Deepseek v3.1 An Architectural and Competitive Analysis
Positioned not as a groundbreaking successor but as a potent optimization of the existing Deepseek V3 architecture, v3.1 introduces a series of targeted enhancements aimed at improving performance, reliability, and user experience. This release is a calculated move by its parent company, DeepSeek AI.


The large language model (LLM) landscape is characterized by rapid, often revolutionary, advancements. Against this backdrop, the release of Deepseek v3.1 on August 19, 2025, represents a more nuanced, yet strategically significant, development. Positioned not as a groundbreaking successor but as a potent optimization of the existing Deepseek V3 architecture, v3.1 introduces a series of targeted enhancements aimed at improving performance, reliability, and user experience. This release is a calculated move by its parent company, DeepSeek AI, to consolidate its product offering and sharpen its competitive edge while development continues on its highly anticipated next-generation reasoning model, Deepseek-R2.
Deconstructing the v3.1 Release: An Optimization, Not a Revolution
The official announcement framed Deepseek v3.1 as an upgrade to the online model available through the company's official website, application, and API, explicitly stating it is an "optimization of the V3 model" rather than a major version iteration. This deliberate framing serves to manage market expectations, particularly as anticipation for the successor to the acclaimed Deepseek-R1 reasoning model remains high. The rollout strategy, which prioritized communication through channels like the official WeChat group over immediate, comprehensive documentation on platforms such as Hugging Face, suggests a product-centric approach focused on rapid deployment to its existing user base. This contrasts with a purely academic or open-source release, signaling a focus on capturing and retaining users within its ecosystem.
Headline Enhancements: Context, Reasoning, and Reliability
The v3.1 update is built upon three pillars of improvement, each addressing a critical aspect of LLM performance:
Expanded Context Length: The most significant advertised enhancement is the extension of the model's context window to 128,000 tokens. This capacity, equivalent to processing 100,000 to 130,000 Chinese characters, makes the model exceptionally well-suited for tasks involving the analysis of long documents, comprehension of extensive codebases, and maintaining coherence in multi-turn conversational scenarios.
Improved Reasoning Performance: Internal evaluations indicate a substantial 43% improvement in multi-step reasoning tasks compared to its direct predecessor. This enhancement is particularly evident in complex domains such as mathematical calculations, scientific analysis, and sophisticated code generation, where the model demonstrates higher accuracy.
Enhanced Reliability: A key focus of the optimization was to increase the model's factuality and reduce the prevalence of "hallucinations," or the generation of false information. The update achieves a reported 38% decrease in such occurrences, significantly bolstering the reliability and trustworthiness of its outputs.
Additionally, the update brings optimized multilingual support, with a particular focus on improving processing capabilities for Asian and minority languages, broadening its global applicability.
Navigating the Deepseek Model Family: Clarifying v3.1's Position
The nomenclature of Deepseek's models requires clarification to understand v3.1's strategic role. The name "v3.1" refers to the updated online model accessible through Deepseek's proprietary platforms. The underlying open-source base model that powers this service is the DeepSeek-V3-0324 checkpoint, which shares the same core specifications and performance characteristics. The official API endpoint designated as deepseek-chat directs requests to this specific version, solidifying the link between the online product and its open-source foundation.
Community analysis and observations of the user interface suggest that v3.1 represents a strategic consolidation of Deepseek's previous chat and reasoner models into a single, unified offering. The removal of the "r1" indicator from the "think" button in the official chat interface is a key piece of evidence supporting the conclusion that v3.1 is a "mixed reasoning model". This move to a unified model is not merely a technical adjustment but a significant product decision. It mirrors a broader industry trend toward creating versatile, "do-it-all" systems, as seen with OpenAI's GPT-5 and Anthropic's Claude 4.1, which dynamically allocate computational resources based on the complexity of a user's query.
This consolidation simplifies the product for a wider audience but introduces a critical trade-off. While the specialized Deepseek-R1 series was renowned for its profound, deep chain-of-thought reasoning, early user reports for the hybrid v3.1 have been notably critical, with many power users citing a significant decline in reasoning quality compared to the dedicated R1 model. This suggests that in creating a general-purpose model, some of the peak performance in specialized areas may have been compromised. This tension between specialized excellence and general-purpose utility is a defining characteristic of the current LLM landscape, indicating a strategic prioritization of market accessibility over maintaining absolute state-of-the-art performance in a niche capability.


Architectural Deep Dive: The Engineering of a Cost-Efficient Powerhouse
The performance and market positioning of Deepseek v3.1 are not accidental; they are the direct outcomes of a series of deliberate and innovative architectural choices. The model's design philosophy prioritizes computational efficiency without sacrificing frontier-level capabilities, allowing it to challenge more resource-intensive models. This section deconstructs the key technical innovations that define the Deepseek-V3 architecture.
The Mixture-of-Experts (MoE) Paradigm: Scaling Intelligence, Not Compute
At its core, Deepseek-V3 is built upon a sparse Mixture-of-Experts (MoE) architecture. This is the model's defining characteristic and the primary driver of its efficiency. The model contains a massive repository of knowledge, represented by 671 billion total parameters. However, unlike traditional "dense" models that must activate every parameter to process a single token, Deepseek-V3's sparse design activates only a small fraction—approximately 37 billion, or 5.5%—for any given token.
