Fine-Tuning Strategies: When to Use PEFT, LoRA, or Full Model Training
Discover the optimal fine-tuning strategies for AI models in 2025. Learn when to implement PEFT, LoRA, or full model training to maximize efficiency and performance while minimizing costs in your machine learning projects.
Fine-tuning represents a pivotal process for adapting general-purpose Large Language Models (LLMs) to specialized tasks and unique domains. This adaptation is crucial for enhancing model accuracy, embedding domain-specific knowledge, and mitigating undesirable behaviors such as hallucinations. By leveraging the extensive foundational knowledge acquired during pre-training, fine-tuning offers a significantly more efficient alternative to training models from scratch.
This report comprehensively examines three primary fine-tuning strategies: Full Model Fine-Tuning, Parameter-Efficient Fine-Tuning (PEFT), and Low-Rank Adaptation (LoRA). Full fine-tuning, while capable of achieving maximal task-specific performance, incurs substantial computational costs and presents a notable risk of catastrophic forgetting of previously learned knowledge. In contrast, PEFT, particularly its prominent variant LoRA, provides a highly efficient and scalable alternative. These parameter-efficient methods can achieve performance comparable to full fine-tuning for a wide array of tasks, all while demanding vastly reduced computational resources and exhibiting improved retention of general knowledge. The strategic selection among these approaches hinges on a careful evaluation of specific project goals, available computational resources, the inherent complexity of the target task, and critical deployment considerations.
II. Introduction to LLM Fine-Tuning
Definition and Fundamental Purpose of Fine-Tuning
Fine-tuning is a specialized process within machine learning that involves adjusting a pre-trained Large Language Model (LLM) to better suit a specific task, dataset, or use case. It fundamentally leverages the extensive knowledge a base model has already acquired during its initial, broad training phase, using this as a starting point for further specialization. This process entails modifying a subset or all of the model's parameter weights to customize its behavior for a particular application, enabling it to adapt to nuances and context that were not fully captured during its general pre-training. As a subset of transfer learning, fine-tuning efficiently hones the capabilities of an existing model rather than incurring the prohibitive costs and time associated with training a new model from scratch for each specific purpose.
The Necessity of Fine-Tuning for Adapting General-Purpose LLMs to Specific Tasks and Domains
While LLMs are pre-trained on colossal and diverse datasets, equipping them with remarkable general language understanding and generation capabilities, they are not inherently optimized for every conceivable application. These general-purpose models often fall short when confronted with demands for ultra-specific behaviors, maintaining a consistent tone or format, correcting failures to follow complex instructions, handling unique or rare edge cases, or acquiring entirely new skills such as converting natural language to code.
Fine-tuning directly addresses these limitations by allowing the incorporation of highly specialized or domain-specific knowledge, such as terminology and contextual understanding pertinent to the financial or healthcare sectors. It can also optimize the model for very particular use cases, such as customer support interactions or specialized language translation. Beyond performance enhancements, fine-tuning can also lead to practical benefits like reducing the length of prompts required to elicit desired outputs, which in turn can lead to potential cost savings and lower inference latency.
An Overview of the Evolving Landscape of Fine-Tuning Strategies
The domain of LLM fine-tuning is dynamic and characterized by continuous innovation, with new techniques and optimizations constantly emerging. This report will explore the traditional paradigm of full model fine-tuning, which involves comprehensive adjustments to the entire model, alongside the more recent and increasingly prevalent parameter-efficient methods. By examining their respective strengths, weaknesses, and optimal applications, this analysis aims to provide a clear understanding of the strategic choices available for LLM customization.
III. Full Model Fine-Tuning: The Comprehensive Approach
Core Principles and Operational Workflow
Full model fine-tuning represents the most comprehensive approach to adapting a pre-trained Large Language Model (LLM) to a specific task. Its core principle involves updating all of the parameters within the pre-trained base model. The vast knowledge embedded in the base model from its initial training serves as a foundational starting point, which is then meticulously tailored to the new task through extensive parameter adjustments.
