Data Fabric vs. Data Lakehouse: A Comprehensive Architectural Analysis
As dominance of cloud-native solutions will persist and strengthen. Cloud providers will continue to evolve and offer comprehensive, integrated solutions that inherently combine aspects of both Data Fabric and Data Lakehouse.


Modern enterprises are navigating an increasingly complex data landscape, characterized by an unprecedented explosion in the volume, velocity, and variety of data. This data originates from a vast array of sources, spanning on-premises systems, diverse cloud environments, and real-time Internet of Things (IoT) devices. A persistent and significant challenge for organizations remains the pervasive issue of data silos—isolated pockets of information that impede holistic insights and efficient data access across departments. These fragmented data stores obstruct seamless data flow, leading to operational inefficiencies and inconsistent decision-making across the enterprise.
Compounding these issues is the escalating demand for real-time analytics and the integration of sophisticated Artificial Intelligence (AI) and Machine Learning (ML) capabilities. These advanced applications necessitate immediate access to fresh, high-quality data to derive timely and accurate insights. Consequently, ensuring robust data quality, comprehensive governance, stringent security measures, and continuous regulatory compliance across such a fragmented and dynamic data environment presents substantial operational and strategic hurdles for organizations.
1.2 Introduction to Data Fabric and Data Lakehouse as Solutions
In response to these multifaceted challenges, two prominent modern data architectures have emerged: Data Fabric and Data Lakehouse. Each offers a distinct yet powerful approach to managing and leveraging enterprise data.
A Data Fabric is conceptualized as an overarching architectural approach designed to unify and integrate data from disparate sources. It aims to abstract away underlying technological complexities, providing seamless, governed access to data consumers. This architecture endeavors to "stitch together integrated data from many different sources" to deliver enriched data to various consumers.
Conversely, a Data Lakehouse represents a modern data architecture that strategically blends the cost-effectiveness and flexible storage capabilities of data lakes with the structured data management and reliability features, such as ACID (Atomicity, Consistency, Isolation, Durability) properties, traditionally associated with data warehouses. Its objective is to create a single, unified platform optimized for diverse analytical and AI/ML workloads.
The emergence of Data Fabric and Data Lakehouse signifies a fundamental shift in the definition of a modern data architecture. Historically, data architecture often involved rigid, distinct, and sequential layers for ingestion, storage, processing, and serving. However, the conceptualization of Data Fabric as a "design" that unifies existing heterogeneity and Data Lakehouse as a "new technology" or "platform" consolidating analytical capabilities indicates a clear evolution. This progression moves away from siloed systems towards more integrated, intelligent, and flexible paradigms. The emphasis on "self-driving" capabilities for Data Fabric and "unified governance" for Data Lakehouse underscores this architectural maturation. Organizations are no longer merely seeking storage solutions; they are demanding holistic data management strategies that prioritize real-time data accessibility, comprehensive governance, and advanced analytics readiness. This evolution directly addresses the limitations of older data warehousing and data lake models, which often struggled to meet the dynamic demands of modern data-intensive applications and AI initiatives.
Understanding Data Fabric Architecture
2.1 Definition and Core Principles
Data Fabric is defined as a single, unified architecture that integrates a comprehensive set of technologies and services. Its primary purpose is to deliver integrated and enriched data to the appropriate data consumer, at the right time and in the right method, supporting both operational and analytical workloads. Gartner characterizes it as an "emerging data management design for attaining flexible, reusable, and augmented data integration pipelines, services, and semantics". A crucial aspect of understanding Data Fabric is recognizing that it is a holistic approach and not a singular tool or technology that can be purchased off-the-shelf.
Gartner employs the analogy of a "self-driving car" to illustrate the essence of a Data Fabric. This analogy highlights how the architecture leverages machine learning capabilities to autonomously access, consolidate, and manage data, thereby significantly minimizing manual intervention and human-intensive tasks.
Architecturally, a Data Fabric is composed of a dynamic network of interacting data nodes, which can include various data platforms and databases. These nodes are distributed across an enterprise’s hybrid and multi-cloud computing ecosystem. A defining characteristic is the heterogeneity of these nodes; a Data Fabric can seamlessly incorporate diverse data warehouses, data lakes, IoT/Edge devices, and transactional databases, supporting a wide range of technologies from traditional relational databases to modern cloud-native solutions.
At its core, Data Fabric is fundamentally metadata-driven. Metadata acts as the essential framework that enables the system to comprehend, organize, and effectively manage data. A critical shift within this paradigm is from static to dynamic or active metadata. Active metadata provides real-time context, relationships, and lineage, transforming passive documentation into a living, intelligent component of the data landscape. The Data Fabric concept also embraces the entirety of the data-information-insight lifecycle, from the initial ingestion of raw data to the execution of advanced analytics and the serving of derived insights.
A key design principle of Data Fabric is the convergence of analytical and transactional worlds. Within this architecture, every data source or processing unit is treated as a "node," and these nodes interact through various mechanisms. Some interactions may involve physical data movement, while others enable data access without movement, often through data virtualization. The overarching objective is to eliminate data silos and foster a unified data environment.