This is accomplished by replacing the standard feed-forward network (FFN) layers of the Transformer architecture with MoE layers. Each MoE layer contains a large number of smaller, specialized FFNs, known as "experts," and a "gating network" that dynamically routes each input token to the most relevant experts for processing. The Deepseek-V3 architecture features MoE layers with 1 shared expert and 256 routed experts, of which only 8 are activated per token. This conditional computation allows the model to scale its knowledge base to hundreds of billions of parameters while keeping the computational cost of inference comparable to a much smaller dense model.
Core Innovations: MLA, MTP, and Load Balancing
Beyond the foundational MoE design, Deepseek-V3 incorporates several proprietary innovations to further enhance performance and efficiency:
Multi-Head Latent Attention (MLA): Inherited and refined from Deepseek-V2, MLA is an advanced attention mechanism designed for efficiency. It employs low-rank factorization to compress the Key (K) and Value (V) matrices, which are central to the self-attention calculation. This compression significantly reduces memory bandwidth requirements and computational load, a critical optimization for enabling the model's large 128K context window. The V3 implementation further enhances MLA with more stable Rotary Positional Encoding (RoPE) handling, joint storage for compressed K and V matrices, and a layer-wise adaptive cache that prunes older entries in deeper layers to manage memory during long-context processing.
Multi-Token Prediction (MTP): Deepseek-V3 pioneers a novel training objective where the model is trained to predict multiple future tokens simultaneously, rather than just the single next token. This approach has been empirically shown to improve the model's overall performance on evaluation benchmarks. Furthermore, the MTP mechanism can be leveraged during inference to enable speculative decoding, a technique that accelerates generation speed by drafting several tokens in parallel and then verifying them in a single step. The open-source model release includes a dedicated 14-billion-parameter MTP module for this purpose.
Auxiliary-Loss-Free Load Balancing: A persistent challenge in MoE models is ensuring that the workload is distributed evenly across all experts, preventing a scenario where a few experts become over-utilized while others remain dormant. The conventional solution involves adding an "auxiliary loss" term to the training objective to penalize imbalanced routing. However, this can degrade the model's primary performance. Deepseek-V3 introduces a novel load-balancing strategy that functions without this auxiliary loss, allowing for a more natural and efficient distribution of work across experts while minimizing any negative impact on model accuracy.
Training at Scale: The Role of FP8 Precision and a 14.8T Token Corpus
The efficiency of the Deepseek-V3 architecture is matched by an equally efficient training methodology. This synergy of hardware-software co-design is a cornerstone of the project's success.
FP8 Mixed Precision Training: Deepseek-V3 is one of the first models at its scale to be successfully trained using FP8 (8-bit floating point) mixed precision. Standard training typically uses 16-bit or 32-bit precision. By reducing the numerical precision to 8 bits, the model's memory footprint for weights and activations is dramatically reduced—by up to 75% compared to 32-bit precision. This allows for the use of larger batch sizes and significantly accelerates the training process, directly contributing to lower training costs.
Training Data and Process: The model was pre-trained on an exceptionally large and diverse dataset comprising 14.8 trillion high-quality tokens. This corpus was carefully curated to include a rich mixture of text, code, mathematical data, and multilingual content, forming the foundation of the model's broad knowledge base. The entire pre-training process required only 2.788 million NVIDIA H800 GPU hours and was remarkably stable, proceeding without any irrecoverable loss spikes or the need for rollbacks—a testament to the robustness of the architecture and training framework.
The causal chain linking these technical decisions to market strategy is clear and direct. The foundational choice of a sparse MoE architecture, enhanced by MLA and MTP, fundamentally reduces the computational cost per token. This architectural efficiency is then amplified by a highly optimized training process using FP8 precision, which drastically cuts the time, hardware, and capital required to build the model—with an estimated training cost of around $6 million, an order of magnitude less than competitors. This low capital and operational expenditure directly enables Deepseek's disruptive pricing strategy, which in turn fuels its market penetration and open-source adoption goals. The entire business model is predicated on these initial, deeply technical engineering choices.
Achieving a 128K Context Window: YaRN and Memory Optimization
The model's ability to handle a 128K token context window is a key feature that is enabled by several specialized techniques. The primary method is the use of YaRN (Yet another RopeNet), a positional encoding interpolation technique that allows a model pre-trained on a shorter context (4K tokens in this case) to be extended to a much longer one without catastrophic performance degradation. This is far more efficient than training the model on a 128K context from scratch. This is complemented by the aforementioned MLA and other memory optimization techniques, such as Flash Attention for faster matrix operations and a Key-Value (KV) cache compression approach, which reduces the VRAM required to store the states of past tokens during long-context generation.


Performance Analysis: Quantitative Benchmarks and Qualitative Assessments
A comprehensive evaluation of Deepseek v3.1 requires a dual approach: analyzing its performance on standardized quantitative benchmarks to establish its capabilities relative to the state of the art, and synthesizing qualitative feedback from the user community to understand its real-world utility and limitations. This analysis reveals a model that is a powerhouse in technical domains but whose new, unified nature has created a nuanced and sometimes contentious user experience.
