are designed to ensure that ingested data is transported to the target platform without loss or truncation, thereby protecting data integrity. For instance, in a manufacturing context, a source test might validate the "freshness" of all source data, ensure columns are structured correctly, and are properly aligned with the row count.
Flow Tests: These validate live data for completeness, accuracy, and consistency based on the business scenario, once the data has been transformed and deployed into the data platform’s data mart layer. They involve testing one or many logical components with real data, ensuring no data loss, correct mappings, and checks for nulls, duplicates, and special characters.
Contract Tests: Once a table is deployed on the data platform’s data mart, a contract test ensures that the consumed columns are always present in the source table in the data mart layer. This test maintains consistency between the source table and the aggregated table, ensuring that consumers of a data product can continue to consume it after changes are made. The contract is between the consumer and provider of the data.
Effective data pipeline testing necessitates a layered approach, moving beyond simple unit tests to encompass integration, end-to-end, and specialized data quality, flow, and contract tests. This hierarchy addresses different levels of complexity and potential failure points unique to data movement and transformation. The complexity of data pipelines, involving various stages like ingestion, transformation, loading, storage, and interaction with external systems, demands a multi-tiered validation strategy to ensure reliability at every stage.
3.2. Distinguishing Technical vs. Business-Related Data Quality Checks
Data quality tests are essential for validating both source data, over which there is often limited control, and data that is the result of internal transformations. These tests can generally be divided into two main groups, each with distinct focuses and responsibilities.
Technical Data Quality Tests: These tests concentrate on the structural integrity and correctness of data from a technical perspective, ensuring that data adheres to predefined rules and constraints. They are primarily the responsibility of data engineers, who verify the correct operation of the data pipelines themselves. Examples of such tests include:
Uniqueness Test: Ensures no duplicate values exist in key fields, such as customer_id in a customers table.
Null Check: Verifies that fields intended to contain data are not NULL, for instance, the email column in a users table.
Data Type Validation: Confirms that data conforms to expected data types, such as dates or integers.
Range Check: Validates that numeric values fall within a specified range, like an age column being between 0 and 120.
Format Check: Checks if data follows a specific pattern or format, such as phone numbers.
Foreign Key Constraint Check: Ensures referential integrity by verifying that foreign key values exist in the referenced table.
Business-Related Data Quality Tests: These tests focus on the relevance and accuracy of data within the context of specific business rules and processes. They often fall under the purview of QA engineers or data stewards, as they require a strong understanding of business needs and continuous communication with data stakeholders and consumers. Examples include:
Completeness Check: Ensures all necessary data fields contain values, such as every product having a category.
Consistency Check: Validates that data is logically consistent both within and across datasets, for example, ensuring that a total amount matches the sum of item amounts.
Timeliness Check: Confirms that data is current and relevant, adhering to time-related constraints like delivery dates within expected time frames.
Accuracy Check: Ensures calculated values are correct, such as a sales amount equaling quantity multiplied by price.
Referential Integrity Check: Validates relationships between datasets, for instance, all orders having valid customer IDs.
Business Rule Validation: Ensures data adheres to specific business rules, such as discounts not exceeding a certain percentage.
The distinction between technical and business data quality tests highlights the necessity of cross-functional collaboration. Data engineers are responsible for the technical integrity of the data, while QA and business stakeholders define and validate its business relevance. This implies a shared responsibility model for data quality, where different organizational roles provide critical input into the data quality process, underscoring the collaborative nature of effective data governance.
The principle of "validate early, validate often" is paramount in data engineering. This approach emphasizes integrating validation checks throughout the entire data pipeline process rather than deferring them to final stages. This ensures that issues are detected and addressed as soon as they arise, minimizing the risk of propagating errors through the pipeline and significantly reducing the cost and effort required to fix them. This aligns with the 1:10:100 rule, which suggests that preventing poor data quality at the source costs $1 per record, remediation after creation costs $10, and doing nothing costs $100.
3.3. Key Dimensions of Data Quality and Measurable Metrics
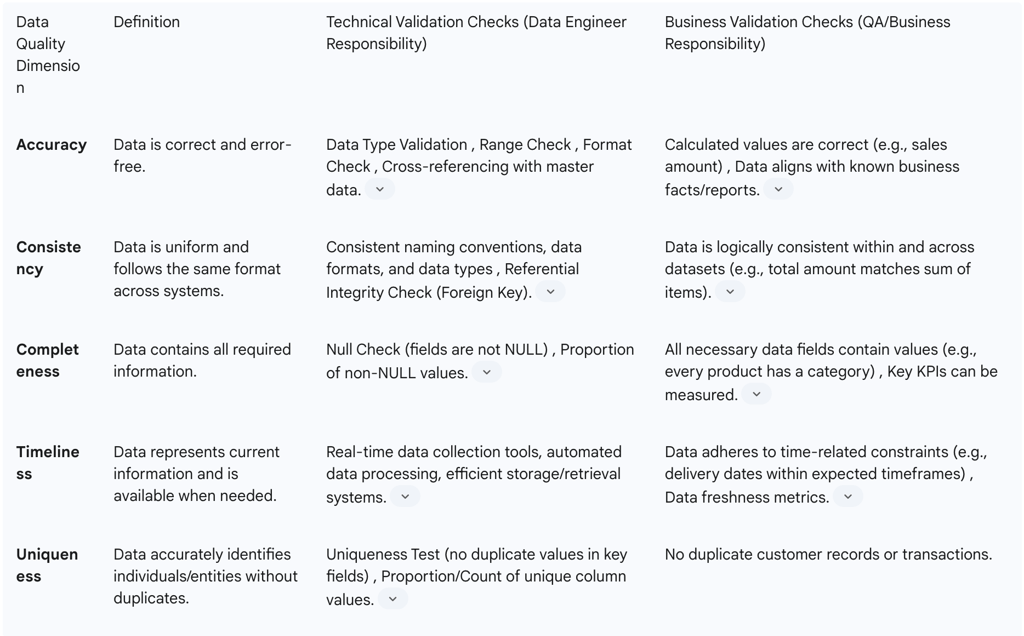
Data quality, often perceived as an abstract concept, is broken down into concrete, measurable dimensions. This provides an actionable framework for defining and monitoring data health, moving beyond subjective assessments. The five critical dimensions of data quality are:
Accuracy: This dimension refers to the extent to which data is correct and error-free. It is particularly crucial for sensitive data, such as financial or medical records, as inaccuracies can lead to severe consequences, including financial losses, legal issues, and reputational damage. Ensuring accuracy involves implementing proper data validation and verification processes, including automated error checks, manual reviews, and cross-referencing with external sources.
Consistency: This measures how uniform data is and whether it follows the same format across different systems and applications. Inconsistent data can cause confusion, errors, and inefficiencies. To ensure consistency, organizations should implement standardization processes, such as using consistent naming conventions, data formats, and data types, to make data easily understandable and usable across various systems.
Completeness: This refers to the extent to which data contains all the required information. Incomplete data can lead to incorrect conclusions and decisions with significant consequences. Key Performance Indicators (KPIs) can be used to measure data completeness, ensuring all necessary information is captured and aligned with business objectives. Proper data collection and storage processes are essential, including automated tools, manual reviews, and cross-referencing.
Timeliness: This dimension indicates the degree to which data represents current information and is available when needed. Outdated or delayed data can result in missed opportunities, incorrect decisions, and lost revenue. Achieving timeliness involves implementing real-time data collection tools, automating data processing, and using efficient data storage and retrieval systems.
Uniqueness: This refers to the extent to which data is unique and accurately identifies individuals, entities, or objects. Duplicate or inaccurate data can lead to confusion, errors, and inefficiencies. Ensuring uniqueness requires proper data validation and verification processes, such as automated duplicate checks, manual reviews, and cross-referencing with external sources.
A Data Quality Matrix is a valuable tool used to validate the degree to which data is accurate, complete, timely, and consistent with all requirements and business rules. It transforms data quality from a qualitative goal into a quantitative, monitorable objective, which is essential for automated validation within CI/CD pipelines. Examples of assertions and metrics within such a matrix include:
Proportion of column values that are not NULL.