The operational workflow for full fine-tuning typically employs supervised learning. This process begins with the provision of a task-specific training dataset, which consists of numerous examples of user input paired with the desired LLM output. During a fine-tuning experiment, this training data is first read, tokenized, and then converted into manageable batches, the size of which is determined by a configurable batch size parameter. Input from these batches is fed to the foundation model, which generates an output. This generated output is then critically compared to the corresponding expected output from the training data, and the difference is quantified as a "loss gradient". Based on this computed loss, the underlying parameter weights of the foundation model are systematically adjusted to minimize the discrepancy between predicted and actual outputs. This adjustment process, influenced by parameters such as accumulation steps and learning rate, is repeated iteratively across all examples in the batches and for a specified number of "epochs" (full passes through the entire training dataset). The culmination of a successful full fine-tuning experiment is a new foundation model specifically tuned for the intended task.
Advantages: Maximizing Task-Specific Performance and Customization
Full fine-tuning offers distinct advantages, primarily centered on its ability to achieve the highest possible level of task-specific performance and deep customization. By allowing all model parameters to be updated, this method generally yields the highest accuracy and best performance for highly specialized tasks. The comprehensive adjustment of the entire model enables it to become profoundly tailored to the new task, often resulting in superior performance compared to methods that modify fewer parameters.
This approach is particularly effective for deep customization, allowing developers to precisely control qualitative aspects such as style, tone, and output format. It is highly effective in improving the reliability of generated output, correcting instances where the model fails to follow complex prompts, and handling intricate or unique edge cases that general models might struggle with. Furthermore, full fine-tuning can be used to teach the model entirely new skills that are difficult to articulate through mere prompting, such as converting natural language into code.
The method excels at incorporating deep domain-specific expertise, making a general-purpose LLM highly conversant in specialized fields like healthcare, finance, or legal analysis. This level of specialization ensures the model provides accurate and relevant responses aligned with industry-specific requirements. A notable practical benefit is prompt efficiency and potential cost savings. By baking desired behaviors and knowledge directly into the model's parameters, the need for lengthy, descriptive prompts can be significantly reduced. This leads to shorter prompts, which can translate into lower token usage, reduced API costs, and decreased latency for requests. Finally, full fine-tuning facilitates tool-calling integration, allowing API signatures to be directly embedded into the model's behavior, transforming a chatbot into an action-taking agent capable of interacting with external systems.
Disadvantages: High Resource Demands and Risk of Catastrophic Forgetting
Despite its performance benefits, full model fine-tuning comes with significant drawbacks, primarily its high resource demands and the risk of catastrophic forgetting. Updating all parameters of a large LLM necessitates substantial computational power, considerable GPU memory, and extensive datasets. The memory footprint during training can be approximately 12 times larger than the model itself, primarily due to the storage requirements for optimizer states and gradients. This makes fine-tuning even smaller LLMs, such as a 7-billion parameter Llama-2 model, a substantial computational undertaking.
These intensive resource requirements translate directly into longer training times and higher costs. Training cycles for full fine-tuning are considerably extended, potentially spanning days or even weeks. This protracted training period, coupled with the need for extensive computational resources, results in significantly higher infrastructure costs.
A critical limitation is the risk of catastrophic forgetting. This phenomenon occurs when the model, during the fine-tuning process, loses or overwrites the broad, general knowledge it acquired during its initial pre-training. This issue can be particularly pronounced in larger LLMs , undermining their versatility and reusability across different domains. The fixed data composition and format in the fine-tuning dataset can impair the general knowledge previously learned, leading to a decline in logical reasoning abilities and the capacity to answer general questions.
Furthermore, full fine-tuning carries a higher risk of overfitting, especially when the task-specific dataset is relatively small or insufficiently diverse. In such cases, the model may memorize the training data rather than learning generalizable patterns, leading to poor performance on unseen data.
Finally, scalability and deployment present significant challenges. Each fully fine-tuned model is a complete copy of the original base model, which means high storage costs and complexity when managing multiple task-specific models. Deploying these large models can also be slower due to their substantial size and processing demands. This makes it difficult to scale across numerous tasks or deploy on resource-constrained devices.