Dominance in Technical Domains: Coding and Mathematics
Deepseek v3.1 exhibits exceptional, state-of-the-art performance in domains requiring logical and symbolic reasoning, particularly mathematics and computer programming.
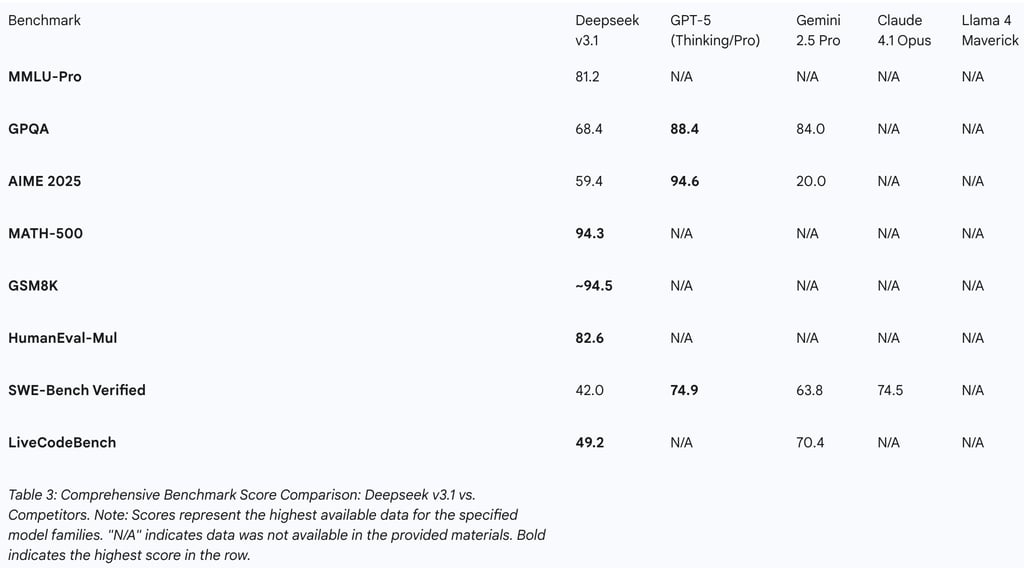
Mathematics: The model's mathematical prowess is one of its most prominent features. It achieves a remarkable 94.3% accuracy on the MATH-500 benchmark and a score of 59.4 on the highly challenging AIME (American Invitational Mathematics Examination) benchmark, representing a nearly 20-point improvement over its predecessor. On the GSM8K benchmark, which consists of grade-school math word problems, its accuracy is reported to be in the range of 90% to 94.5%, placing it among the top-performing models. This demonstrates a robust capability for both numerical calculation and abstract mathematical reasoning.
Coding: The model's performance in code generation is equally impressive. It scores 82.6% on the HumanEval-Mul benchmark, a multilingual code generation test, surpassing strong competitors like GPT-4o and Claude 3.5 Sonnet. On LiveCodeBench, a benchmark that tests performance on competitive programming problems, it achieves a score of 49.2, a significant 10-point gain over the previous version. Its rating on the CodeForces platform is equivalent to that of a human competitive programmer, indicating an ability to solve complex algorithmic challenges. Qualitative reviews from developers corroborate these metrics, praising the model's ability to generate complex, functional, and reliable code from high-level prompts, thereby reducing the need for extensive debugging.
General Reasoning and Language Understanding: MMLU, GPQA, and Beyond
In broader tests of knowledge and reasoning, Deepseek v3.1 remains highly competitive with both open-source and proprietary leaders.
MMLU (Massive Multitask Language Understanding): The model achieves a score of 88.5% on the standard MMLU benchmark, which tests knowledge across 57 academic subjects. This places it on par with leading models like GPT-4o and Llama 3.1. On the more challenging MMLU-Pro benchmark, it scores 81.2, demonstrating strong performance against a more rigorous test of its knowledge base.
GPQA (Graduate-Level Google-Proof Q&A): On this benchmark, which is designed to test PhD-level expert knowledge in science, the model scores 68.4, showcasing a significant improvement over the previous V3 version and a solid capability for deep, domain-specific reasoning.
Chinese NLP: Reflecting its diverse training data and specific optimizations, the model demonstrates dominant performance on Chinese-language benchmarks such as CLUEWSC and C-Eval, often outperforming Western models in understanding the nuances of the language.
The User Experience: Synthesizing Community Feedback
While quantitative benchmarks paint a picture of unequivocal success, qualitative feedback from the model's user base reveals a more complex reality. This feedback highlights a potential gap between performance on structured tests and perceived utility in unstructured, real-world workflows.
Verbosity and "Vibe": A common observation from early users of the v3.1 online interface is that the model has become "very, very verbose" in its responses. Some users also noted a distinct change in the model's conversational style or "vibe" compared to earlier checkpoints like V3-0324. The new version is often described as more "matured" and less "quirky," indicating a shift in its fine-tuning that affects the user's subjective experience.