Proportion of unique column values.
Count of unique column values.
Boolean indicator if all column values are unique.
Minimum column value.
Maximum column value.
Average column value.
Population standard deviation.
Sample standard deviation.
These specific, quantifiable metrics, when integrated into a data quality matrix, provide a robust framework for systematic data validation.
Table 2: Data Quality Dimensions and Associated Validation Checks
Essential Tools and Frameworks for Data Engineering CI/CD and Testing
4.1. Overview of General CI/CD Platforms
General CI/CD platforms automate the crucial build, test, and deployment phases of the software development lifecycle. These platforms are widely adopted across various industries and provide the backbone for continuous delivery.
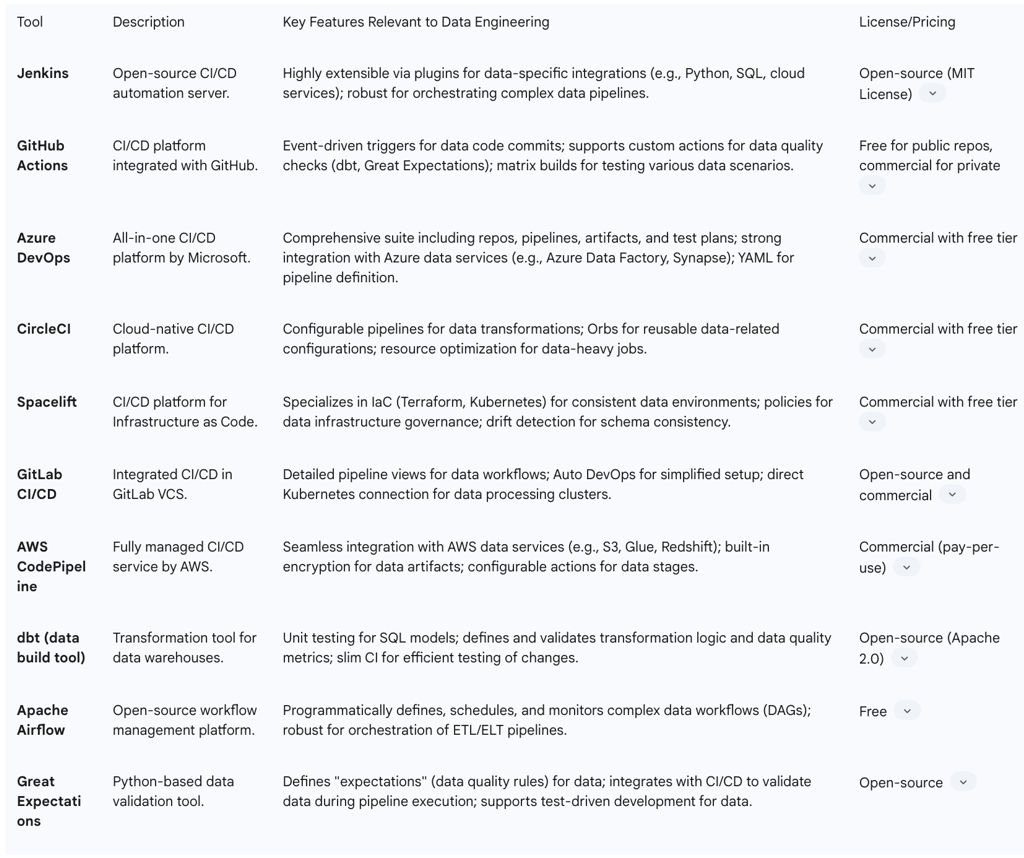
Several popular tools dominate this space:
Jenkins: A widely recognized open-source, extensible CI/CD automation server. It integrates with a diverse range of version control systems, cloud providers, and offers a rich plugin ecosystem. Netflix, a leader in streaming services, has integrated Jenkins into its pipeline to automate build and test processes, which significantly reduces testing time and provides faster feedback to developers.
GitHub Actions: A CI/CD platform embedded directly within GitHub repositories. It operates on an event-driven model, triggering tasks in response to GitHub events like pull requests. Its features include matrix builds, caching, and a marketplace of community-contributed actions. Teams using dbt often leverage GitHub Actions for CI checks on pull requests.
Azure DevOps: An all-in-one platform from Microsoft that encompasses the entire software delivery lifecycle. It includes Azure Repos for Git services, Azure Boards for tracking and planning, Azure Pipelines for CI/CD automation (supporting YAML syntax and integrating with any remote Git repository), Azure Artifacts for package management, and Azure Test Plans for testing and quality assurance.
CircleCI: A cloud-native CI/CD platform known for its configurability, extensive integrations, and performance optimization tools.
Spacelift: A flexible CI/CD platform that specializes in Infrastructure as Code (IaC) workflows, supporting tools like Terraform and Kubernetes. It offers robust VCS integration, policy enforcement at multiple decision levels, and drift detection capabilities.
Travis CI: A cloud-based CI service that integrates seamlessly with GitHub repositories, recognized for its simplicity and ease of setup.
GitLab CI/CD: An integrated feature of the GitLab Version Control System (VCS) platform, providing detailed pipeline views, an Auto DevOps feature for automatic CI/CD configuration, and direct Kubernetes connection.
AWS CodePipeline: A fully managed CI/CD service offered by Amazon Web Services that automates the build, test, and deployment phases and integrates seamlessly with other AWS services.
Bamboo (Atlassian): A CI/CD software tool that automates the management of software application releases.
Buildbot: A software development tool capable of automating every step of the development process.
Modern CI/CD platforms increasingly emphasize cloud-native capabilities and deep integration with Infrastructure as Code (IaC) tools. This reflects a broader industry trend towards immutable, reproducible environments. The ability to encapsulate application components and facilitate smooth integration through runtimes via containers like Docker, and the use of Kubernetes for orchestrating clusters, are crucial elements. Tools like Tekton, a Kubernetes-native framework, exemplify this shift, making it easier to deploy across multiple cloud providers or hybrid environments. This convergence indicates that CI/CD is no longer solely about code builds but about managing the entire environment consistently through code, ensuring consistency and reliability across development, testing, and production.
4.2. Specialized Tools for Data Transformation and Validation
The data engineering domain has seen the proliferation of specialized tools that address its unique challenges, moving beyond general-purpose CI/CD tools to purpose-built solutions for schema, quality, and volume.
Data Transformation Tools:
dbt (data build tool): A prominent tool that offers functionalities for unit testing on individual SQL models. It is widely used for defining and validating transformation logic and data quality metrics. dbt's "slim CI" jobs can be configured to test only models that contain changes, which significantly optimizes CI pipeline efficiency.
Apache Airflow, Luigi, Prefect: These are powerful tools designed for modular pipeline design and orchestration. Apache Airflow, in particular, is ideal for complex workflows that require custom scripting and integration with multiple systems, finding extensive use in industries such as finance and healthcare.
Talend: A comprehensive data integration platform that provides a full suite of tools for data integration, quality, and governance, including robust data transformation capabilities.
Datameer: This tool streamlines data preparation and transformation, particularly for environments like Snowflake, and automates data encoding for machine learning.
Informatica: A versatile data management platform that empowers users to execute crucial data quality operations such as deduplication, standardization, enrichment, and validation.
Alteryx: A powerful data preparation and analytics platform that enables users to uncover timely insights through intuitive workflow design and customizable data processing.
Data Validation and Quality Tools: The emergence of specialized tools like dbt, Great Expectations, and Deequ signifies the maturity of data engineering as a discipline. These tools are explicitly designed to address unique data challenges (e.g., schema, quality, volume) with purpose-built solutions.
dbt: (as mentioned above) is also a key tool for data quality, allowing for the definition and validation of data quality metrics.
Great Expectations: A Python-based tool that applies "Test Driven Development" to data pipelines, enabling users to define and validate "expectations" (data quality rules) for their data.
Deequ / PyDeequ: Developed by Amazon, these Apache Spark-based tools are designed for measuring data quality in large datasets, providing metrics, constraint checks, and fix suggestions.