Appropriate Use Cases and Scenarios
Full model fine-tuning is the preferred strategy in specific scenarios where its comprehensive nature aligns with project requirements and available resources. It should be prioritized for applications demanding the absolute highest accuracy, particularly in complex domains such as programming and mathematics, where the model needs to acquire fundamentally new and intricate reasoning skills. This includes critical diagnostic tools in sensitive sectors like healthcare or for detailed legal analysis where extreme precision is paramount.
This approach is also suitable when a large and diverse dataset is readily available. Such a dataset can adequately update all of the model's parameters without the danger of overfitting, allowing the model to deeply learn the nuances of the specific task.
Full fine-tuning becomes necessary when prompt engineering reaches its inherent limits. This occurs when system prompts become excessively long, token budgets are consistently too high, or the base model fails to reliably follow complex instructions, maintain a specific output format, or handle recurring edge cases despite careful prompting. In essence, when the task requires the model to develop a very specific understanding or behavior that significantly deviates from its pre-trained general knowledge, full fine-tuning provides the necessary depth of adaptation.



VI. Comparative Analysis: Full Fine-Tuning vs. PEFT vs. LoRA
A thorough comparative analysis of full fine-tuning, Parameter-Efficient Fine-Tuning (PEFT), and Low-Rank Adaptation (LoRA) reveals distinct profiles across computational efficiency, data requirements, performance trade-offs, and deployment considerations.
Computational and Memory Efficiency
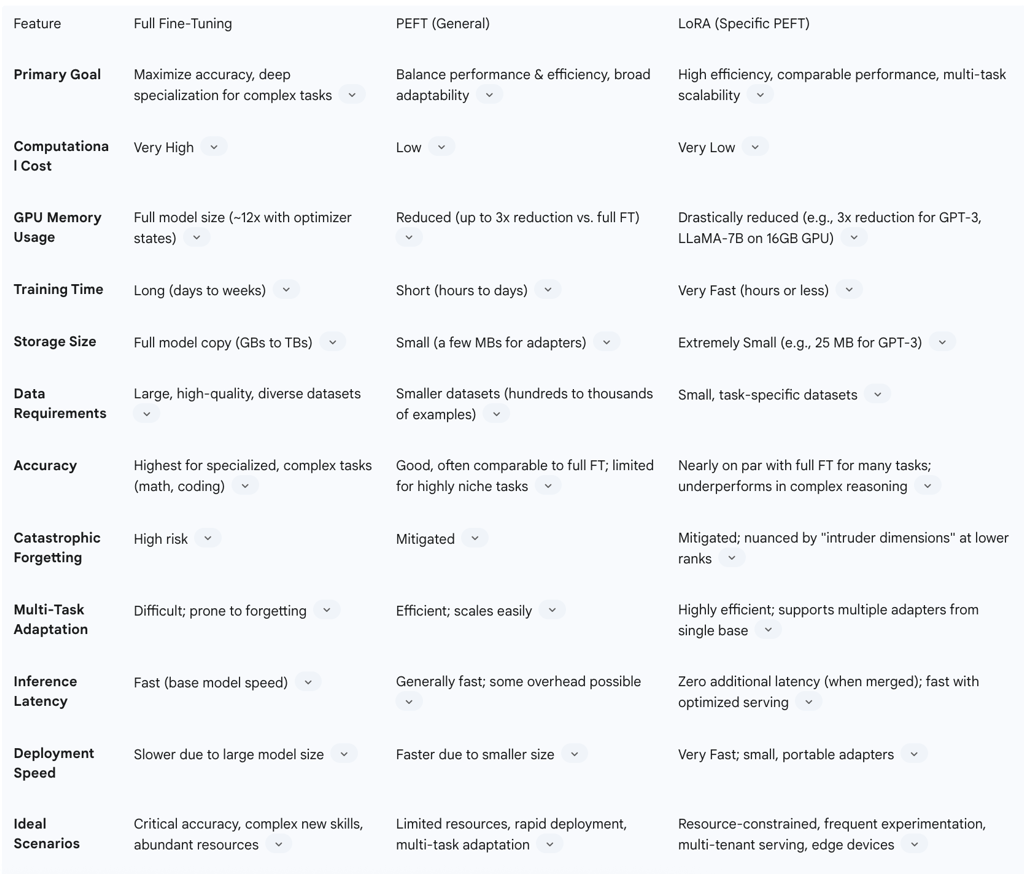
Full Fine-Tuning demands the highest computational power, memory, and storage. Its GPU memory usage is equivalent to the full model size, and the inclusion of optimizer states and gradients can inflate the memory footprint to approximately 12 times the size of the base model. This makes it a resource-intensive endeavor, often requiring high-end hardware.