The Mixed-Reasoning Trade-off: The most significant point of contention among users is the consequence of the shift to a hybrid, mixed-reasoning model. On community platforms like Reddit, a vocal segment of power users who had relied on the specialized Deepseek-R1 model for their most demanding reasoning tasks reported that the quality of v3.1's reasoning had "dropped significantly". This feedback suggests that while the unified model offers greater convenience and strong performance on general benchmarks, it may not achieve the same peaks of logical depth and precision as a model architecture dedicated solely to complex, multi-step reasoning.
This disconnect between stellar benchmark results and mixed user satisfaction highlights the growing limitations of standardized evaluations. Academic benchmarks are crucial for measuring progress on discrete, well-defined problems, but they may not fully capture the nuances of performance in open-ended, multi-turn, and complex workflows where a specialized model like R1 previously excelled. The hybrid architecture of v3.1, while boosting its generalist capabilities and benchmark scores, appears to have done so by averaging out its performance, potentially at the expense of its specialized peak. This indicates that as models become more general-purpose, subjective qualities like "vibe," usability, and performance on unscripted, creative, or deeply logical tasks become increasingly important metrics of true utility, suggesting a potential ongoing market for highly specialized models alongside general-purpose ones.
Competitive Landscape Analysis: Deepseek v3.1 vs. The Titans of AI
Deepseek v3.1 enters a highly competitive market dominated by a few major AI laboratories. Its strategic position can only be understood through a direct, multi-faceted comparison with the flagship models from OpenAI, Google, Anthropic, and Meta. This analysis, grounded in the comprehensive benchmark data presented below, evaluates these models across architecture, performance, and strategic differentiators.
A. Deepseek v3.1 vs. OpenAI's GPT-5 Family
Architectural Contrast: The competition between Deepseek and OpenAI showcases two distinct approaches to achieving computational efficiency. Deepseek employs a static, sparse MoE architecture, where only a fixed fraction of the model's parameters (37B of 671B) are active for any given task. In contrast, GPT-5 utilizes a dynamic, unified system that features a real-time router. This router intelligently directs user queries to one of at least two different models: a highly efficient
gpt-5-main for standard requests and a more powerful, computationally intensive gpt-5-thinking model for complex problems. Both systems aim to match compute to task complexity, but Deepseek's is an inherent property of its architecture, while OpenAI's is a dynamic routing logic layered on top of multiple dense models.
Performance Showdown: On raw performance, GPT-5's frontier models appear to hold an edge in the most advanced reasoning tasks. GPT-5 Pro sets a new state-of-the-art (SOTA) on the GPQA benchmark with a score of 88.4% and on AIME 2025 with an exceptional 94.6%. Deepseek v3.1, while highly capable, scores lower on these specific tests. However, the competition is fierce across the board. Deepseek v3.1 demonstrates superior or highly competitive performance on benchmarks like MATH-500 and LiveCodeBench, and it outperforms GPT-4o on MMLU-Pro and HumanEval. The narrative surrounding GPT-5's release as a "Reverse DeepSeek Moment" suggests that while it is a technically superior model, the perceived leap in capability was less dramatic than Deepseek's perceived leap in cost-efficiency and open-source accessibility.
Strategic Positioning: The two companies occupy different strategic ground. OpenAI competes on delivering the absolute frontier of AI performance, deep multimodality (text, image, audio, video), and seamless integration into a mature enterprise ecosystem via Microsoft Azure and products like GitHub Copilot. Deepseek's strategy is a direct challenge based on cost and openness, offering near-SOTA performance at a fraction of the price, aiming to capture the vast market of developers and businesses for whom cost is a primary constraint.
B. Deepseek v3.1 vs. Google's Gemini 2.5 Pro
Core Philosophy: The comparison with Google's Gemini 2.5 Pro reveals a fundamental clash of design philosophies. Deepseek has pursued depth and specialization, creating a highly optimized, open-source MoE architecture that excels at text- and code-based tasks with unparalleled cost efficiency. Google, on the other hand, has focused on breadth and multimodality. Gemini 2.5 Pro is a proprietary, natively multimodal model designed from the ground up to seamlessly process a wide array of inputs—including text, images, audio, and video—and is built around an advanced "thinking" paradigm that reasons through steps before responding.
Feature Comparison: Gemini's key features highlight this difference in focus. Its standard 1 million token context window significantly surpasses Deepseek's 128K, enabling the analysis of much larger datasets. Gemini's demonstrated ability to generate a playable video game from a single prompt showcases a level of integrated, cross-modal generation that Deepseek's text-focused architecture currently lacks. Conversely, Deepseek's open-source license provides a critical advantage in customizability, transparency, and the ability for local deployment, none of which are possible with the proprietary Gemini model.
Performance: In direct comparisons, Gemini 2.5 Pro demonstrates extremely strong reasoning capabilities, leading on benchmarks like GPQA. Qualitative analysis suggests that Gemini tends to produce cleaner, more readable code, whereas Deepseek is superior at tackling more complex, abstract algorithmic challenges. In a head-to-head test focusing on Retrieval-Augmented Generation (RAG), Deepseek showed a distinct advantage, indicating superior performance in tasks that require retrieving and synthesizing information from provided documents.