Soda: An open-source tool for monitoring data quality and reliability, allowing users to define rules, detect issues, and alert on anomalies, providing data health metrics.
Numerous.ai: An AI-powered data validation tool specifically designed for spreadsheet users, capable of instantly detecting and correcting data inconsistencies.
PydanticAI: An AI-driven data validation library for Python developers, ensuring data used in APIs, databases, and machine learning models is validated and error-free.
ArtificioAI: An AI-powered data governance platform designed to help businesses validate, standardize, and ensure compliance across multiple data sources.
Apache Nifi: A powerful open-source data integration platform that focuses on data flow automation and management, offering data validation and cleansing features.
OpenRefine: Formerly Google Refine, this tool is used for cleaning messy data and transforming it between formats, making it easy to explore large, unstructured datasets.
The mention of AI-powered data validation tools like Numerous.ai, PydanticAI, ArtificioAI, and Informatica points to an emerging trend where machine learning is leveraged to automate and enhance data quality checks. This is particularly valuable for detecting anomalies and ensuring compliance. This suggests that manual, rule-based data validation is being augmented or replaced by intelligent systems that can learn patterns and identify issues more dynamically, indicating a significant future direction for data quality assurance.
4.3. Tools for Schema Management and Data Versioning
The emphasis on versioning not just code but also data and schema signifies a fundamental shift in data engineering. It elevates data and its structure to first-class versioned assets, mirroring code management practices, which is crucial for reproducibility and reliability in dynamic data environments.
Schema Management: Schema changes can silently break pipelines, and managing schema drift—unexpected or unplanned schema changes—is a significant challenge in data warehouse CI/CD. Such changes can disrupt dependent systems like ETL pipelines, dashboards, or machine learning models. Build failures can also occur due to invalid schemas or uncommitted dependencies.
Solutions and best practices for schema management include:
Leverage Schema Management Tools: Tools such as SQLPackage (from Microsoft), Flyway, and Liquibase offer robust solutions for managing schema changes. They can automate schema comparisons, validate changes, and ensure consistent application across environments.
Automate Schema Validation: Schema validation should be integrated as part of the build phase within CI/CD pipelines. This step ensures that new changes are syntactically and structurally valid before being applied to staging or production environments. Tools like SchemaSpy or custom SQL scripts can be used for this purpose.
Version Control for Schemas: Schema definitions should be stored in source control, treating them as code. This practice ensures traceability and allows for rollbacks in case of failures. Utilizing schema registries, such as Confluent for Kafka, is also a recommended practice.
Automated Validation Frameworks: Tools like dbt or custom Python scripts can be employed to define and validate transformation logic and data quality metrics, including schema adherence.
Idempotent Migration Scripts: Database migration scripts should be written to be idempotent, meaning they can be run multiple times without causing unintended consequences.
Progressive Schema Changes: For high-impact operations, a phased approach to schema changes should be considered.
Data Consistency Checks: Automate consistency checks to ensure data integrity during schema migrations or deployments.
Data Versioning: Versioning data itself is often overlooked in data engineering, leading to significant challenges in reproducibility, debugging, and governance. Without proper data versioning, it becomes difficult to reproduce past analyses or machine learning model results, trace bugs to specific inputs, or audit changes to datasets.
Best practices for data versioning in modern data pipelines include:
Immutable Data Storage: Instead of overwriting data, new versions should be stored as append-only. This approach enables time-travel capabilities and comprehensive audit trails. An example folder structure for parquet files might be /data/raw/customer_data/snapshot_date=YYYY-MM-DD/, which integrates easily with cloud object stores like S3, GCS, or Azure Blob, leveraging partitioning for performance.
Use Copy-on-Write or Merge-on-Read Formats: Leveraging file formats that natively support versioning and time travel, such as Delta Lake, Apache Hudi, and Apache Iceberg, is highly recommended.
Version-Control Your Data Transformation Code: Tools like dbt, Apache Airflow, or Dagster should be used in conjunction with Git to version SQL models, data flow Directed Acyclic Graphs (DAGs), and business logic. This ensures reproducible transformations that are tied to specific data snapshots.
Capture Metadata and Lineage: Comprehensive metadata is crucial for versioning and tracing how datasets were derived. Tools such as OpenLineage, DataHub, and Amundsen can automatically track details like dataset version, code version, owner, and last modified timestamp.
Snapshot External Sources: When data pipelines pull from external APIs or SaaS platforms, which may change data retroactively, it is important to create snapshots of the pulled data daily or weekly to preserve historical records. Hashing the data and storing these hashes in a database can also help detect changes.
Versioning for ML Features: For machine learning pipelines, it is beneficial to version training data, features, and model outputs, often with the aid of specialized tools like Feast, MLflow, or Weights & Biases.
Table 1: Key CI/CD Tools and Their Relevance to Data Engineering
5. Navigating Unique Challenges in Data Engineering CI/CD
5.1. Strategies for Handling Large Datasets and Performance Bottlenecks
Data engineering CI/CD faces distinct challenges when dealing with large datasets. Extensive validation is required to ensure that CI/CD pipelines can handle the scale of production data without failures. Furthermore, resource-intensive tests, such as load or stress tests, may not be practical to run on every build due to the significant cost and time constraints involved.
A key challenge is balancing the need for rapid feedback in CI/CD with the time and resource costs of testing against large datasets. This necessitates a strategic approach to test selection and data sampling. The solution is not to avoid testing, but to intelligently define which tests are run at each stage to balance speed and quality.
Effective strategies and solutions include:
Volume Testing: This remains essential for large datasets to ensure the pipeline's robustness under scale.
Test Data Management: Employing synthetic or mock data for testing schema changes and transformations in feature branches is crucial to avoid disrupting or relying on production data. Additionally, replicating smaller, representative samples of real data can provide a balance between realism and test efficiency.
Optimized Testing Strategy: It is imperative to define which types of tests run at each stage of the CI/CD pipeline to balance speed and quality. This involves prioritizing faster, more isolated tests (like unit tests) early in the pipeline and reserving more resource-intensive tests (like full end-to-end or performance tests) for later, less frequent stages.
Modular Pipeline Design: Breaking down complex workflows into independently testable components enables faster debugging and promotes code reuse. This modularity inherently aids in scaling, as individual components can be optimized and tested in isolation.
ETL Pipeline Scaling Strategies: Adopting effective ETL pipeline scaling strategies, coupled with metadata-driven orchestration, provides a robust framework for defining and managing pipeline dependencies in a version-controlled manner. This helps in efficiently processing large volumes of data.
5.2. Mitigating Schema Drift and Managing Schema Evolution
Schema drift, defined as unexpected or unplanned schema changes, is one of the most significant challenges in data warehouse CI/CD. Such changes can disrupt dependent systems including ETL pipelines, dashboards, or machine learning models that rely on the old schema. Furthermore, build failures can occur if the warehouse build fails due to invalid schemas or uncommitted dependencies.
Treating schema as code and implementing robust schema validation within CI/CD is a proactive governance strategy. It shifts schema management from reactive firefighting to a controlled, versioned, and automated process, which is crucial for maintaining pipeline stability in evolving data landscapes.
Key solutions and strategies to mitigate schema drift and manage schema evolution include:
Leverage Schema Management Tools: Tools like SQLPackage (from Microsoft) and Flyway offer robust solutions for managing schema changes. They can automate schema comparisons, validate changes, and ensure consistent application across environments.
Automate Schema Validation: Schema validation should be included as an integral part of the build phase within the CI/CD pipeline. This step ensures that any new changes are syntactically and structurally valid before they are applied to staging or production environments. Tools such as SchemaSpy or custom SQL scripts can be integrated into the pipeline for this purpose.
Version Control for Schemas: Schema definitions should be stored in source control, treating them as code. This practice ensures traceability, allows for easy rollbacks in case of failures, and aligns schema changes with code changes. The use of schema registries is also recommended.
Automated Validation Frameworks: Tools like dbt (Data Build Tool) or custom Python scripts can be used to define and validate transformation logic and data quality metrics, including checks against expected schema structures, automatically during the CI/CD pipeline execution.