PEFT (General) methods dramatically reduce these computational resource, memory, and storage requirements. These techniques can decrease GPU memory usage by up to 3 times and optimize parameter storage to as little as 0.01% of the original model size. This significant reduction makes advanced LLM customization feasible on more modest hardware.
LoRA (Specific PEFT) offers exceptional efficiency within the PEFT framework. It drastically reduces the number of trainable parameters by orders of magnitude, for instance, saving over 99.97% of parameters for a GPT-3 model. This translates to a reduction in GPU memory requirements by 3 times for large models and can shrink checkpoint sizes from 1 TB to a mere 25 MB for models like GPT-3. This efficiency enables the fine-tuning of large models, such as LLaMA-7B, on consumer-grade GPUs.
Data Efficiency
Full Fine-Tuning requires large, high-quality, and diverse datasets to effectively update all of the model's parameters and prevent overfitting. The extensive nature of its parameter adjustments necessitates a comprehensive data input.
In contrast, PEFT (General) is highly data-efficient, performing well even with smaller datasets. A model initially trained on trillions of tokens can be effectively fine-tuned with just a few hundred examples using PEFT. This significantly lowers the data acquisition and annotation burden.
LoRA (Specific PEFT) further exemplifies this data efficiency, demonstrating better performance with relatively smaller, task-specific datasets and proving effective even in scenarios with limited data availability.
Performance Trade-offs
The choice of fine-tuning strategy involves a nuanced consideration of performance, particularly regarding accuracy, generalization, and the risk of catastrophic forgetting.
Accuracy:
Full Fine-Tuning generally yields the highest accuracy for highly specialized tasks and complex domains, such as programming and mathematics, where deep learning of new skills is required.
PEFT (General) provides good accuracy, often comparable to full fine-tuning for a wide range of applications. However, its lighter parameter updates may present limitations for extremely niche or complex tasks that demand the utmost precision and intricate model adaptation.
LoRA (Specific PEFT) achieves performance "nearly on par" with full fine-tuning for many tasks. It has even demonstrated the ability to outperform GPT-4 in specialized tasks like SQL query generation. However, it consistently underperforms full fine-tuning in tasks demanding high levels of logical or mathematical reasoning. This performance gap arises because LoRA's low-rank approximation, while efficient, may limit its "adaptation capacity" for fundamentally new and complex skills that require more comprehensive model modifications. This represents a trade-off between the extreme efficiency gained from low-rank approximation and the ultimate expressivity required for certain types of learning.
Generalization Capabilities and Catastrophic Forgetting:
Full Fine-Tuning is notably prone to catastrophic forgetting, a phenomenon where the model loses significant portions of its pre-trained general knowledge when adapted to new tasks. This can also reduce its robustness to distribution shifts, impacting performance on out-of-distribution (OOD) data.
PEFT (General) methods are specifically designed to mitigate catastrophic forgetting by preserving the majority of the initial parameters, thus safeguarding the model's core knowledge.
LoRA (Specific PEFT) acts as a stronger regularizer, effectively mitigating the forgetting of source domain knowledge and helping to maintain diversity in generated solutions, unlike full fine-tuning which can lead to "collapse" in diversity. However, LoRA can still suffer from catastrophic forgetting, particularly at lower ranks, and the emergence of "intruder dimensions" (new singular vectors not present in full fine-tuning) can make LoRA models less robust to sequential multi-task adaptation and degrade their modeling of the pre-training distribution. This suggests a subtle degradation of fundamental generalization properties in certain contexts, even as it offers efficiency and knowledge retention benefits. Higher-rank LoRA models, however, have been shown to more closely mirror full fine-tuning behavior in terms of generalization, offering a potential mitigation.