C. Deepseek v3.1 vs. Anthropic's Claude 4.1 Opus
The Coding Arena: The duel between Deepseek v3.1 and Claude 4.1 Opus is a direct competition for supremacy in the domain of AI-assisted software engineering. Claude 4.1 Opus achieves a top-tier score of 74.5% on SWE-bench Verified, a benchmark specifically designed to test a model's ability to resolve real-world GitHub issues across multiple files. While Deepseek's coding scores on other benchmarks are excellent, Claude's demonstrated proficiency in complex, enterprise-grade code refactoring appears to be a key differentiator, making it highly attractive for large-scale software development and maintenance.
Architectural Similarities: At a high level, the two models share a similar problem-solving philosophy. Both employ a "hybrid reasoning" architecture that allows the system to dynamically choose between providing a rapid, direct response and engaging in a more deliberate, step-by-step "extended thinking" process. This architectural convergence indicates an industry-wide recognition that a single mode of operation is insufficient for the diverse range of tasks users present.
Safety and Enterprise Focus: A major strategic differentiator for Anthropic is its profound emphasis on AI safety and enterprise-readiness. The company's brand is built around a safety-first approach, with its models undergoing rigorous testing and alignment procedures to achieve high safety compliance levels (e.g., AI Safety Level 3). While Deepseek v3.1 is a reliable and powerful model, Anthropic's dedicated focus and marketing on safety may make Claude 4.1 the preferred choice for risk-averse corporate clients operating in regulated industries.
D. Deepseek v3.1 vs. Meta's Llama 4 Series
Open-Source MoE Showdown: This is the most direct architectural comparison in the current market, pitting two flagship open-source MoE models against each other. Llama 4 Maverick, Meta's high-performance offering, features a similar number of active parameters (~17B) but has a smaller total parameter count (~400B) and fewer experts (128) compared to Deepseek V3's 671B total parameters and 256 experts. This suggests Deepseek has opted for a "sparser" architecture with more, smaller experts.
Multimodality and Context as Differentiators: Meta's Llama 4 possesses two decisive advantages that define its unique position in the open-source landscape. First, it is natively multimodal, designed with an "early fusion" architecture that integrates text and image processing from the very first layer. Second, the Llama 4 Scout variant offers an industry-leading 10 million token context window. These features make the Llama 4 series far more versatile for applications requiring image understanding or the analysis of extremely large volumes of text. Deepseek v3.1, in its current form, is limited to text and code.
Performance: Head-to-head comparisons reveal a clear performance trade-off. For tasks within the text-and-code domain, Deepseek v3.1 is demonstrably superior. Qualitative reviews and tests conclude that Deepseek is "far better" at coding and possesses stronger common-sense reasoning than Llama 4 Maverick. However, Llama 4 Maverick excels at large context retrieval tasks, where its architectural advantage in handling long sequences becomes paramount. This suggests that Deepseek has achieved a higher degree of refinement in its architecture for pure reasoning and code generation, while Meta has prioritized breadth of capability through multimodality and massive context length.
The Developer Ecosystem: API, Pricing, and Accessibility
Beyond raw performance, the success and adoption of a large language model depend heavily on its developer ecosystem—specifically, the ease of integration, cost-effectiveness, and accessibility of its API and models. In these areas, Deepseek has made a series of highly strategic decisions designed to maximize adoption and disrupt the market.
Seamless Integration: The OpenAI-Compatible API
A cornerstone of Deepseek's developer strategy is its API, which is intentionally designed to be a drop-in replacement for OpenAI's widely adopted API standard. Developers can integrate Deepseek's models into their existing applications by using the official OpenAI SDKs in languages like Python or Node.js and simply changing the base_url parameter to point to https://api.deepseek.com.
This approach dramatically lowers the barrier to entry for developers. It eliminates the need to learn a new API structure, rewrite existing code, or invest in new tooling. This near-frictionless migration path is a powerful strategic maneuver aimed directly at capturing market share from developers already invested in the OpenAI ecosystem, encouraging experimentation and making it easy to switch providers for cost or performance reasons. The API supports all standard functionalities expected by developers, including JSON mode for structured output, function calling for tool integration, and streaming responses for real-time applications.
A Paradigm of Affordability: A Detailed Pricing and Cost-Effectiveness Analysis
Deepseek's pricing model is arguably its most disruptive feature and the ultimate expression of its architectural efficiency. The API costs for its flagship models are orders of magnitude lower than those of its main proprietary competitors.
This aggressive pricing is a direct consequence of the model's efficient MoE architecture and FP8 training process, which result in significantly lower operational costs. Compared to OpenAI's GPT-4o, Deepseek v3.1 is approximately 9 times cheaper for comparable tasks. Against older, more expensive models like GPT-4 Turbo, the cost savings can be as high as 200-fold. This economic advantage is not marginal; it is a fundamental shift in the cost structure of accessing frontier AI. Furthermore, Deepseek offers off-peak discounts of 50-75% on its already low prices, further solidifying its position as the most cost-effective solution for high-volume, production-scale AI applications.


Deployment and Accessibility
Deepseek provides multiple avenues for accessing its models, catering to a wide range of users from individual hobbyists to large enterprises.
Cloud API: The most common method of access is through the official Deepseek API or via major cloud and platform partners. Microsoft offers Deepseek-V3 through its Azure AI Foundry, providing an enterprise-grade deployment option. Other platforms like OpenRouter and Together.ai also provide API access, often with their own pricing and feature sets.