2.2 Key Capabilities and Components
A Data Fabric integrates a suite of essential data management technologies. These include a comprehensive data catalog for classifying and inventorying data assets, robust data governance mechanisms to ensure data quality and compliance, versatile data integration capabilities, efficient data pipelining, and intelligent data orchestration. Additionally, it incorporates components for data preparation and a data persistence layer, crucial for enabling real-time data processing, search, and analysis.
To meet the demands of real-time operations, Data Fabric is equipped with built-in mechanisms for continuous live data ingestion from operational systems, capable of handling millions to billions of updates daily. It ensures seamless connectivity to disparate systems, even those managing terabytes of data across different technologies. Furthermore, it supports in-flight data transformation, cleansing, and enrichment, enabling the delivery of meaningful insights in real time. The architecture is designed to efficiently retrieve specific instances of business entities, such as a complete customer profile, and to handle high concurrency, processing thousands of requests per second.
Gartner emphasizes the critical role of a robust data integration backbone for effective Data Fabric implementation. This backbone is responsible for gathering data from various sources, consolidating it, and importing it to create a unified view. It must support diverse data integration methods, including traditional ETL/ELT, streaming, messaging, and replication, ensuring flexibility in how data is brought into the fabric.
Augmented data catalogs are another cornerstone component. These catalogs serve as centralized repositories for collecting all types of metadata, thereby maintaining data coherence and usability across the organization. Gartner explicitly identifies a "robust, open data catalog" as the "cornerstone of a successful data fabric strategy". Data virtualization and metadata management are pivotal capabilities that enable unified data access and integration across the fabric, frequently eliminating the need for physical data movement or the creation of redundant data copies. Moreover, an Open API architecture is considered essential, facilitating seamless integration and interoperability between different software applications and tools within the fabric.
2.3 Advantages and Benefits
Data Fabric offers numerous advantages over traditional and alternative data management approaches. A primary benefit is unified data access, providing a single, integrated data layer that allows users and applications to access data seamlessly across different sources and environments. This significantly simplifies data access and effectively breaks down persistent data silos, which often hinder organizational efficiency.
The architecture also leads to enhanced data governance. It enables the establishment and consistent enforcement of data governance policies across all integrated data sources, ensuring compliance with stringent data privacy regulations such as GDPR, CPRA, and LGPD, while simultaneously improving overall data quality and security.
Data Fabric contributes to improved DataOps by reducing the inherent complexity of data management. It automates data discovery and integration tasks and optimizes data movement, thereby streamlining data operations and accelerating the data lifecycle. Gartner’s analysis suggests that a well-implemented Data Fabric can "quadruple" efficiency levels, effectively reducing human-intensive data management tasks by half. This is particularly impactful given that data scientists and analysts often spend approximately 60% of their time on mundane tasks like data cleaning and organizing. By dramatically reducing this percentage, organizations can reallocate more time to value-adding activities such as data analysis and interpretation.
Furthermore, Data Fabric fosters greater agility and scalability. Organizations can achieve enhanced agility in their approach to data management, quickly accessing and moving data between different platforms and environments to respond rapidly to evolving business needs. The architecture is inherently designed to scale with increasing data volumes and complex datasets, handling high volumes of data generated by modern applications and systems. This architecture also enables real-time insights by providing on-demand, real-time access to all stored data, which is crucial for dynamic operational and strategic decision-making. Finally, Data Fabric can lead to cost savings by eliminating the need for multiple disparate data management tools and platforms, allowing organizations to manage and access data through a single, integrated set of tools, which can be more cost-effective over time.
2.4 Challenges and Considerations
Despite its numerous benefits, implementing a Data Fabric presents several significant challenges. The architecture is inherently complex, requiring a high level of expertise and substantial resources for its setup and ongoing management. This can be particularly challenging for organizations with limited IT and data skill sets. This complexity often translates into a high implementation cost. While the long-term benefits and potential cost savings are significant, there is a hefty upfront investment associated with establishing a Data Fabric. This includes the acquisition of new tools, software, and infrastructure, as well as the necessity of hiring or training staff with the specialized skills and experience required to manage the Data Fabric and extract maximum value from it.
Despite its core purpose of integration, integration challenges can still arise. Integrating data from multiple sources and platforms can be complicated, especially when dealing with data stored in different formats or originating from legacy systems. This demands extensive expertise in data integration and data mapping. Moreover, while Data Fabric aims to strengthen security, its distributed nature and inherent complexity, if not meticulously managed, can introduce new data security and governance risks. Ensuring uniform compliance with regulations across data spread across different environments can be difficult, potentially leading to blind spots and vulnerabilities.
A fundamental consideration is that Data Fabrics are not off-the-shelf products that can simply be purchased and deployed. Instead, they are custom-built solutions tailored to the specific needs of an organization, requiring a strategic design and implementation effort rather than a transactional software acquisition. A significant obstacle to Data Fabric adoption is often the lack of comprehensive metadata. The collection, management, and integration of metadata are crucial for providing context and meaning to data assets, and its absence can severely hinder the effectiveness of a Data Fabric. Furthermore, the successful implementation and operation of a Data Fabric frequently necessitate specialized knowledge and skills in areas such as NoSQL databases and GraphQL, which may require significant investment in training or recruitment.