Deployment and Serving Implications
The choice of fine-tuning strategy also has significant implications for model deployment and serving infrastructure.
Model Size & Storage:
Full Fine-Tuning results in each fine-tuned model being a complete copy of the original base model. This leads to substantial storage costs and considerable difficulty in managing multiple task-specific models, as each requires its own full storage footprint.
PEFT (General) methods are highly advantageous here, as only the fine-tuned parameters (typically a few megabytes) are saved. This dramatically reduces storage requirements and enhances model portability.
LoRA (Specific PEFT) checkpoints are exceptionally small, facilitating efficient storage and quick loading of numerous task-specific models from a single shared base model. This modularity is a key benefit for scalable serving architectures.
Inference Latency:
Full Fine-Tuning generally offers fast inference speeds, equivalent to that of the original base model, as the entire model is optimized for the task.
PEFT (General) methods can, in some cases (e.g., Prompt Tuning), introduce a slight overhead during inference due to the addition of extra tokens or computational steps.
LoRA (Specific PEFT), when its adapter weights are merged with the base model, introduces no additional latency during inference. Furthermore, optimized kernels and specialized serving frameworks (e.g., TGI, vLLM) are designed to support fast and efficient inference, even when dynamically serving multiple LoRA models concurrently.
Multi-Adapter Serving:
Full Fine-Tuning necessitates deploying separate full models for each distinct task, which is highly resource-intensive and challenging to scale in environments requiring many specialized models.
PEFT (General) methods enable efficient multi-task adaptation by allowing a single base model to be augmented with multiple lightweight, task-specific adapters. This significantly improves scalability and resource utilization.
LoRA (Specific PEFT) is particularly well-suited for serving multiple adapters from a single base model. Its modularity allows for dynamic loading and unloading of task-specific adapters as needed, significantly reducing memory fragmentation and management overhead while enhancing scalability and throughput through batching across different adapters. This capability is critical for applications requiring rapid switching between diverse specialized behaviors.
VII. Decision Framework: When to Choose Which Strategy
The selection of an optimal fine-tuning strategy among full model fine-tuning, PEFT, and LoRA is a multifaceted decision that requires careful consideration of several interconnected factors. There is no one-size-fits-all solution; rather, the most appropriate approach emerges from a nuanced assessment of project goals, available resources, task complexity, and deployment considerations.
Project Goals and Performance Requirements
The primary driver for choosing a fine-tuning strategy is the project's performance objective.
For applications demanding the absolute highest accuracy, particularly in highly specialized or complex domains like advanced programming or mathematical reasoning, full fine-tuning is often the preferred choice. This is because it allows for the deepest learning and most comprehensive adaptation of the model's parameters to acquire fundamentally new and intricate skills. It is especially critical for diagnostic tools in sensitive sectors like healthcare or for legal analysis requiring extreme precision.
If the goal is to achieve comparable performance to full fine-tuning while prioritizing efficiency, PEFT (and specifically LoRA) is highly recommended. These methods are well-suited for setting a specific style, tone, or format, improving output reliability, and handling most edge cases where the core knowledge of the base model is largely sufficient, and only adaptation to nuances is required.
Available Resources (Computational, Data, Expertise)
Resource availability significantly constrains the feasible fine-tuning strategies.
Full fine-tuning demands substantial computational resources, including high-end GPUs, extensive memory, and significant storage capacity, along with a considerable budget and deep machine learning expertise. It also requires large, high-quality, and diverse datasets to prevent overfitting and ensure comprehensive parameter updates.
In contrast, PEFT (and LoRA) are designed for resource-constrained environments. They operate efficiently on consumer-grade GPUs, require significantly less memory and storage, and are more cost-effective. These methods are also highly data-efficient, performing well with smaller datasets (even a few hundred examples). This lowers the barrier to entry for smaller organizations or individual developers, democratizing access to LLM customization.
Deployment and Maintenance Considerations
The long-term implications for deployment and ongoing maintenance are crucial for strategic planning.
Full fine-tuning results in large model sizes, making deployment slower and more resource-intensive, especially when managing multiple task-specific models, as each is a full copy of the original. Ongoing maintenance can also be complex due to the large number of parameters.