Local Deployment: True to its commitment to the open-source community, Deepseek makes the model weights for the DeepSeek-V3-0324 base model publicly available on Hugging Face. This allows well-resourced organizations and academic researchers to deploy the model on their own infrastructure. However, this is a non-trivial undertaking. The model weights require approximately 700 GB of storage, and running the model for inference demands substantial GPU capacity, placing local deployment outside the reach of most individual users and small businesses.
Strategic Outlook and Recommendations
The emergence of Deepseek v3.1 is more than a technical milestone; it is a significant event in the strategic evolution of the global AI landscape. Its combination of near-SOTA performance, radical cost-efficiency, and an open-source ethos presents a formidable challenge to the established order of proprietary, high-cost AI models.
Deepseek's Role in the Global AI Power Struggle: The Open-Source Offensive
Deepseek's strategy and success are emblematic of a broader push, particularly from China, to champion open-source AI models as a means of ensuring global adoption and fostering a competitive alternative to the US-led ecosystem of closed, proprietary systems. The success of Deepseek-V3 challenges the prevailing narrative that building and training frontier AI models requires billion-dollar investments and can only be undertaken by a handful of Western technology giants.
By democratizing access to a powerful, efficient, and highly capable model, Deepseek is fueling a wave of innovation across the global developer community. This open approach accelerates research, enables startups to build competitive products without prohibitive API costs, and promotes transparency in a field often shrouded in secrecy. However, this rapid proliferation of powerful, open-source AI also raises significant geopolitical and data security concerns for Western governments and corporations, who must now contend with a new paradigm where frontier capabilities are no longer exclusively controlled by a few trusted actors.
Future Trajectory: Anticipating Deepseek R2 and V4
The development roadmap for Deepseek remains a subject of intense interest. The market is eagerly awaiting the release of Deepseek-R2, the designated successor to the highly esteemed R1 reasoning model. The delays in its release have been attributed to a combination of external factors, such as hardware supply constraints, and internal ones, including the CEO's commitment to perfectionism.
The decision to release v3.1 before R2, along with market speculation about a forthcoming V4, suggests a dual-track development strategy. Deepseek appears to be pursuing continuous, iterative improvements on its mainline general-purpose model (the V-series) while simultaneously perfecting its next-generation, specialized reasoning architecture (the R-series) in parallel. To remain competitive at the absolute frontier, future iterations will almost certainly need to address the current model's primary limitation: the lack of native multimodal capabilities.
Recommendations for Adoption: Identifying Ideal Use Cases
The decision to adopt Deepseek v3.1 depends heavily on the specific needs, resources, and priorities of the user or organization.
For Startups and Cost-Sensitive Enterprises: For applications centered on high-volume text and code generation—such as advanced chatbots, content marketing platforms, automated documentation, and customer support systems—Deepseek v3.1 presents an almost unbeatable value proposition. Its combination of high performance and extremely low API costs provides a compelling total cost of ownership that can enable business models that would be economically unviable with more expensive proprietary APIs.
For Researchers and the Open-Source Community: The public availability of the DeepSeek-V3-0324 model weights on Hugging Face is an invaluable contribution to the research community. It provides an open, accessible platform for academic study, fine-tuning experiments, and exploring the frontiers of MoE architectures without needing privileged access to a proprietary system.
For Enterprise-Grade, Safety-Critical, or Multimodal Applications: Organizations whose primary requirements include native processing of images and video, the analysis of extremely long documents (beyond 128K tokens), or adherence to the highest levels of certified AI safety and compliance may find that proprietary models remain a better fit. Competitors like Google's Gemini 2.5 Pro (for multimodality) and Anthropic's Claude 4.1 Opus (for enterprise safety) offer specific capabilities that Deepseek v3.1 does not currently possess. The lack of native multimodality is its most significant functional gap in the current market.
For Power Users of Complex Reasoning: Users who require the absolute pinnacle of performance for complex, multi-step, and open-ended logical reasoning may find the hybrid v3.1 to be a step back from the specialized focus of the original R1 model. This user segment should likely await the release of the dedicated Deepseek-R2 model or continue to leverage other specialized reasoning systems for their most demanding tasks.
FAQ
1. What is Deepseek v3.1, and how does it differ from previous versions?
Deepseek v3.1, released on 19 August 2025, is a strategic optimisation of the existing Deepseek V3 architecture rather than a revolutionary new model. It consolidates Deepseek's previous chat and reasoner models into a single, unified offering. Key enhancements include an expanded context window of 128,000 tokens (equivalent to 100,000 to 130,000 Chinese characters), a 43% improvement in multi-step reasoning tasks, and a 38% decrease in "hallucinations" (the generation of false information), significantly boosting reliability. It also offers optimised multilingual support, particularly for Asian and minority languages.
Unlike earlier iterations, Deepseek v3.1 integrates the capabilities of the Deepseek-R1 reasoning model into its general-purpose online service. This unification simplifies the product for users, mirroring an industry trend towards versatile, "do-it-all" systems. However, early user feedback indicates a potential trade-off, with some power users reporting a decline in reasoning quality compared to the highly specialised R1 model. The underlying open-source base model for v3.1 is DeepSeek-V3-0324, available under the MIT License.