The observation that Data Fabric is "not an off-the-shelf product" and demands a "high level of expertise and the right resources" highlights a crucial aspect of its adoption. This contrasts sharply with the expectation of readily available software solutions and underscores the risk of organizations "rely[ing] too heavily on vendors to provide the answers". This indicates that implementing a Data Fabric is less about acquiring a single software package and more about a complex, multi-faceted endeavor of orchestrating a diverse suite of technologies, processes, and people. It mandates a high degree of organizational maturity in data management, robust internal technical capabilities, and significant, sustained stakeholder buy-in across all levels of the enterprise. Consequently, a Data Fabric initiative is fundamentally a strategic, long-term organizational transformation rather than a mere technology deployment. Organizations must be prepared to drive the strategy internally, rather than expecting a vendor to deliver a complete, ready-made fabric.
2.5 Leading Technologies and Vendors
The Data Fabric ecosystem comprises a variety of vendors offering components and platforms that support its architectural principles. Key players in this evolving market include:
IBM Cloud Pak for Data: This platform is particularly noted for its AI-infused data integration capabilities, providing a unified environment for data and AI workloads.
K2View: Specializes in operational data management within a Data Fabric context, focusing on delivering integrated and enriched data for operational use cases.
Atlan: Recognized for its robust data cataloging and discovery features. Atlan's platform is described as "open-by-design, Kubernetes-based platform with built-in microservices is purpose-built for Data Mesh and Fabric," emphasizing its role in metadata management and data governance.
Denodo: Offers "big data fabric" solutions with an analytics-driven approach, often leveraging data virtualization to provide unified access to distributed data.
Informatica: Provides an Intelligent Data Fabric that leverages AI and Machine Learning to automate data pipelines and ensure data quality.
NetApp Data Fabric: Focuses on cloud data services, enabling consistent data management across hybrid cloud environments.
Cinchy: Offers a unique "Dataware" approach to Data Fabric, emphasizing collaborative data sharing and integration.
Talend Data Fabric: A comprehensive solution designed to assist with various aspects of data management, from connecting applications and APIs to integrating diverse data streams.
Other notable mentions in the Data Fabric landscape include Mosaic (for holistic data integration), Incorta (known for direct data mapping), Astro by Astronomer (simplifying Apache Airflow management), Elastic Stack (for search and analytics), and the Tengu DataOps platform (specializing in data operations workflows).
3. Understanding Data Lakehouse Architecture
3.1 Definition and Core Principles
A Data Lakehouse represents a modern data architecture that fundamentally blends the capabilities of a data lake with those of a data warehouse. Its core objective is to create a single, unified platform that leverages low-cost, flexible storage for all types of data—structured, unstructured, and semi-structured—while simultaneously providing the robust data structures and management features traditionally associated with data warehouses.
The Data Lakehouse was conceived to address the inherent inflexibilities and inefficiencies of traditional Extract-Transform-Load (ETL) processes that feed data warehouses, as well as the challenges posed by the lack of inherent structure and ACID (Atomicity, Consistency, Isolation, Durability) compliance in raw data lakes. It achieves this by removing the separate data warehouse storage layer and instead performing continuous data transformation directly within the underlying object storage layer.
A cornerstone principle of the Data Lakehouse architecture is the decoupling of computing power from storage. This architectural separation allows both resources to scale independently according to specific business needs, offering nearly limitless and instantaneous scalability. This flexibility is a significant advantage in managing varying workloads.
A key innovation within the Data Lakehouse is the integration of metadata layers (e.g., Delta Lake's transaction log, Apache Iceberg) over the low-cost data lake storage. These metadata layers provide crucial data warehouse-like capabilities, including structured schemas, support for ACID transactions, robust data governance, and various data optimization features, bringing reliability and consistency to raw data.
The Data Lakehouse also champions centralized data and AI governance. By unifying data warehousing and AI use cases onto a single platform, it simplifies the modern data stack. This eliminates the data silos that traditionally separate and complicate data engineering, analytics, business intelligence (BI), data science, and machine learning, thereby enabling a unified governance solution for all data, analytics, and AI assets. A significant tenet of the Data Lakehouse is to provide a consistent user experience for all data personas (e.g., data engineers, analysts, data scientists) and to ensure seamless interoperability with a wide ecosystem of external systems and tools. This consistency reduces training and onboarding costs and improves cross-functional collaboration.
3.2 Key Capabilities and Components
The architecture of a Data Lakehouse is often conceptualized in layers, as exemplified by Google Cloud's approach, which typically comprises three distinct layers :
Storage Layer: This foundational layer serves as the data lake, usually a low-cost object store (e.g., Google Cloud Storage) for all raw data—unstructured, structured, and semi-structured. It is decoupled from computing resources, allowing independent scaling of compute.
Staging Layer (Metadata Layer): This crucial layer resides on top of the data lake, providing a detailed catalog of data objects in storage. It enables essential data management features such as schema enforcement, ACID properties, indexing, caching, and fine-grained access control, bringing structure and reliability to the raw data.
Semantic Layer (Lakehouse Layer): This top layer exposes all data for consumption. Users can access and leverage data for experimentation, business intelligence presentations, and advanced analytics using various client applications and tools.