PEFT (and LoRA) offer significant advantages in deployment. Their smaller model sizes lead to faster deployment and quicker iteration cycles. LoRA, in particular, enables efficient multi-adapter serving from a single base model, dramatically reducing storage and computational costs when numerous specialized models are required. When LoRA adapters are merged with the base model, they introduce no additional inference latency, maintaining the speed of the base model. This modularity and efficiency are ideal for rapid experimentation and deployment on edge devices or in multi-tenant serving environments.
VIII. Best Practices Across Fine-Tuning Strategies
Regardless of the chosen fine-tuning strategy, adhering to a set of best practices is paramount for achieving optimal model performance, stability, and efficient deployment.
Data Preparation and Quality
The foundation of any successful fine-tuning endeavor lies in the quality and meticulous preparation of the dataset. The principle of "garbage in, garbage out" applies rigorously to machine learning models. Therefore, it is crucial to ensure that the data is clean, relevant, diverse, and of sufficiently high quality. This involves cleaning the dataset to remove errors and inconsistencies, addressing missing values, and formatting it precisely to match the model's input requirements.
To enhance model flexibility and generalization, data augmentation techniques can be employed to expand the dataset by creating variations of existing data. For example, for image data, transformations like rotation or scaling can be applied, while for text, rephrasing or synonym replacement might be used. It is also vital to ensure that training and validation datasets are strictly separated, with no overlap, to prevent data leakage that could lead to misleadingly high-performance metrics. Furthermore, for full fine-tuning, the dataset should be large and diverse enough to comprehensively update all parameters. For PEFT methods, while smaller datasets are effective, quality remains paramount; a few hundred high-quality examples are more valuable than thousands of poor ones.
Model Selection and Architecture Considerations
Choosing the right pre-trained model is a critical initial step. The selected model should align as closely as possible with the target task and domain. This involves considering the model's architecture, its handling of input and output, and its inherent size and complexity. Practitioners should evaluate how well the model has performed on similar tasks by consulting benchmark leaderboards and experimenting in model playgrounds to assess its real-world performance before committing to fine-tuning.
When considering model architecture, it is important to weigh the trade-offs between model size, complexity, cost, and desired performance. Larger models may offer superior accuracy but come with higher computational costs and latency. For simpler tasks, starting with a smaller model is often more efficient. For PEFT, the choice of target modules (specific layers where adaptations are applied, such as attention blocks in LoRA) is a key architectural consideration that impacts learnability and performance.
Hyperparameter Tuning (General and LoRA-Specific)
Fine-tuning is an iterative process that necessitates careful adjustment of hyperparameters to optimize model performance and ensure training stability.
General Hyperparameters:
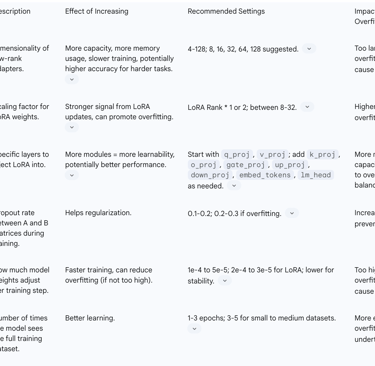
Learning Rate: This dictates the step size for parameter adjustments. An optimal learning rate prevents the model from learning too slowly (underfitting) or too quickly (overfitting). For LoRA, the learning rate is particularly sensitive, with typical ranges from 1e-4 to 5e-5, and lower rates generally promoting stability.
Batch Size: Determines the number of examples processed in one training iteration. Higher batch sizes require more VRAM but can lead to faster training. Gradient accumulation steps can be used to simulate larger batch sizes when memory is limited.
Number of Epochs: Represents the total number of times the model sees the entire training dataset. Too many epochs can lead to overfitting, while too few can result in undertraining. Recommended ranges are typically 1-3 epochs, or 3-5 for small to medium datasets.
LoRA-Specific Hyperparameters:
Rank (r): Controls the dimensionality of the low-rank adapters. Starting with a small value (e.g., r=4) and increasing only if performance plateaus is a common practice. Higher ranks increase capacity but also memory usage and training time.