2. What are the key architectural innovations behind Deepseek v3.1's performance and efficiency?
Deepseek v3.1's impressive performance and cost-efficiency stem from several deliberate architectural choices:
Mixture-of-Experts (MoE) Paradigm: The model is built on a sparse MoE architecture with 671 billion total parameters, but only about 37 billion (5.5%) are active per token. This allows it to scale its knowledge base significantly while keeping inference computational costs low, comparable to much smaller "dense" models. It uses 1 shared expert and 256 routed experts, activating only 8 per token.
Multi-Head Latent Attention (MLA): This advanced attention mechanism compresses Key (K) and Value (V) matrices using low-rank factorization, reducing memory bandwidth and computational load. This is crucial for enabling the large 128K token context window.
Multi-Token Prediction (MTP): Deepseek v3.1 is trained to predict multiple future tokens simultaneously, which improves performance and allows for speculative decoding during inference, accelerating text generation. A dedicated 14-billion-parameter MTP module is included in the open-source release.
Auxiliary-Loss-Free Load Balancing: A novel strategy ensures an even distribution of workload across all experts without using an auxiliary loss term, which can degrade primary model performance.
FP8 Mixed Precision Training: The model was trained using 8-bit floating point precision, drastically reducing memory footprint and accelerating the training process, leading to lower costs.
YaRN Context Extension: This technique allows the model, pre-trained on a shorter 4K token context, to effectively extend its context window to 128K without prohibitive retraining costs.
These innovations combine to create a computationally efficient powerhouse with significantly lower training and operational expenditures.
3. How does Deepseek v3.1 perform on quantitative benchmarks, particularly in technical domains?
Deepseek v3.1 demonstrates state-of-the-art performance in domains requiring logical and symbolic reasoning, notably mathematics and computer programming:
Mathematics: It achieves 94.3% accuracy on the MATH-500 benchmark and a score of 59.4 on the challenging AIME benchmark (a nearly 20-point improvement over its predecessor). On GSM8K, its accuracy is reported between 90% and 94.5%.
Coding: Deepseek v3.1 scores 82.6% on HumanEval-Mul (multilingual code generation) and 49.2 on LiveCodeBench (competitive programming problems), a significant 10-point gain. Its CodeForces rating is equivalent to that of a human competitive programmer, praised by developers for generating complex, functional code.
General Reasoning and Language: It scores 88.5% on the standard MMLU benchmark and 81.2% on the more challenging MMLU-Pro. On GPQA (PhD-level expert knowledge), it achieves 68.4. It also shows dominant performance on Chinese-language NLP benchmarks like CLUEWSC and C-Eval.
While these benchmarks indicate strong performance across the board, user feedback suggests that the consolidated model might not reach the peak reasoning quality of the specialised Deepseek-R1 for highly complex tasks.
4. What are the main points of user feedback regarding Deepseek v3.1, and what do they imply?
While quantitative benchmarks are strong, qualitative feedback from Deepseek v3.1 users reveals a more nuanced picture:
Verbosity and "Vibe": Users commonly observe that the model has become "very, very verbose" in its responses and exhibits a distinct change in conversational style, described as more "matured" and less "quirky" than earlier checkpoints. This suggests a shift in fine-tuning affecting subjective user experience.
Mixed-Reasoning Trade-off: The most significant concern among power users, particularly those who relied on the specialised Deepseek-R1 model, is a perceived "significant decline" in reasoning quality. This indicates that while the unified model offers greater convenience and strong general performance, it may have compromised some of the peak logical depth and precision previously offered by a dedicated reasoning architecture.
This disconnect between stellar benchmark results and mixed user satisfaction highlights the limitations of standardised evaluations. Benchmarks may not fully capture the nuances of performance in open-ended, multi-turn, and highly complex workflows where specialised models once excelled. It also suggests a potential ongoing market for highly specialised models alongside general-purpose ones.
5. How does Deepseek v3.1 strategically position itself against major AI competitors like OpenAI, Google, and Anthropic?
Deepseek v3.1 challenges established AI labs through a strategy centred on cost-efficiency, open-source accessibility, and near-state-of-the-art performance:
OpenAI's GPT-5: Deepseek uses a static, sparse MoE, while GPT-5 employs a dynamic router to different models. GPT-5 often leads in advanced reasoning (e.g., GPQA, AIME), but Deepseek is highly competitive or superior in technical domains (e.g., MATH-500, LiveCodeBench, HumanEval). Deepseek's strategy is to offer near-SOTA performance at a fraction of the cost, targeting developers and businesses where budget is a primary constraint, in contrast to OpenAI's focus on absolute frontier performance and multimodal capabilities.
Google's Gemini 2.5 Pro: Deepseek focuses on depth, specialised text/code tasks, and open-source efficiency. Gemini 2.5 Pro, a proprietary model, prioritises breadth and native multimodality (text, image, audio, video) with a larger 1 million token context window. Gemini leads on GPQA, while Deepseek shows advantage in Retrieval-Augmented Generation (RAG) and complex algorithmic challenges.