Databricks, a pioneer of the Lakehouse concept, structures its reference architecture along several key "swim lanes" that cover the entire data lifecycle :
Source Integration: This involves various methods for bringing external data into the platform, including traditional ETL processes, Lakehouse Federation for direct SQL source integration without ETL, and Catalog Federation for integrating external metastores like Hive Metastore or AWS Glue.
Ingestion: Supports both batch and streaming data ingestion. Tools like Databricks Lakeflow Connect offer built-in connectors for enterprise applications, while Auto Loader facilitates direct loading of files from cloud storage. Partner ingest tools handle batch ingestion into Delta Lake, and Structured Streaming manages real-time events from systems like Kafka.
Storage: Data is typically stored in cloud object storage, often organized using the Medallion Architecture (Bronze, Silver, Gold zones) to curate data as Delta files/tables or Apache Iceberg tables.
Transformation & Querying: The Databricks Lakehouse utilizes powerful engines like Apache Spark and Photon for all transformations and queries. It supports SQL queries via SQL warehouses, as well as Python and Scala workloads via workspace clusters. Lakeflow Declarative Pipelines simplify the creation of reliable ETL pipelines.
Serving: The platform provides Databricks SQL for data warehousing (DWH) and BI use cases, powered by SQL warehouses and serverless SQL warehouses. For machine learning, Mosaic AI Model Serving offers scalable, real-time model serving. Lakebase, an OLTP database based on Postgres, is integrated for operational databases.
Collaboration: Facilitates secure data sharing with business partners through Delta Sharing, an open forum for data exchange via the Databricks Marketplace, and secure Clean Rooms for collaborative work on sensitive data.
Data & AI Governance: Centralized by Unity Catalog, which provides a single point for managing data access policies across all workspaces and supports all data assets, including tables, volumes, features, and models. It also captures runtime data lineage. Lakehouse Monitoring and System Tables enhance observability.
Data Intelligence Engine: Includes features like Databricks Assistant, a context-aware AI assistant available across various interfaces.
Automation & Orchestration: Supports Lakeflow Jobs for orchestrating data processing, machine learning, and analytics pipelines, and integrates with CI/CD and MLOps workflows.
Google Cloud's approach to Data Lakehouse is further enhanced by specific technologies :
Apache Iceberg: An open table format that brings data warehouse-like capabilities, such as ACID transactions, schema evolution, and time travel, directly to data lakes stored in object storage.
BigLake: A unified storage engine providing native implementation for Apache Iceberg on Cloud Storage. It simplifies data management and integrates with Dataplex Universal Catalog for unified governance.
BigQuery: Google's autonomous data-to-AI platform, central to the managed Data Lakehouse, supporting advanced analytics, streaming, and AI/ML workloads directly on Iceberg tables.
Cloud Storage: The highly scalable and durable object storage service that forms the cost-effective foundation for storing Iceberg data files and metadata.
Dataplex Universal Catalog: An AI-powered catalog that centralizes business, technical, and operational metadata for all data and AI services on Google Cloud, supporting open table formats like Apache Iceberg and BigLake tables for integrated governance.
3.3 Advantages and Benefits
The Data Lakehouse architecture offers several compelling advantages. A primary benefit is a simplified architecture. By removing the silos of separate data lake and data warehouse platforms, a Data Lakehouse streamlines the overall data architecture, reducing the overhead associated with managing and maintaining multiple distinct repositories. Tools and applications can connect directly to source data within the lakehouse, which simplifies data pipelines and reduces the need for extensive Extract, Transform, Load (ETL) processes.
This architecture also enables better data quality and consistency. Data Lakehouse architectures allow for schema enforcement for structured data and robust data integrity, thereby ensuring consistency across datasets. This also reduces the time required to make new data available for analysis, leading to fresher and more reliable data. The inclusion of ACID (Atomicity, Consistency, Isolation, Durability) compliance further ensures reliable transactions, a feature traditionally limited to data warehouses.
From a financial perspective, Data Lakehouses can lead to lower costs. By leveraging low-cost cloud object storage for vast volumes of data, they eliminate the need to maintain both a data warehouse and a data lake, significantly reducing infrastructure and ETL process costs. This architectural consolidation also contributes to increased reliability. By minimizing ETL data transfers between multiple systems, Data Lakehouses reduce the chance of quality or technical issues that can arise from data movement, resulting in more stable and trustworthy data pipelines.
The consolidation of data and resources into a single platform results in improved data governance and security. This unified approach makes it significantly easier to implement, test, and enforce comprehensive data governance and security controls across the entire data estate. Furthermore, a Data Lakehouse helps achieve a reduced data duplication by striving for a single source of truth for data. This prevents inconsistencies and avoids extra storage costs often incurred by redundant data copies spread across disparate systems.
The architecture supports a diverse range of workloads from a single repository, including traditional analytics, SQL queries, machine learning, and data science, allowing multiple tools to connect directly. Finally, the decoupled compute and storage model inherent in Data Lakehouses enables high scalability, providing nearly limitless and instantaneous scalability. Organizations can scale computing power and storage independently based on evolving business needs, ensuring adaptability to fluctuating demands.
3.4 Challenges and Considerations
Despite its compelling advantages, the Data Lakehouse architecture is not without its challenges. As a relatively new and evolving technology, there can be uncertainty regarding its long-term maturity. Organizations may find it difficult to determine whether a Data Lakehouse will fully meet long-term expectations and deliver on all its promises when compared to more mature data storage solutions.