LoRA Alpha (lora_alpha): The scaling factor for LoRA weights. Values between 8 and 32 are common, often set equal to or twice the rank.
LoRA Dropout (lora_dropout): Applied between the A and B matrices to prevent overfitting, particularly on smaller datasets. Values of 0.1-0.2 are typical, increasing to 0.2-0.3 if overfitting is observed.
Initialization: Default initialization (Kaiming-uniform for A, zeros for B) is common, but advanced methods like PiSSA or LoftQ can improve performance, especially with quantization. Using Rank-Stabilized LoRA (
use_rslora=True) can further stabilize training and unlock performance from higher ranks.
Evaluation and Iterative Refinement
Continuous evaluation is crucial throughout the fine-tuning process. A dedicated validation set, separate from the training data, should be used to regularly assess the model's performance on unseen data and monitor for overfitting. Key metrics such as accuracy, precision, recall, F1 score (for classification), or BLEU/ROUGE (for generation) should be tracked.
Fine-tuning is inherently iterative. Based on evaluation results, adjustments can be made to hyperparameters, data augmentation strategies, or even the choice of PEFT method. Analyzing errors made by the model can provide valuable insights into areas for improvement and guide subsequent iterations.
Deployment and Ongoing Maintenance
Once a satisfactory fine-tuned model is achieved, its deployment into real-world applications requires careful planning. Ensuring the model runs efficiently on target hardware and software, considering factors like scalability, speed, and security, is paramount.
Deployment Challenges and Solutions:
Full fine-tuning can face challenges with computational constraints and deployment issues due to large model sizes. Solutions include opting for lightweight models or leveraging cloud-based scalable resources.
For PEFT and LoRA, while generally efficient, serving multiple adapters dynamically can introduce challenges like memory fragmentation and the need for efficient loading/unloading to avoid latency spikes. Solutions include merging LoRA adapters with the base model for zero latency or utilizing optimized serving frameworks like vLLM, TGI, or LoRAX, which are designed to handle multiple LoRA adapters efficiently through dynamic batching and memory optimization. These frameworks enable a single base model to serve numerous task-specific adapters, enhancing scalability and cost-efficiency.
Ongoing Maintenance: Models, once deployed, require continuous monitoring to track performance and detect any degradation over time. This includes analyzing deployment logs to identify problematic outputs that may indicate a need for further fine-tuning or data updates, supporting a "never-ending learning" paradigm. Regular security audits and updates are also essential to maintain trustworthiness in real-world scenarios.
IX. Conclusions and Recommendations
The landscape of Large Language Model (LLM) customization is defined by a strategic choice among full model fine-tuning, Parameter-Efficient Fine-Tuning (PEFT), and its prominent variant, Low-Rank Adaptation (LoRA). Each strategy presents a distinct balance of performance, resource demands, and operational considerations, necessitating a nuanced decision-making process tailored to specific project contexts.
Full model fine-tuning stands as the most comprehensive approach, capable of delivering the highest accuracy and deepest customization for tasks demanding the acquisition of fundamentally new and complex skills, such as advanced mathematical reasoning or intricate code generation. This method is ideal when abundant computational resources (high-end GPUs, significant memory) and large, high-quality datasets are available. However, its substantial resource consumption, prolonged training times, and inherent susceptibility to catastrophic forgetting and overfitting with limited data represent significant barriers.
Parameter-Efficient Fine-Tuning (PEFT), encompassing a diverse array of techniques, fundamentally democratizes LLM customization. By selectively updating only a small fraction of parameters or injecting lightweight modules, PEFT drastically reduces computational and memory requirements, making fine-tuning feasible on more modest hardware and at a fraction of the cost. This efficiency translates into faster experimentation cycles and significantly mitigates catastrophic forgetting, preserving the model's broad pre-trained knowledge. While generally achieving performance comparable to full fine-tuning, PEFT may encounter performance ceilings for the most complex or niche tasks that require the full expressive power of all model parameters.