Anthropic's Claude 4.1 Opus: This is a direct competition in software engineering. Claude 4.1 Opus excels at complex, enterprise-grade code refactoring (74.5% on SWE-bench Verified). Both models use a "hybrid reasoning" architecture. Anthropic's key differentiator is its strong emphasis on AI safety and enterprise-readiness, making it preferred for risk-averse corporate clients.
Meta's Llama 4 Series: This is a direct open-source MoE showdown. Deepseek v3.1 is "far better" at coding and common-sense reasoning within its text-and-code domain. However, Llama 4 Maverick offers native multimodality and an industry-leading 10 million token context window (Llama 4 Scout variant), making it more versatile for image understanding or extremely large text analysis, areas where Deepseek v3.1 currently lacks.
Deepseek's overall strategy leverages its architectural efficiency to offer disruptive pricing and open-source availability, democratising access to powerful AI capabilities.
6. What makes Deepseek v3.1 particularly attractive to developers and how does its pricing strategy stand out?
Deepseek v3.1 is highly attractive to developers due to its seamless integration, aggressive pricing, and broad accessibility:
OpenAI-Compatible API: Deepseek's API is designed to be a drop-in replacement for OpenAI's widely adopted standard. Developers can use existing OpenAI SDKs by simply changing the base_url, dramatically lowering the barrier to entry and encouraging frictionless migration or experimentation. It supports standard functionalities like JSON mode, function calling, and streaming responses.
Aggressive Pricing: This is Deepseek's most disruptive feature. Its API costs are orders of magnitude lower than proprietary competitors, a direct result of its efficient MoE architecture and FP8 training. For comparable tasks, Deepseek v3.1 is approximately 9 times cheaper than OpenAI's GPT-4o, and up to 200-fold cheaper than older models like GPT-4 Turbo. Furthermore, Deepseek offers off-peak discounts of 50-75% on its already low prices, making it exceptionally cost-effective for high-volume, production-scale AI applications.
Deployment and Accessibility: Deepseek is accessible via its official API, major cloud partners like Microsoft Azure AI Foundry, and platforms like OpenRouter and Together.ai. For researchers and well-resourced organisations, the DeepSeek-V3-0324 base model weights are publicly available on Hugging Face, allowing for local deployment and fine-tuning, albeit requiring substantial hardware resources.
This combination of ease of use, extreme affordability, and open access positions Deepseek to capture significant market share, especially from startups and cost-sensitive enterprises.
7. What is Deepseek's strategic role in the global AI landscape, and what does its future trajectory look like?
Deepseek v3.1 is a significant player in the strategic evolution of the global AI landscape, championing the open-source movement:
Open-Source Offensive: Deepseek's success challenges the narrative that frontier AI development requires multi-billion-dollar investments exclusive to a few Western giants. By offering a powerful, efficient, and open-source model, it democratises access to AI, accelerating innovation, enabling startups, and promoting transparency. This fuels a wave of innovation globally and presents a competitive alternative to the US-led ecosystem of closed, proprietary systems. However, it also raises geopolitical and data security concerns for Western governments.
Future Trajectory: The market anticipates the release of Deepseek-R2, the successor to the highly esteemed R1 reasoning model, with delays attributed to hardware constraints and a commitment to perfectionism. The release of v3.1 before R2 suggests a dual-track development strategy: continuous iterative improvements on its general-purpose V-series models, while perfecting its next-generation, specialised R-series reasoning architecture in parallel. To maintain competitiveness at the absolute frontier, future iterations will almost certainly need to address the current model's primary limitation: the lack of native multimodal capabilities.
Deepseek is poised to continue disrupting the market by offering high-performance, cost-efficient, and open AI solutions, driving competition and innovation across the industry.
8. What are the ideal use cases for Deepseek v3.1, and for whom might other models be more suitable?
The decision to adopt Deepseek v3.1 depends on specific needs and priorities:
Ideal Use Cases for Deepseek v3.1:
Startups and Cost-Sensitive Enterprises: For high-volume text and code generation applications such as advanced chatbots, content marketing, automated documentation, and customer support systems, Deepseek v3.1 offers an unbeatable value proposition due to its high performance and extremely low API costs.
Researchers and the Open-Source Community: The public availability of model weights provides an invaluable, accessible platform for academic study, fine-tuning, and exploring MoE architectures.
Organisations requiring strong technical reasoning: Its exceptional performance in mathematics and code generation makes it highly suitable for tasks involving logical and symbolic reasoning.
Situations Where Other Models Might Be More Suitable:
Enterprise-Grade, Safety-Critical, or Multimodal Applications: Organisations requiring native processing of images and video (Deepseek v3.1 is text/code limited), analysis of extremely long documents (beyond 128K tokens), or adherence to the highest levels of certified AI safety and compliance may find proprietary models like Google's Gemini 2.5 Pro (for multimodality) or Anthropic's Claude 4.1 Opus (for enterprise safety) to be a better fit.
Power Users of Complex Reasoning: Users demanding the absolute pinnacle of performance for complex, multi-step, open-ended logical reasoning may find the hybrid v3.1 less specialised than the original R1 model. This segment might await the dedicated Deepseek-R2 or leverage other specialised reasoning systems.
Extremely Large Context Retrieval: While Deepseek has a large context, Meta's Llama 4 Scout, with its 10 million token context window, would be superior for tasks requiring analysis of truly massive volumes of text.