Deepseek R1 vs Deepseek V3.1
Among the leading contenders in this space are DeepSeek R1 and DeepSeek V3.1, two powerful models that have garnered significant attention for their capabilities and performance.
The evolution from DeepSeek R1 to DeepSeek V3.1 represents a significant strategic pivot by DeepSeek AI, moving from a specialized, research-driven model focused on elite reasoning to a unified, market-ready hybrid platform engineered for versatility, efficiency, and economic disruption. DeepSeek R1 established a new frontier in open-source AI, demonstrating that complex reasoning capabilities, once the domain of closed-source leaders, could be unlocked through innovative, large-scale Reinforcement Learning (RL) techniques. It was a testament to methodological prowess.
DeepSeek V3.1, in contrast, is the productization of that prowess. Built upon the same powerful Mixture-of-Experts (MoE) foundation, V3.1 integrates R1's reasoning capabilities as a faster, more efficient, and user-selectable "Thinking" mode within a single, unified architecture. This consolidation addresses the operational friction of maintaining separate models and streamlines the developer experience.
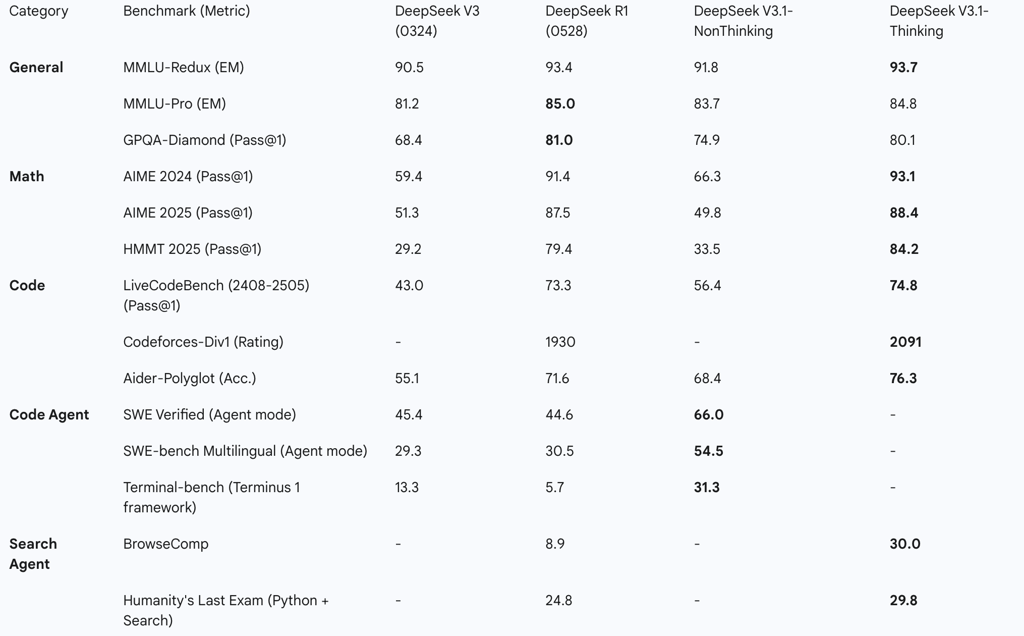
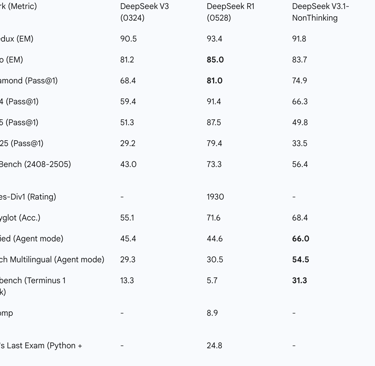
The key differentiators marking this evolution are stark. V3.1 doubles the context window to a massive 128K tokens, enabling a new class of long-form analysis tasks. It demonstrates not just comparable, but in many cases superior, performance on the very math and coding benchmarks that were R1's signature strengths. Most critically, V3.1 introduces a dramatic leap in agentic capabilities—excelling at tool use, web browsing, and code execution tasks where R1 was comparatively weak.