While offering simplified operations once established, building a Data Lakehouse from scratch can be complex and challenging. It often requires starting with a platform specifically designed to support its open architecture, necessitating thorough research into platform implementations and capabilities before procurement. Although designed to handle all data formats, some Data Lakehouse implementations may still face potential incompatibility with certain highly unstructured or complex semi-structured data types (e.g., video, audio) that a pure data lake might handle more fluidly.
Despite leveraging low-cost storage, the operational maintenance costs of a Data Lakehouse can be significant, akin to those of a data warehouse, depending on the scale and complexity of the implementation. For
sensitive data handling, the Data Lakehouse's ability to accommodate every data format can make it challenging to enforce uniform data security and reliability policies for highly sensitive data types, potentially rendering it less ideal for certain highly regulated datasets without meticulous management. Furthermore, it is observed that no single Data Lakehouse tool currently available is universally capable of serving all diverse job functions within an enterprise organization at the required capacity and performance levels.
The emphasis on the Data Lakehouse's reliance on open-source technologies like Delta Lake, Apache Iceberg, Spark, Hadoop, and Hive highlights what can be considered an "openness paradox." While this "openness" is presented as a significant benefit, offering flexibility and mitigating vendor lock-in, it frequently introduces a substantial overhead in terms of integration, orchestration, and ongoing management. The observation that a Lakehouse can be "hard to build from scratch" and requires "research every platform's implementations and capabilities" , along with the reiteration of "complexity to build from the ground up" , underscores this point. Organizations gain freedom from proprietary lock-in but simultaneously inherit the responsibility of assembling and maintaining a complex ecosystem of diverse components. This often necessitates a highly skilled data engineering team and robust internal capabilities, potentially masking the perceived simplicity of a "unified platform" with underlying architectural and operational complexities.
3.5 Leading Technologies and Vendors
The Data Lakehouse market is spearheaded by several prominent vendors and technologies that have significantly contributed to its development and adoption:
Databricks Delta Lake: Widely recognized as a pioneer of the modern Data Lakehouse architecture, Databricks' Delta Lake provides crucial features such as ACID transactions, schema enforcement, and unified batch/streaming capabilities directly on data lakes, bringing data warehouse reliability to data lake flexibility.
Snowflake: While primarily known as a cloud-based data warehousing platform, Snowflake has evolved to support extensive data lake capabilities, effectively bridging the gap between lakes and warehouses and offering a scalable, high-performance solution for raw data storage.
Amazon S3 and AWS Lake Formation: Amazon S3 serves as a foundational, highly available, and low-latency storage platform for building data lakes. AWS Lake Formation adds comprehensive data lake solution capabilities, including governance and security features, transforming basic object storage into a more managed data environment.
Google Cloud Platform and BigLake: Google Cloud Storage forms the basis for data lakes within the Google Cloud ecosystem. It is complemented by BigLake, a unified interface for accessing data across various storage systems, including integration with BigQuery for powerful analytics.
Azure Data Lake Storage (ADLS): Microsoft Azure's offering, ADLS, is a prominent data lake vendor, particularly compelling for businesses already utilizing or considering Azure services. It forms the storage foundation for Lakehouse architectures within the Azure ecosystem.
Other significant players in the Data Lakehouse landscape include Starburst Data Lakehouse, which excels in analytics and interactive querying ; Dremio Lakehouse Platform, known for accelerating query performance through its Apache Arrow-based engine ; Cloudera Data Platform (CDP), built on open-source technologies like Hadoop, Spark, and Hive ; Teradata VantageCloud Lake, a next-generation cloud-native platform for analytics and lakehouse workloads ; Oracle Cloud Infrastructure; and Vertica Unified Analytics Platform.