Idempotent Migration Scripts: Database migration scripts should be written to be idempotent, ensuring that they can be run multiple times without causing unintended or cumulative consequences. This is critical for reliable deployments and rollbacks.
Progressive Schema Changes: For high-impact schema operations, considering a phased approach to deployment can reduce risk by gradually introducing changes to subsets of the environment or data.
Data Consistency Checks: Automate consistency checks to ensure that no data integrity issues arise during schema migrations or deployments. Implementing alerts for anomalies in data quality metrics, potentially using tools like dbt or Great Expectations, provides immediate feedback on data health.
5.3. Addressing Non-Deterministic Data: Causes and Testing Solutions
Non-deterministic data introduces a profound technical challenge to CI/CD, requiring sophisticated testing strategies that go beyond simple input-output comparisons. It forces a shift from "exact match" testing to "property-based" or "range-based" validation. Non-deterministic behavior in data pipelines means that the same input can yield different outputs across multiple runs, making traditional testing difficult. This unpredictability can stem from complex AI systems, random initializations, stochastic elements in training, hardware differences, race conditions, and certain algorithms.
Causes of Non-Determinism in ETL/SQL:
SQL SELECT statements without an ORDER BY clause: While these often output in the same order, it is not guaranteed, leading to inconsistent test results if order is assumed.
Non-ordered dictionaries/hashmaps: In many programming languages, the iteration order of dictionary or hashmap items is not guaranteed, which can cause varying results if code cycles through them.
Statement time stamps: Functions like CURRENT_TIMESTAMP can produce different results if the primary and replica time zones differ in a replication environment.
Special columns: Columns such as DatasliceID and RowID can introduce non-determinism.
User-visible system functions: Functions like Current_DBID or Current_SID may not return the same result across all replication nodes.
User-defined functions (UDFs) or user-defined aggregates (UDAs): If these are not explicitly marked as deterministic during registration, they can lead to data divergence between primary and replica systems.
Concurrency defects: The increasing use of multicore processors, virtual machines, and multi-threaded languages or systems of systems (SoSs) can lead to race conditions, order violations, and other concurrency defects, making system behavior unpredictable.
Adaptive machine learning systems: Autonomous and adaptive machine learning systems constantly improve and modify their behavior based on accumulated data, making their outputs inherently non-deterministic over time.
The strong preference for "making the code deterministic" suggests that addressing non-determinism is primarily a design and coding best practice, not just a testing challenge. Proactive design reduces the likelihood of intermittent, hard-to-debug failures in production.
Table 4: Non-Deterministic Data Causes and Testing Strategies
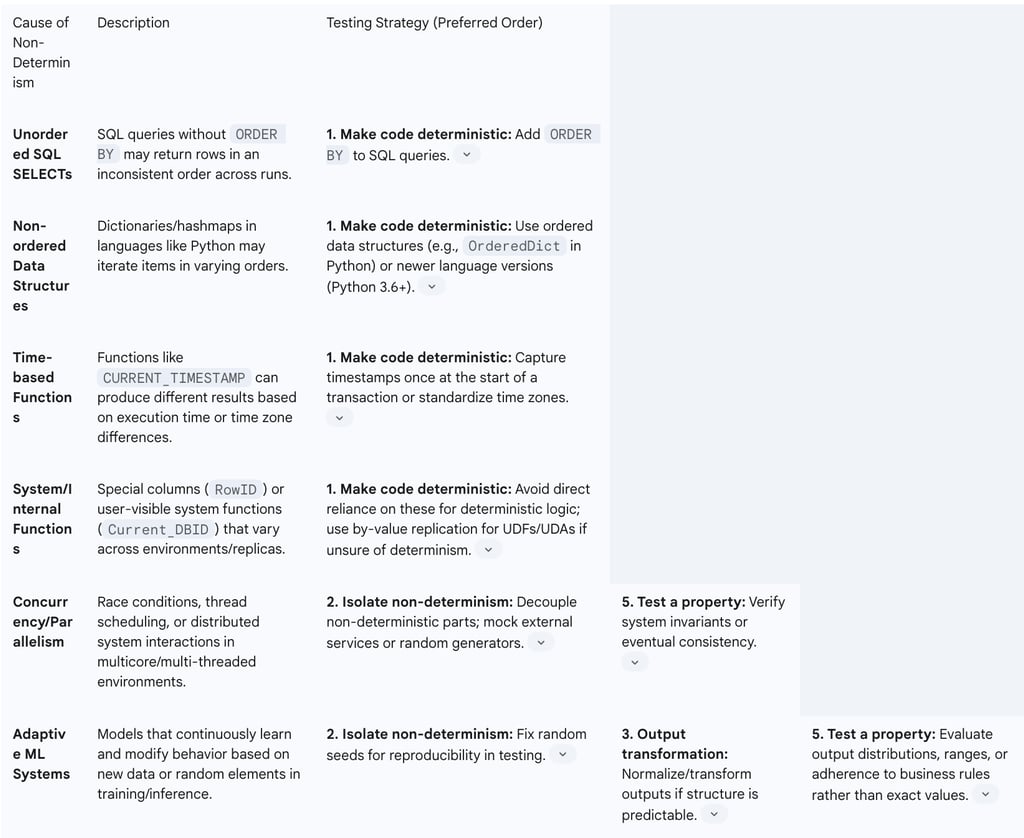

Testing Strategies (in order of preference):
Make the code deterministic: This is the most preferred approach, as more deterministic code is generally better code. It leads to a restricted execution space and fewer potential bugs, particularly the elusive, hard-to-reproduce kind. This involves fixing SQL queries by adding ORDER BY clauses or using ordered data structures in programming languages.
Isolate the non-determinism and test the code that relies upon it separately: This involves structuring the code such that the non-deterministic part (e.g., a random number generator) is obtained from a specific function. This function can then operate in a "test" mode, where it provides deterministic numbers from a pre-populated file, and a "real" mode for actual use. This allows for consistent testing of the core logic with predictable inputs.
Output transformation: If the non-deterministic output follows a predictable structure (e.g., "You rolled a N!"), test code can be written to transform the output into a deterministic format (e.g., "You rolled an n!") using regular expressions or templating. This approach works even if the application code cannot be modified, though the test code itself can become complex.
List multiple valid outputs in your test: If there is a limited number of valid non-deterministic outputs, tests can be created to check for any of these valid possibilities. For example, if a webpage displays two products in an arbitrary order, tests can verify that at least one of the expected orders is displayed.
Test a property of the output rather than the output itself: Instead of checking for an exact output, a relevant property can be extracted from the output and tested. For instance, when testing a dice roll, one might extract the number rolled and then test properties such as "the number is an integer," "the number is above 0 but below 7," or "the number is not negative". This allows for more robust testing of the underlying logic even with non-deterministic outputs.
This complexity is a core differentiator for data engineering CI/CD, where the goal shifts from exact reproducibility to ensuring that data adheres to expected properties or falls within acceptable ranges.
5.4. Overcoming Complex Dependencies and Environment Management Hurdles
Data engineering CI/CD pipelines frequently encounter challenges related to complex dependencies and environment management. Data pipelines often involve multiple dependencies, which can lead to conflicts between incompatible libraries or different versions of the same artifact. Furthermore, interdependencies between CI, CD stages, and the underlying cluster state can significantly complicate testing, as integration tests often require live infrastructure to be in a consistent and reconciled state. Environment management itself presents hurdles, including provisioning infrastructure, managing environment drift, ensuring data integrity, and synchronizing configurations across various environments. Build failures due to invalid schemas or uncommitted dependencies can also render the syncing of feature branches impossible. Re-triggering entire CI pipelines for validating only specific tests can be costly and time-consuming.
The consistent recommendation for "dedicated feature environments" and "ephemeral environments" highlights them as a strategic investment. These are foundational for achieving true CI/CD agility in data engineering by enabling parallel development, isolated testing, and rapid iteration without impacting shared resources. Without such environments, dependency conflicts and environment drift would severely hinder the benefits of CI/CD.