This entire package is delivered with a unified API and a pricing structure that strategically lowers the cost of advanced reasoning, encouraging the adoption of its hybrid paradigm. The analysis indicates that DeepSeek is leveraging a tripartite strategy—open-source accessibility, elite performance, and radical cost-efficiency—to challenge established market leaders. Furthermore, the model's deep optimizations for low-precision FP8 computation signal a deliberate, software-led approach to building a technologically sovereign AI ecosystem, mitigating reliance on foreign hardware and charting a new course for AI development. DeepSeek V3.1 is not merely an upgrade; it is the maturation of a research breakthrough into a formidable and disruptive commercial platform.
Foundational Architecture: A Mixture-of-Experts (MoE)
The architectural lineage of both DeepSeek R1 and DeepSeek V3.1 traces back to a common, highly advanced progenitor. This shared foundation is key to understanding their capabilities, as their primary differences arise not from fundamental structural divergence but from specialized post-training and refinement.
2.1 The Common Progenitor: DeepSeek-V3-Base
Both R1 and V3.1 are post-trained evolutions of the DeepSeek-V3-Base model, a formidable Transformer-based, decoder-only architecture. The defining characteristic of this base model is its sophisticated Mixture-of-Experts (MoE) framework, which is engineered to balance massive scale with computational efficiency.
Mixture-of-Experts (MoE) Framework: The V3-Base model contains a total of 671 billion parameters, a scale that places it among the largest models in the world. Some sources cite a total size of 685B parameters, which includes an additional 14B-parameter Multi-Token Prediction (MTP) module designed to accelerate inference. The critical innovation of the MoE design is its sparse activation. For any given input token, the model's routing mechanism activates only
37 billion parameters—approximately 5.5% of the total. This allows the model to possess a vast repository of knowledge and specialized "experts" while keeping the computational cost of inference comparable to a much smaller dense model, a core tenet of DeepSeek's efficiency-first philosophy.
Architectural Innovations: The V3-Base architecture inherits and refines several key technologies from previous DeepSeek models to maximize performance and efficiency:
Multi-head Latent Attention (MLA): An advanced attention mechanism that moves beyond simple token-to-token comparisons. MLA allows the model to focus on more abstract, latent representations of meaning within its hidden states, contributing to more efficient and effective inference.
DeepSeekMoE: The specific MoE implementation includes a pioneering auxiliary-loss-free strategy for load balancing. In many MoE models, an auxiliary loss function is required to ensure that input tokens are distributed evenly across the different experts, preventing a few experts from becoming over-utilized while others are idle. However, this auxiliary loss can sometimes degrade overall model performance. DeepSeek's approach achieves balanced expert utilization without this trade-off, preserving the model's full capabilities.
This "common chassis" strategy is a cornerstone of DeepSeek's development model. The enormous computational expense of pre-training a model of this scale (the V3 base model required 2.664 million H800 GPU hours) is treated as a foundational investment. From this single, powerful asset, specialized models like R1 and V3.1 can be developed through comparatively less expensive post-training phases. This maximizes the return on the initial pre-training cost and enables rapid iteration and product diversification. The core difference between the models, therefore, lies less in their "hardware" (the architecture) and more in their "software" (the training they receive).
2.2 Divergence in Context Length: A Generational Leap
While sharing a common architectural core, a primary point of divergence between R1 and V3.1 is the context window—the amount of information the model can process at once.
DeepSeek R1: This model was released with a 64K token context window. At the time of its release, this was a substantial capacity, sufficient for a wide range of complex, multi-step reasoning problems.
DeepSeek V3.1: This model features a 128K token context window, doubling the capacity of its predecessor. This expansion is not merely an incremental update but a fundamental enhancement of the model's capabilities.
This leap to a 128K context window positions V3.1 as a next-generation tool aimed squarely at high-value enterprise and research use cases that were previously challenging. The ability to process the equivalent of a full-length novel or an entire research report in a single pass unlocks applications in whole-book comprehension, comprehensive legal document analysis, and large-scale codebase refactoring. This makes V3.1 not just a more efficient reasoner than R1, but a fundamentally more capable model for a different and more demanding class of problems, justifying its role as a successor.
Table 1: Architectural Specification Comparison