Data Fabric vs. Data Lakehouse: A Comparative Analysis
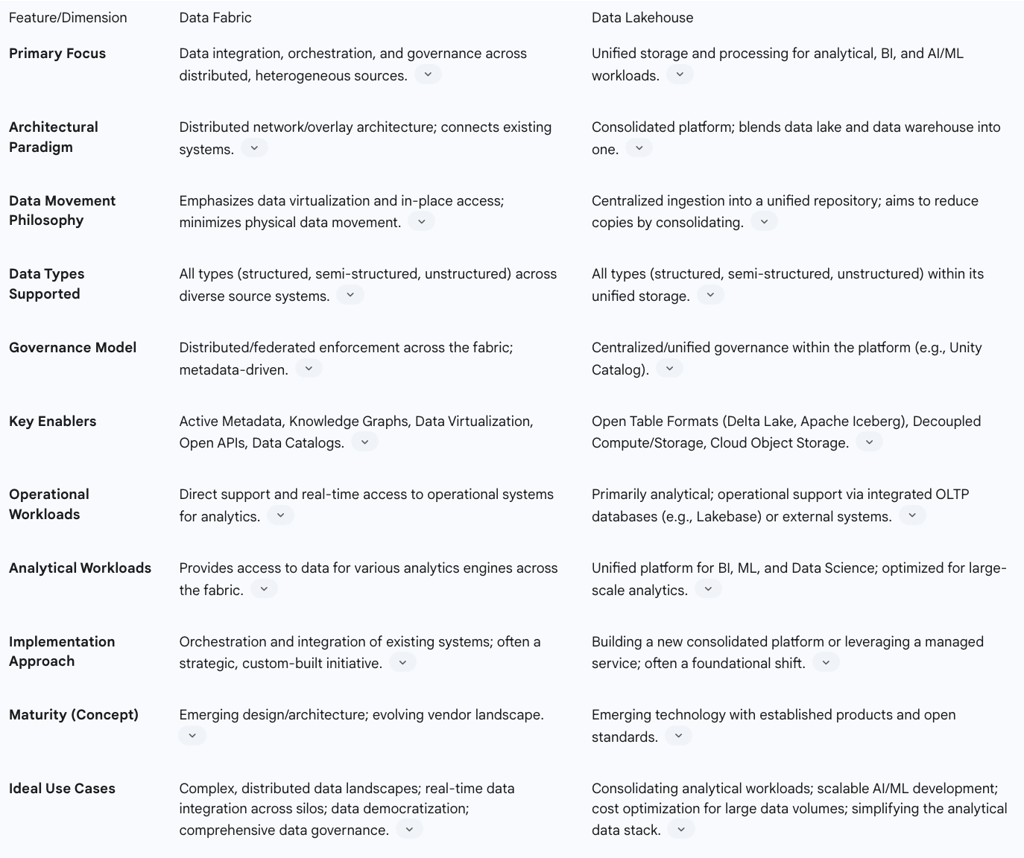
4.1 Architectural Paradigms
The fundamental distinction between Data Fabric and Data Lakehouse lies in their architectural paradigms and primary objectives. A Data Fabric is fundamentally an architectural design or approach rather than a single product or technology. Its core focus is on integrating and governing data across a highly distributed and heterogeneous landscape of existing data sources. It aims to connect these diverse systems, often providing a unified view without necessarily requiring physical data movement, primarily through capabilities like data virtualization. This approach represents an evolutionary path for organizations, building upon and enhancing existing infrastructure.
In contrast, a Data Lakehouse is defined as a unified data platform that combines the strengths of data lakes and data warehouses into a single, consolidated repository. It typically implies a consolidation or the building of a new, central analytical hub. It is often described as a new technology that provides a specific architectural pattern for managing data, particularly for analytical and AI/ML workloads.
4.2 Data Integration and Access
Data Fabric excels in providing advanced data integration features, enabling instantaneous or near-instantaneous integration from highly diverse and distributed sources. It offers unified data access through a single, integrated data layer that spans different environments, simplifying data consumption. A key capability is its emphasis on accessing data without extensive physical movement, often through data virtualization, and its support for live data ingestion with in-flight transformation to deliver real-time insights.
The Data Lakehouse focuses on efficiently ingesting large volumes of data into a centralized repository, supporting both batch and streaming methods. A core objective of the Data Lakehouse is to minimize data copies and movement by unifying storage and processing within its single platform. Tools and applications connect directly to the source data within the lakehouse, which streamlines data pipelines and reduces the need for complex, multi-stage ETL processes.
4.3 Data Governance and Security
Data Fabric is designed to establish and enforce consistent data governance policies across all integrated data sources. Security and governance policies are applied and enforced throughout the data fabric wherever data travels or is accessed, often in real-time, ensuring a pervasive security posture. However, its distributed nature, if not properly managed, can introduce new security risks or challenges in ensuring uniform compliance across highly varied environments.
The Data Lakehouse offers centralized data and AI governance (e.g., Databricks Unity Catalog) for data, analytics, and AI assets on its unified platform. By consolidating data and resources in one place, it aims to simplify the implementation, testing, and delivery of comprehensive governance and security controls, making it easier to manage compliance and access policies.
4.4 Analytics and AI/ML Workload Support
Data Fabric supports a broad spectrum of workloads, explicitly designed for both operational and analytical use cases. It enables the generation of real-time insights and supports immediate decision-making by making data readily available from diverse operational systems. Analytics capabilities can be exposed as REST APIs within the fabric for consumption by transactional systems, blurring the lines between operational and analytical data use.
The Data Lakehouse is specifically engineered to enable advanced machine learning, business intelligence, and predictive analytics on all types of data—structured, semi-structured, and unstructured. It unifies data warehousing and AI use cases onto a single platform and provides specialized ML runtimes and robust MLOps workflows, making it a powerful environment for data science and AI development.
4.5 Implementation Complexity and Cost
Implementing a Data Fabric is characterized by high inherent complexity and significant upfront costs. It is not an off-the-shelf product but rather a custom-built solution, requiring substantial expertise, resources, and often a degree of organizational and cultural transformation to succeed.
A Data Lakehouse can also be challenging to build from scratch, frequently necessitating the adoption of a platform specifically designed to support its open architecture. While designed to be cost-effective in the long run by leveraging low-cost storage, the initial setup and ongoing maintenance costs can still be considerable, depending on the scale and complexity of the implementation.