Effective solutions and strategies to overcome these challenges include:
Modular Pipeline Design: Breaking down complex workflows into independently testable components is a fundamental solution. This approach enables faster debugging, promotes code reuse, and simplifies the management of dependencies within the pipeline.
Dedicated Feature Environments: Creating isolated, ephemeral environments for each feature branch is crucial for independent testing and development. These environments should be provisioned automatically using Infrastructure as Code (IaC) tools. To ensure test reliability, prior test artifacts or residual data must be cleaned up between runs, often achieved using containers or sandboxed namespaces to isolate test runs and prevent cross-contamination.
Automate Syncing Workflows: Utilizing APIs or custom scripts to automate the synchronization of feature branches with the main workspace reduces manual intervention and ensures that the latest schema and data are available for testing.
Standardized Configuration: To overcome integration challenges posed by different tools and configurations, standardizing configuration settings—such as file formats, API endpoints, and data models—is essential.
Centralized Visibility: Implementing a centralized dashboard or reporting tool provides comprehensive visibility across the entire pipeline, improving transparency and accountability.
Test Impact Analysis: To optimize testing time, implement test impact analysis to run only those tests that are directly relevant to recent code changes. Additionally, identifying and parallelizing the slowest tests can significantly reduce overall pipeline execution time.
6. Real-World Implementations: Case Studies in Data Engineering CI/CD
6.1. Netflix: Pioneering Data Reliability and Resilience
Netflix, the global streaming giant, faced significant challenges in delivering a seamless streaming experience due to the complexity and dynamic nature of its vast software infrastructure. To maintain its competitive edge, the company recognized the imperative to accelerate its software development lifecycle and enhance the reliability and performance of its platform.
Netflix's CI/CD implementation featured several key components:
Spinnaker: Netflix adopted Spinnaker, an open-source, multi-cloud continuous delivery platform, to automate and streamline the deployment process across its diverse cloud infrastructure.
Asgard: Another open-source tool developed by Netflix, Asgard, was employed for managing and deploying applications on Amazon Web Services (AWS).
Jenkins: A popular CI tool, Jenkins, was integrated into Netflix's pipeline to automate the build and test processes, which significantly reduced testing time and provided faster feedback to developers.
Chaos Monkey: Netflix pioneered Chaos Monkey, a tool designed to test system resilience by intentionally introducing failures in the production environment. This radical approach aimed to identify and address vulnerabilities proactively, thereby building more fault-tolerant systems. The practice incentivized developers to design modular, testable, and highly resilient systems from the outset. This pioneering use of Chaos Monkey represents a radical shift from avoiding failures to intentionally introducing them as a core part of their CI/CD and reliability strategy. This highlights that for highly distributed and critical data platforms, traditional "pass/fail" testing is insufficient; systems must be proven resilient under adverse conditions.
The results of Netflix's CI/CD implementation were transformative:
The company achieved unparalleled speed in releasing new features and updates, demonstrating rapid release cycles.
Platform reliability and robustness were significantly enhanced, enabling the systems to handle major AWS outages without issue.
Netflix reported a 92% reduction in production incidents, 85% faster recovery times when issues did occur, and near-zero downtime for critical data flows.
The robust testing strategy, including performance benchmarks and privacy compliance validation, contributed to zero data privacy incidents in two years.
Automation through CI/CD optimized resource utilization and increased the efficiency of development teams, allowing Netflix to strategically focus on innovation.
6.2. Airbnb: Streamlining Data Workflows and DevOps Integration
Airbnb faced significant challenges with scaling its operations, managing increased user activity and data volumes, and addressing issues like server crashes, website downtime, and lengthy development and deployment cycles. The company recognized the need for a more agile environment to accelerate innovation and respond to market demands more quickly.
Airbnb's CI/CD implementation and DevOps integration involved several strategic initiatives:
AWS Migration: Airbnb migrated its infrastructure to Amazon Web Services (AWS), leveraging services such as Amazon EC2 for elastic servers, auto-scaling to adjust capacity based on demand, and Amazon EMR for efficient processing of large datasets. They also utilized AWS CodeDeploy and AWS CodePipeline to facilitate rapid deployment and development. This migration enabled them to overcome scalability issues, reduce downtime, and improve cost efficiency.
Salesforce DX, Git, and Buildkite: For their CRM DevOps, Airbnb employed a framework that linked different environments (Developer, Integration, QA, Staging, Pre-release, Hotfix, Production) to specific Git branches. Buildkite tasks were activated to deploy code into designated sandboxes after peer review.
Staging Area and ETL: The data engineering pipeline utilized PostgreSQL as a staging area for ETL processes, with Python and Pandas for data extraction and transformation.
Comprehensive Testing Stages: Code progressed through multiple testing stages, including unit, integration, functional, regression, user acceptance testing (UAT), and performance testing, ensuring thorough validation before production deployment.
Deployment Optimization: Airbnb implemented strategies such as pre-scheduled deployment windows, build validation against the production environment, Quick Deploy, and Incremental Deploys to significantly reduce actual deployment time.
Data Framework Development: Airbnb developed Riverbed, a data framework similar to AWS Lambda, to enhance their data processing capabilities.
The results of these efforts were substantial:
Deployment time was dramatically reduced from 90 minutes to just 15 minutes for CRM updates.
The company successfully overcame scalability issues, reduced downtime, and improved cost efficiency by leveraging AWS's capabilities.
Enhanced data protection and compliance were achieved through the robust security measures offered by AWS.
Airbnb gained the ability to efficiently handle approximately 50 gigabytes of data daily, enabling detailed user behavior analysis and informed decision-making.
Airbnb's case demonstrates how CI/CD extends beyond core application development to critical data-driven business processes, such as CRM and user behavior analysis, directly impacting operational efficiency and decision-making speed. This shows that CI/CD is not confined to traditional software but is applied to the data pipelines that power business intelligence and operational decisions, leading to tangible benefits like faster deployment and improved cost efficiency.
6.3. Uber: Scaling Data Pipelines and ML Model Deployment
Uber operates at an immense scale, with thousands of microservices generating hundreds of petabytes of raw data daily. This vast amount of data is leveraged by engineering and data teams across the company for various use cases, from optimizing routes to ensuring timely food deliveries. Uber faced challenges in democratizing data workflows, managing a large volume of machine learning (ML) model deployments, and ensuring safety and standardization within its rapidly growing codebase.
Uber's CI/CD implementation for scaling data pipelines and ML model deployment involved significant architectural and process changes:
Piper: Uber developed Piper as its centralized workflow management system, designed to democratize data workflows across the organization, enabling various teams from city operations to ML engineers to work faster and more efficiently.
Up CD (Redesigned Continuous Deployment System): Recognizing that only a small percentage of services were automatically deployed, Uber undertook a project to redesign its CD process. The new system, Up CD, aimed to create a uniform and automated solution for deploying microservices. It was tightly integrated with Uber's internal cloud platform and observability tools, ensuring standardized and repeatable deployment processes.
Deployment Optimization: Up CD optimized deployments by focusing on services affected by each commit rather than deploying every service with every code change, which reduced unnecessary builds and provided engineers with clearer visibility into changes impacting their services.
Unified Commit Flow with Safety Checks: The system introduced a unified commit flow for all services, where each service progressed through a series of deployment stages, each with its own safety checks. These conditions included time delays, deployment windows, and service alerts, ensuring deployments were triggered only when safe.
MLOps CI/CD: Uber implemented continuous integration and deployment specifically for ML models and services. This system supports a large volume of daily model deployments while maintaining the high availability of real-time prediction services.
Dynamic Model Loading: To accelerate production model iteration, Uber decoupled model and server development cycles through dynamic model loading, allowing new models to be loaded and retired models to be removed without service restarts.
Model Auto-Retirement: A process was built to automatically retire unused models, significantly reducing storage costs and memory footprint, which can impact quality of service.
Testing Infrastructure: Uber utilizes SLATE for managing short-lived testing environments and Shadower for load testing by replaying production traffic.
Build and Deploy Tools: Uber packages its services into containers using uBuild, powered by Buildkite, and relies on Netflix Spinnaker for deploying applications to production.