The architectural differences between Data Fabric and Data Lakehouse can be understood through the analogy of a "control plane" versus a "data plane." Data Fabric is consistently described as an "architecture" that "stitches together integrated data" , provides "unified data access" , and enforces "governance throughout". This suggests a primary focus on the management and orchestration of data across an enterprise. Data Fabric acts as a "control plane" for an organization's entire data estate, focusing on metadata, governance, discovery, and orchestration across distributed data sources. It does not necessarily dictate where data resides but rather how it is accessed, integrated, and governed.
Conversely, a Data Lakehouse is presented as a "single platform" that "blends a data lake and data warehouse" , providing "low-cost, flexible storage" and "unified governance". This indicates a primary focus on the
storage and processing of data. A Data Lakehouse is more akin to a consolidated, optimized "data plane" specifically designed for analytical and AI workloads, providing a unified environment for data storage and processing. This conceptual distinction helps clarify their distinct, yet potentially complementary, roles within a larger enterprise data strategy.
4.6 Comprehensive Comparison Table
Synergy and Coexistence: A Hybrid Approach
5.1 Integration Patterns and Use Cases
A crucial observation from the research is that Data Fabric and Data Lakehouse are not mutually exclusive; instead, they are highly complementary and can effectively co-exist within an organization's broader data ecosystem. This perspective shifts the conversation from an "either/or" choice to a "how to combine" strategy, recognizing that each architecture addresses different, yet interconnected, aspects of enterprise data management.
In a hybrid model, a Data Fabric can serve as an overarching orchestration and governance layer. It can manage and integrate data from a Data Lakehouse, treating it as one of many data nodes within a larger, distributed data landscape. This means the Data Fabric can oversee the Data Lakehouse, which functions as a scalable foundation for raw data storage and analytical processing, providing the necessary integration, governance, and real-time processing capabilities across the entire data estate.
Microsoft's "Fabric" platform provides a compelling real-world illustration of this synergy. It is presented as a data fabric solution that inherently standardizes on the Delta Lake format, a core component of Lakehouse architecture. This unification of the data store allows for the elimination of traditional data silos, significant reduction in data duplication, and a drastic decrease in total cost of ownership (TCO). Within Microsoft Fabric, organizations can implement Lakehouse architectures, often leveraging the Medallion Architecture (Bronze, Silver, Gold zones) for structured data refinement within OneLake (Fabric's data lake).
IBM explicitly supports the idea that enterprises can embrace both concepts. They suggest adopting a Data Lakehouse as part of a platform evolution, for example, by replacing an older data warehouse to unify business intelligence (BI) and AI use cases. Concurrently, a Data Fabric can be adopted to address broader data complexity across multiple platforms, with Data Lakehouse nodes seamlessly participating within this fabric network.
A real-world use case example illustrates this combined approach: a global logistics company utilizes a Data Fabric to integrate data from diverse sources, including on-premises systems, AWS, and Google Cloud Platform. This involves querying customer and shipment data stored in AWS S3 directly using Google's BigQuery Omni, ingesting IoT sensor data from warehouses into Google Cloud Storage via Data Fusion, and then governing all this data with Dataplex and Data Catalog. This scenario demonstrates how a Data Fabric can span multiple cloud environments and integrate with underlying lakehouse-like components (Cloud Storage, BigQuery) to provide a unified view for end-to-end supply chain performance analysis without extensive data migration.
The consistent emphasis on coexistence and concrete vendor examples like Microsoft Fabric and IBM's combined strategy strongly indicate a strategic shift from an "either/or" decision to an "and" approach. This suggests that neither architecture alone is the panacea for all enterprise data challenges. The most sophisticated and resilient enterprise data strategies will likely involve building a cohesive "platform of platforms." In this model, specialized data systems, such as Data Lakehouses optimized for scalable analytical processing and AI/ML workloads, are seamlessly integrated and governed by an overarching Data Fabric. This layered approach allows organizations to leverage the unique strengths of each paradigm: the Data Fabric provides the meta-layer of intelligent connectivity, discovery, and unified governance across the entire distributed data estate, while Data Lakehouses provide the performant, scalable data processing and storage foundation for specific analytical domains or business units. This strategy effectively addresses both the need for centralized, high-performance analytics and the imperative of integrating and governing data across a complex, fragmented landscape.
5.2 When to Choose One, Both, or a Hybrid
The decision to implement a Data Fabric, a Data Lakehouse, or a hybrid approach depends on an organization's specific data management requirements, existing infrastructure, and strategic objectives.
Choose Data Fabric if:
Your organization requires real-time or near-real-time data integration across a highly distributed and heterogeneous landscape of data sources.
You need unified access to a wider range of data without necessarily centralizing all physical data, often leveraging data virtualization to achieve this.
Your primary objective is to centralize and automate data governance, quality, and security policies across disparate systems, providing a consistent control layer.
You aim to "democratize" data, making it readily available and discoverable to a broader range of business users beyond specialized data professionals.
Your organization is struggling with significant data silos and requires a holistic, integrated view of its information assets to improve decision-making.
Choose Data Lakehouse if:
Your primary goal is to consolidate vast amounts of raw, structured, semi-structured, and unstructured data into a single, cost-effective repository for advanced analytics, AI, and ML initiatives.
You require a unified platform that combines the benefits of traditional data lakes (flexibility, raw data storage) and data warehouses (ACID transactions, schema enforcement, reliability).