The results of Uber's CI/CD transformation are compelling:
The percentage of services deployed automatically increased dramatically from under 10% to nearly 70% within a year.
Despite the increased frequency of deployments, the rate of production incidents dropped by over 50% per 1,000 code changes, highlighting the system's ability to safely manage more frequent deployments at scale.
The model auto-retirement process led to a non-trivial reduction in resource footprint.
These efforts enabled faster and more efficient work for diverse teams, from city operations to ML engineers.
Uber's experience demonstrates that CI/CD is critical for managing hyper-scale microservice architectures and ML model deployments. The sheer volume of changes and interdependencies necessitates extreme automation and built-in safety mechanisms to prevent production incidents. At Uber's scale, manual intervention becomes a bottleneck and a significant risk, making CI/CD an absolute requirement for both speed and safety, especially with the dynamic nature of ML models.
6.4. Spotify: Evolving Data Platforms for Global Scale
Spotify, a global leader in audio streaming, operates in a highly competitive business that demands fast product development, deep customer understanding, and powerful tools for recommendations, music discovery, and connecting people. With an engineering-driven culture, nearly half of its staff is dedicated to building, launching, and maintaining its products.
Spotify's approach to evolving its data platforms and integrating CI/CD principles includes:
Google Cloud Migration: In 2016, Spotify undertook a significant migration, moving 1200 online services and data processing Directed Acyclic Graphs (DAGs), along with 20,000 daily job executions, from its on-premise data centers to Google Cloud.
Leveraging Google Cloud Services: Spotify extensively utilizes Google Cloud services such as BigQuery for data analysis, Pub/Sub for faster software application development, and Dataflow for both real-time and historical data analysis. These services remove much of the operational complexity, allowing Spotify's teams to focus on core business innovation.
Apache Airflow: Apache Airflow is used for data orchestration and monitoring within their ETL frameworks, ensuring efficient and scheduled data processing.
Data Version Control: While not explicitly detailed as a tool, the need for reproducible analyses and ML model results, as highlighted in general best practices, implies a robust approach to data versioning within Spotify's data platform.
CI/CD Statistics Plugin (Backstage): Spotify developed a specialized CI/CD Statistics plugin for its internal Backstage Software Catalog. This tool is designed to effortlessly track and visualize CI/CD pipeline statistics, such as build time, success rates, and error rates, providing clear insights into deployment process reliability.
Data Analysis Focus: Spotify's data engineering efforts are heavily focused on user activity, music taste, and providing insights for artists, enabling data-driven personalization and decision-making.
The implementation of these practices has yielded significant results for Spotify:
Operational complexity was reduced, allowing teams to concentrate on their core business of delighting customers.
The ability to focus on user experience was streamlined.
Spotify gained the capacity for faster and more efficient testing of new features and ideas, crucial for continuous innovation.
These efforts supported significant global user growth, with a 29% increase in premium subscribers in one year.
Improved decision-making was facilitated through robust data-driven insights for both internal teams and artists.
Spotify's development of a "CI/CD Statistics plugin" highlights a focus beyond just implementing CI/CD to optimizing it for data platform performance. This indicates a mature CI/CD practice where metrics and visibility are crucial for continuous improvement of the development and delivery process itself. This implies that once CI/CD is established, the next challenge is to make the CI/CD pipeline itself more efficient and reliable, which is a higher-order concern for large-scale data platforms.
6.5. General Examples of CI/CD Pipelines
The principles of CI/CD are universally applicable across various domains, adapting to specific nuances while delivering consistent benefits. The diverse range of general CI/CD examples reinforces that CI/CD is a universal engineering principle, adaptable across various domains, including data engineering, despite their specific nuances.
Web Application Development: In a typical scenario, a development team uses a version control system like Git. Developers make frequent commits to their branches. A CI server (e.g., Jenkins, Travis CI) automatically triggers a build process upon code push. This process compiles the code, runs unit and integration tests, and generates reports. If any issues arise, the team is immediately notified, allowing for prompt resolution. After successful integration, a CD pipeline automatically builds and deploys the application to a testing environment, where end-to-end and performance tests are executed. If all tests pass, the application moves to a staging environment for user acceptance testing (UAT) and final checks. With continuous deployment enabled, the application is automatically deployed to the production environment without manual intervention, ensuring the latest version is always available to end-users.
Enterprise-Level Implementation: Large enterprises often employ complex CI/CD pipelines. Stages typically include:
Code Commit: Developers commit changes to a shared repository (e.g., Git, GitHub Enterprise).
Build: An automated process compiles code and packages it into artifacts (e.g., Maven, Gradle, Docker).
Test: Unit, integration, and end-to-end tests are executed (e.g., JUnit, Selenium, pytest).
Staging: Deployment to a staging environment for further testing and validation (e.g., Kubernetes, Ansible).
Security Scan: Automated security checks and vulnerability scanning are performed (e.g., Snyk, SonarQube).
Production: Deployment to the production environment using advanced patterns like blue/green deployments or canary releases to minimize downtime and risk (e.g., Kubernetes, Spinnaker).
Monitoring: Continuous monitoring of application performance and health (e.g., Prometheus, Grafana).
These implementations often use Infrastructure as Code (IaC) tools to automate and standardize infrastructure setup.
SaaS Startup using Serverless Architecture: A team building serverless applications might set up direct integration between their code repository and cloud platform. When developers push changes, the pipeline automatically builds and deploys the application to the serverless environment, streamlining the release process.
Mobile App Development: Mobile startups utilize cloud-based CI/CD to automate their app builds, run tests, and distribute new versions to testers, significantly reducing manual work in the release process.
E-commerce Platform: An online store's pipeline automatically deploys website updates after testing, enabling rapid rollout of improvements to the shopping experience.
Smart Speaker Analogy: A pipeline can be conceptualized as a "routine"—a list of actions performed automatically after a specific trigger. For instance, a "CI routine" for a smart home might test every smart device. When new code for a new device (like a smart lamp) is added, the CI routine would run tests to ensure the new feature works and does not break existing functionality. A "test house" or environment serves as a functioning, very similar copy of the real environment, where new setups are triple-checked before delivery to clients.
This breadth of application demonstrates that the underlying benefits of CI/CD—automation, early feedback, and reliability—are not domain-specific but fundamental to modern software delivery, making its adoption in data engineering a logical and beneficial extension.
7. Best Practices for Building Robust Data Engineering CI/CD Pipelines
7.1. Implementing Comprehensive Version Control for Code and Data Assets
Version control in data engineering is not just for code; it represents a holistic governance strategy encompassing code, data, and schema. This integrated approach ensures traceability, reproducibility, and auditability across the entire data lifecycle, which is paramount for regulated industries and complex data products.
Code Version Control: It is crucial to set up a robust version control system, such as Git, to track all changes in pipeline code and configurations. A centralized repository should be established to store all pipeline-related files, and developers should be encouraged to make frequent, small, incremental code commits.
Branching Strategies: Employing clear branching strategies, such as GitFlow or Trunk-Based Development, along with automated merge processes, is essential for managing parallel development and facilitating proper testing and deployment. This includes creating distinct development, test, and production branches to ensure isolated environments.
Data Versioning: This is critical for reproducibility, debugging, and governance in data engineering. Without proper data versioning, it becomes impossible to reproduce past analyses or machine learning model results, trace bugs to specific inputs, or audit changes to datasets. Key practices include:
Immutable Data Storage: New versions of data should be stored as append-only rather than overwriting existing data. This enables "time-travel" capabilities and comprehensive audit trails. This approach integrates well with cloud object stores that support partitioning for performance.
Copy-on-Write/Merge-on-Read Formats: Utilizing file formats that natively support versioning and time travel, such as Delta Lake, Apache Hudi, and Apache Iceberg, is highly recommended.
Track Schema Versions: Schema changes can silently break pipelines, making it vital to track schema versions. This involves using schema registries (e.g., Confluent for Kafka) and validating schema changes with CI/CD pipeline checks. Schema versions should be stored alongside the data.
Version-Control Transformation Code: Data transformation code, including SQL models, data flow DAGs, and business logic, should be version-controlled using tools like dbt, Apache Airflow, or Dagster in conjunction with Git. This ensures reproducible transformations tied to specific data snapshots.
Capture Metadata and Lineage: Good metadata is essential for versioning and tracing how datasets were derived. Tools such as OpenLineage, DataHub, and Amundsen can automatically track details like dataset version, code version, owner, and last modified timestamp.
Snapshot External Sources: If the pipeline pulls data from external APIs or SaaS platforms that may change data retroactively, creating daily or weekly snapshots of the pulled data is crucial to preserve history. Hashing the data and storing these hashes in a database can also help detect changes.
7.2. Automating Testing and Validation Across All Pipeline Stages
Automated testing and validation act as critical "quality gates" at every stage of the pipeline. Code and data cannot progress without passing these checks, fundamentally shifting quality assurance from post-mortem debugging to proactive prevention.
Early Detection: Automated testing is fundamental for identifying conflicts and issues at an early stage of the development process. This proactive approach ensures that dependencies and other potential problems are identified earlier in the SDLC, saving significant time and effort later.
Comprehensive Test Suite: Implement a comprehensive suite of automated tests, including unit tests, integration tests, and end-to-end tests, to ensure consistent and efficient validation of code changes throughout the CI/CD pipeline.
Data Quality Testing: Integrate robust data quality and integrity testing throughout the pipeline. This involves checking for accuracy, completeness, consistency, uniqueness, and timeliness of data. Specific checks include verifying missing or null values, validating data types and formats, and ensuring data conforms to expected ranges and distributions.
Schema Validation: Automate schema validation as an integral part of the build phase. This ensures that any new schema changes are syntactically and structurally valid before they are deployed.
Automated Validation Frameworks: Leverage specialized tools and frameworks like dbt (Data Build Tool) or custom Python scripts to define and validate transformation logic and data quality metrics automatically during the CI/CD pipeline execution.
Mock Data Utilization: Employ mock data for testing purposes to avoid affecting real data or production systems. Mock data can be generated to simulate various scenarios, including edge cases, ensuring comprehensive testing.
Testing Frameworks: Utilize established testing frameworks such as Pytest and Unittest for Python-based data processing components.
Continuous Monitoring of Test Coverage: Regularly monitor and review unit test coverage and effectiveness. As data schemas or business logic evolve, the unit tests should also be refined and updated to remain relevant and comprehensive.
7.3. Leveraging Infrastructure as Code for Consistent Environments
Infrastructure as Code (IaC) is particularly critical for data engineering CI/CD because it ensures that the environments where data pipelines run are consistent and reproducible. This addresses the "works on my machine" problem and is vital for reliable data processing, where environment variations can lead to non-deterministic outcomes.
Definition: IaC involves defining and managing infrastructure components, such as servers, networks, and databases, through code rather than manual configuration.
Benefits:
Consistency: IaC ensures consistent environments across different stages of the CI/CD pipeline—development, testing, and production setups. This eliminates manual configuration errors and promotes uniformity, which is paramount for reliable data processing.
Reproducibility: By treating infrastructure as code, environments can be versioned, automated, and replicated with high fidelity. This ensures that a pipeline tested in one environment will behave identically in another, a critical factor for data integrity.
Efficiency: IaC automates the provisioning and management of infrastructure resources, significantly reducing manual effort and accelerating environment setup times.
Tools: Popular IaC tools include Terraform and AWS CloudFormation, which enable automated and reproducible management of infrastructure resources.
7.4. Establishing Continuous Monitoring and Feedback Loops
Continuous monitoring closes the CI/CD loop, providing essential feedback from production back to development. This enables rapid iteration and ensures that pipeline changes are not only deployed reliably but also perform as expected in the real world, addressing issues like data freshness and latency.
Purpose: Continuous monitoring is essential to track application performance and overall health in production environments, ensuring stability and optimal operation. It functions as the pipeline's early warning system, providing immediate alerts for anomalies or issues.
Key Metrics for Data Pipelines: Monitoring for data pipelines should focus on specific metrics that reflect data health and pipeline performance:
Data freshness: How recent is the data available for consumption?
Processing latency: How fast are data transformations being executed?
Error rates: What components are failing and why?
Business metrics: Are end-users receiving the data they need, and is it meeting business objectives?
Tools: Common tools for monitoring include Prometheus and Grafana for metrics collection and visualization , and cloud-specific services like Azure Monitor.
Feedback Mechanisms: The CI/CD system should provide rapid feedback to developers. If any stage of the pipeline fails, the team must be immediately notified, allowing them to address issues quickly. Beyond automated alerts, collecting actionable feedback from users and analyzing this data effectively is crucial for understanding real-world performance and user satisfaction.
Continuous Improvement: The insights gained from continuous monitoring and feedback loops are vital for the ongoing refinement of tests and processes. This iterative approach ensures that the CI/CD pipeline itself continuously improves, adapting to evolving requirements and maintaining its effectiveness.
Conclusion and Future Directions
The integration of Continuous Integration and Continuous Delivery/Deployment (CI/CD) practices, coupled with robust unit testing and comprehensive validation strategies, has fundamentally transformed data engineering. By adopting these methodologies, organizations transition from manual, error-prone data processes to automated, reliable, and scalable data pipelines. This shift ensures higher data quality, faster delivery cycles, enhanced system reliability, and improved collaboration across development and operations teams. The unique challenges inherent in data engineering—such as managing large datasets, mitigating schema drift, and addressing non-deterministic data—necessitate specialized tools and tailored strategies that extend traditional software CI/CD principles to the intricacies of data.
Leading companies like Netflix, Airbnb, Uber, and Spotify exemplify the profound impact of these practices. Their experiences demonstrate that CI/CD is not merely an operational efficiency tool but a strategic imperative for maintaining data integrity, ensuring system resilience, and accelerating business value in hyper-scale, data-driven environments. The consistent emphasis on versioning not just code but also data and schema, the strategic investment in ephemeral environments for isolated testing, and the proactive approach to "practicing failure" for resilience underscore the maturity of data engineering DevOps.
Looking ahead, several emerging trends and future research areas will continue to shape CI/CD in data engineering:
Advanced Pipeline Orchestration: The complexity of data workflows will drive the development of more sophisticated orchestration techniques capable of handling intricate dependencies and dynamic data flows.
Improved Data Lineage and Metadata Management: Enhanced traceability and governance will require more advanced tools and practices for tracking data origins, transformations, and usage throughout its lifecycle.
Integration of Real-Time Data Processing: CI/CD pipelines will increasingly incorporate capabilities for real-time data ingestion, processing, and validation, moving beyond batch-oriented approaches.
Standardized Metrics and Benchmarks: The development of industry-standard metrics and benchmarks for assessing pipeline performance and reliability will enable better comparison and optimization.
AI-Driven Quality and Automation: The proliferation of AI-powered tools for data validation, anomaly detection, and automated error correction will further enhance data quality assurance, moving towards more intelligent and autonomous data pipelines.
Edge Computing and IoT Integration: As data generation shifts to the edge, integrating edge computing and Internet of Things (IoT) data streams into CI/CD practices will become crucial for managing distributed data pipelines.
Ultimately, the journey towards fully mature CI/CD in data engineering is one of continuous improvement, where automation, rigorous testing, and a proactive approach to data quality are paramount for delivering trustworthy and impactful data products.
FAQ
What is CI/CD and why is it important for data engineering?
Continuous Integration (CI) and Continuous Delivery/Deployment (CD) are automated practices originating from software engineering, now crucial for data engineering. CI involves developers frequently merging code changes into a shared repository, followed by automated builds and tests to quickly identify integration issues. CD builds on this, preparing code for release to a production-like environment (Continuous Delivery) or automatically deploying it to production without human intervention (Continuous Deployment).