You are looking to simplify your analytical data stack and reduce the operational overhead of maintaining separate data lake and data warehouse environments.
Your organization's core focus is on building and scaling data science and machine learning workflows efficiently, requiring a robust and performant platform for these specific workloads.
Consider a Hybrid Approach (Data Fabric + Data Lakehouse) if:
You possess vast amounts of raw data that require scalable storage and advanced analytical processing for future exploration (a strong case for a Lakehouse) and you simultaneously need to integrate and govern data from diverse, distributed, and potentially legacy sources across your enterprise (a strong case for a Fabric).
Your aim is to achieve holistic data management, where the Data Lakehouse serves as a robust, scalable storage and processing foundation for analytical data, and the Data Fabric provides seamless data access, integration, and real-time processing capabilities across your entire, heterogeneous data estate.
Your organization operates in a complex, multi-cloud, or hybrid environment with existing data assets that cannot be easily migrated or centralized into a single platform.
You need to support both centralized, high-performance analytical processing (e.g., for enterprise BI and AI models) and distributed, real-time operational data access with consistent governance and security across all data assets.
Strategic Recommendations and Future Outlook
6.1 Strategic Recommendations for Adoption
For organizations considering the adoption of Data Fabric, Data Lakehouse, or a hybrid strategy, several strategic recommendations are paramount for successful implementation:
Assess Organizational Maturity: A critical evaluation of the organization's existing data governance practices, metadata management capabilities, and the technical skill sets of its data teams is essential. A strong foundation in these areas is crucial for successful implementation, particularly for the complex orchestration required by a Data Fabric. Without this foundational maturity, even the most advanced architectural designs may struggle to deliver their promised value.
Define Clear Use Cases: It is imperative to avoid adopting these architectures merely for the sake of technology. Instead, organizations should identify specific, high-value business problems that each architecture is best suited to solve. For instance, a Data Fabric might be ideal for creating a real-time customer 360-degree view by integrating disparate CRM and ERP systems, while a Data Lakehouse could effectively power predictive maintenance models using high-volume sensor data and historical operational logs.
Start Small, Scale Incrementally: To mitigate risk and build internal expertise, it is advisable to begin with a manageable scope. For a Data Fabric, this could involve a critical data domain or a specific, high-impact integration challenge. For a Data Lakehouse, initiating with a focused analytical workload or a manageable dataset allows for proving value in smaller, controlled environments, which builds momentum and expertise for broader adoption.
Prioritize Metadata Strategy: Regardless of the chosen architecture, investing heavily in active metadata management and a robust, augmented data catalog is non-negotiable. As highlighted by Gartner for Data Fabric, metadata is the "framework" and "cornerstone" of effective data management. For a Data Lakehouse, metadata layers are what enable data warehouse-like features. This foundational element is the common thread for success across all modern data initiatives, enabling discoverability, governance, and trust in data assets.
Embrace Open Standards: Leveraging open table formats (such as Delta Lake and Apache Iceberg) and adhering to open APIs is a strategic imperative. This approach provides flexibility, significantly reduces the risk of vendor lock-in, and fosters a more interoperable data ecosystem, empowering organizations to choose the best tools and components for their specific needs without being constrained by proprietary systems.
Foster Cross-Functional Collaboration: The successful implementation of complex data architectures requires close collaboration and sustained buy-in across diverse teams. This includes data engineering, data science, business intelligence, data governance, and crucially, direct engagement from business stakeholders. This collaborative approach ensures that technical solutions are not only robust but also align directly with business needs, and that data is truly democratized and utilized across the organization to drive value.
6.2 Future Outlook
The trajectory of modern data architectures points towards continued evolution and convergence. The distinct lines between traditional data lakes, data warehouses, and operational databases are expected to blur even further. The Data Lakehouse is a prime example of this trend, and future architectures will likely see even deeper integration, leading to more unified and intelligent data platforms capable of seamlessly handling diverse workloads, from transactional to advanced analytical.
A significant trend will be the increasing reliance on AI-driven automation to manage complex data tasks. This includes capabilities such as automated data discovery, intelligent data integration, continuous data quality monitoring, and adaptive governance enforcement. This progression aligns with Gartner's "self-driving" vision for Data Fabric, where machine learning autonomously manages data, dramatically improving efficiency and reducing manual effort.
While conceptually distinct from Data Fabric and Data Lakehouse, the principles of Data Mesh (such as domain ownership, treating data as a product, and self-serve data platforms) will continue to influence how these architectures are implemented and organized within large enterprises. This influence will likely manifest in fostering decentralized accountability for data quality and discoverability, promoting a product-oriented mindset for data assets, and enabling more agile data delivery within specific business domains.
Finally, the dominance of cloud-native solutions will persist and strengthen. Cloud providers will continue to evolve and offer comprehensive, integrated solutions that inherently combine aspects of both Data Fabric and Data Lakehouse. These managed services will simplify deployment, reduce operational overhead, and accelerate time-to-value for organizations embracing cloud-first data strategies, making sophisticated data architectures more accessible and manageable. The future of enterprise data management lies in intelligent, adaptable, and highly integrated architectures that can meet the ever-growing demands for real-time insights and advanced analytical capabilities.