For data engineering, CI/CD is vital because it automates the testing, integration, and deployment of data processing code and infrastructure. This automation is particularly critical given the unique challenges of data, such as large datasets, schema drift (changes in data structure), and the non-deterministic nature of data (its inherent variability). Implementing CI/CD in data engineering leads to significantly improved data integrity and quality, enhanced reliability and consistency of data systems, faster iteration and deployment of data pipelines, increased efficiency and productivity for engineers, better team collaboration and visibility, and stronger security and compliance. It transforms data engineering from a manual, error-prone process into an automated, reliable, and scalable operation.
How does the Write-Audit-Publish (WAP) paradigm enhance data quality in CI/CD pipelines?
The Write-Audit-Publish (WAP) paradigm is a methodological pattern specifically designed to integrate with CI/CD for data engineering, giving teams greater control over data quality by addressing the "data first" nature of data. Unlike traditional software, where code is the primary focus of validation, data engineering requires the data itself to be validated before it's exposed to users.
The WAP approach consists of three distinct phases:
Write: Processed data is initially placed in an isolated, non-customer-facing location (e.g., a temporary branch or staging area).
Audit: The data undergoes rigorous validation against all predefined data quality requirements. Any inconsistencies or issues are identified and resolved at this stage.
Publish: Once the data is thoroughly verified and deemed trustworthy, it is released to the location where downstream users can access it.
This approach ensures that only high-quality, verified data reaches end-users, improving data integrity, enhancing security by isolating raw from audited data, and providing operational flexibility due to its modular design. It also enables code tests to run against buffered data, and data contracts (rules about data schema and quality) can be integrated.
What is unit testing in data engineering, and how does it differ from traditional software unit testing?
Unit testing in data engineering involves creating isolated tests to verify the correctness of individual components or "units" within data processing workflows. These units can be anything from a single SQL query or a Python function to a specific part of a larger data pipeline. The core purpose is to identify and fix errors early in the development cycle, improving the quality of data products.
A key distinction from traditional software unit testing is its dual focus: unit testing in data engineering applies to both the transformation logic (the code) and the data that is the output or source of these transformations. While traditional software unit tests primarily focus on code, data engineering unit tests must also consider data-centric challenges such as malformed input, missing data, deduplication, schema inference, and idempotency (ensuring re-runs produce identical outputs). This often means defining inputs, executing the data logic, and rigorously verifying the output against expected data results, which requires more complex test data management than simply mocking API responses in traditional software.
What are the challenges in creating effective test cases and managing test data for data engineering unit tests?
Creating effective test cases and managing test data for data engineering unit tests presents significant challenges due to the nature of data. Test cases require defining inputs, executing the data logic, and meticulously verifying outputs against expected results.
The primary difficulty lies in generating representative and comprehensive test data. Unlike traditional software, where simple mock data often suffices, data engineering requires a deep understanding of:
Data distributions: Test data must reflect the real-world spread of values.
Potential edge cases: Covering extreme or unusual data scenarios (e.g., nulls, empty strings, maximum/minimum values, incorrect formats) is critical.
Sheer volume: While unit tests often use subsets, the complexity of realistic data can still be high.
Test data can be synthetic (generated artificially) or subsets of real data. Mock data, such as CSV files with various combinations of values, is crucial for testing without affecting production systems. This complexity often necessitates specialised tools or domain expertise to ensure test validity and coverage. The ultimate goal is to catch errors early that could lead to data corruption or incorrect analysis.
How do comprehensive testing strategies extend beyond unit tests in data pipelines?
While unit testing focuses on individual components, a comprehensive testing strategy for data pipelines incorporates several layers to ensure overall health, performance, and reliability. This multi-tiered approach addresses the various levels of complexity and potential failure points unique to data movement and transformation:
Integration Testing: Verifies how different components interact within the pipeline, especially with external systems (e.g., messaging queues, databases) during data extraction and loading.
End-to-End Testing: Validates the entire data pipeline from initial data ingestion to final data loading into the target system, ensuring it functions correctly as a whole.
Functional Tests: Validate that the integrated components perform as users expect, often focusing on common business scenarios.
Source Tests: Ensure ingested data is transported to the target platform without loss or truncation, checking freshness, structure, and alignment.
Flow Tests: Validate live data for completeness, accuracy, and consistency after transformation and deployment into a data mart layer, checking for data loss, correct mappings, and absence of nulls or duplicates.
Contract Tests: Ensure that consumed columns are always present in the source table in the data mart layer, maintaining consistency between data providers and consumers even after changes.
This layered approach is essential given the complexity of data pipelines, which involve various stages like ingestion, transformation, loading, storage, and interaction with external systems.
What is the difference between technical and business-related data quality checks?
Data quality tests are crucial for validating both source data and the results of internal transformations, and they are categorised into two main groups based on their focus and responsibility:
Technical Data Quality Tests: These focus on the structural integrity and correctness of data from a technical perspective, ensuring adherence to predefined rules and constraints. They are primarily the responsibility of data engineers, who verify the correct operation of the data pipelines themselves. Examples include:
Uniqueness Test: Ensuring no duplicate values in key fields.
Null Check: Verifying that essential fields are not empty.
Data Type Validation: Confirming data conforms to expected types (e.g., dates, integers).
Range Check: Validating numeric values fall within specified ranges.
Format Check: Checking data follows specific patterns (e.g., phone numbers).
Foreign Key Constraint Check: Ensuring referential integrity between tables.
Business-Related Data Quality Tests: These focus on the relevance and accuracy of data within the context of specific business rules and processes. They often fall under the purview of QA engineers or data stewards, requiring a strong understanding of business needs and continuous communication with data stakeholders. Examples include:
Completeness Check: Ensuring all necessary data fields contain values for business operations.
Consistency Check: Validating logical consistency within and across datasets (e.g., total amount matching sum of items).
Timeliness Check: Confirming data is current and relevant for business decisions.
Accuracy Check: Ensuring calculated values are correct based on business logic.
Referential Integrity Check: Validating business relationships between datasets.
Business Rule Validation: Ensuring data adheres to specific business rules (e.g., discount percentages).
This distinction highlights the necessity of cross-functional collaboration, with data engineers ensuring technical integrity and business stakeholders defining and validating business relevance, reinforcing a shared responsibility for data quality.
What are the key dimensions of data quality and how are they measured?
Data quality, often perceived as abstract, is defined by five concrete, measurable dimensions that provide a framework for monitoring data health:
Accuracy: The extent to which data is correct and error-free. It is measured by implementing proper data validation, automated error checks, manual reviews, and cross-referencing.
Consistency: How uniform data is and whether it follows the same format across different systems. It's ensured through standardisation processes like consistent naming conventions, data formats, and data types.
Completeness: The extent to which data contains all required information. Measured using Key Performance Indicators (KPIs) to ensure all necessary information is captured and aligned with business objectives.
Timeliness: The degree to which data represents current information and is available when needed. Achieved by implementing real-time data collection, automating processing, and using efficient storage and retrieval systems.
Uniqueness: The extent to which data is unique and accurately identifies individuals or entities, preventing duplicates. Ensured through automated duplicate checks, manual reviews, and cross-referencing.
A Data Quality Matrix is a valuable tool that quantifies these dimensions. Examples of measurable metrics and assertions within such a matrix include the proportion of non-NULL or unique column values, counts of unique values, boolean indicators for uniqueness, and statistical measures like minimum, maximum, average, and standard deviation of column values. These metrics enable systematic and automated data validation within CI/CD pipelines.
Why is "validate early, validate often" a paramount principle in data engineering?
The principle of "validate early, validate often" is paramount in data engineering because it advocates for integrating validation checks throughout the entire data pipeline process, rather than deferring them to final stages.
This approach ensures that issues are detected and addressed as soon as they arise, minimising the risk of propagating errors downstream. Propagating errors through a data pipeline significantly increases the cost and effort required to fix them later on. This aligns with the "1:10:100 rule" in data quality, which suggests that:
Preventing poor data quality at the source costs £1 per record.
Remediation after data creation costs £10 per record.
Doing nothing and dealing with the consequences costs £100 per record.
By consistently validating data and code early and frequently within CI/CD pipelines, data engineers can proactively maintain high data quality, reduce operational overhead, and ensure the reliability and integrity of their data products.