Low-Rank Adaptation (LoRA) emerges as a particularly compelling PEFT strategy. Its core principle of approximating weight updates with small, low-rank matrices while freezing the base model offers exceptional efficiency in terms of reduced trainable parameters, significant memory savings, and remarkably smaller model checkpoints. LoRA enables rapid fine-tuning and, crucially, introduces no additional inference latency when its adapters are merged with the base model. This modularity facilitates highly scalable multi-task serving from a single base model, making it ideal for environments requiring numerous specialized LLMs. However, LoRA's low-rank approximation can limit its adaptation capacity for tasks demanding complex logical reasoning, leading to performance gaps compared to full fine-tuning. Furthermore, the emergence of "intruder dimensions" can subtly affect generalization and multi-task robustness, especially at lower ranks, requiring careful hyperparameter tuning and monitoring.
Recommendations for Strategy Selection:
Prioritize Full Model Fine-Tuning when:
The task demands the absolute highest accuracy and involves teaching the model fundamentally new, complex skills (e.g., advanced mathematical reasoning, highly specialized coding).
You possess ample computational resources (high-end GPUs, large memory, substantial budget).
A large, high-quality, and diverse dataset is readily available.
Existing prompt engineering efforts have reached their limits and fail to elicit the desired, consistent, and precise behavior.
Opt for Parameter-Efficient Fine-Tuning (PEFT), with LoRA as a primary consideration, when:
Computational resources (GPUs, memory, budget) are limited, or you aim for cost-effective customization.
Rapid experimentation, faster iteration cycles, and quicker time-to-market are critical.
The primary goal is to adapt the model to specific styles, tones, formats, or domain-specific nuances, rather than teaching entirely new, complex reasoning skills.
You need to mitigate catastrophic forgetting and preserve the broad general knowledge of the pre-trained model.
Data availability is moderate to small, as PEFT methods are highly data-efficient.
Deployment requires managing multiple task-specific models efficiently from a single base, or deploying to resource-constrained environments (e.g., edge devices).
Specifically choose LoRA (or its variants like QLoRA) when:
You require extreme parameter efficiency and memory savings for fine-tuning very large models.
The ability to serve multiple specialized models concurrently from a single base model is a key requirement.
Inference latency must remain minimal, and the flexibility of merging adapters is desirable.
You are working with diverse modalities (e.g., text, images) as LoRA is broadly applicable.
Careful hyperparameter tuning (especially r, lora_alpha, and learning rate) can be performed to optimize performance and stability.
Ultimately, the most effective fine-tuning strategy is one that aligns meticulously with the project's specific performance objectives, resource constraints, and long-term deployment goals. A pragmatic approach often involves starting with resource-efficient methods like LoRA, evaluating their performance, and only escalating to full fine-tuning if the task's complexity or stringent accuracy requirements demonstrably necessitate the full expressive power of the entire model.
Conclusion
The landscape of model fine-tuning has evolved dramatically in recent years, transitioning from the brute-force approach of full model fine-tuning to increasingly sophisticated and efficient alternatives. The emergence of Parameter-Efficient Fine-Tuning methods, particularly Low-Rank Adaptation (LoRA) and its variants, has democratized access to model customization, enabling practitioners with limited computational resources to adapt state-of-the-art models to their specific needs. This evolution represents a significant step forward in making advanced AI more accessible and practical for a wider range of applications and organizations. As we've explored throughout this article, each fine-tuning approach offers distinct advantages and limitations, making the optimal choice highly dependent on specific project requirements, resource constraints, and performance goals. Full fine-tuning remains the gold standard for absolute performance but comes with substantial resource demands that make it impractical for many scenarios. PEFT methods offer an impressive balance of efficiency and effectiveness that makes them the rational choice for most practical applications.
Looking toward the future, we can expect continued innovation in efficient fine-tuning techniques as models continue to grow in size and complexity. The research community has demonstrated remarkable ingenuity in developing approaches that dramatically reduce computational requirements while maintaining performance, and this trend is likely to continue. Emerging techniques that combine quantization, sparsity, and low-rank approximations promise even greater efficiency gains, potentially enabling adaptation of trillion-parameter models on commodity hardware. At the same time, we may see increased focus on making these techniques more accessible through improved tooling, standardized workflows, and higher-level abstractions that hide implementation complexity. This democratization of model adaptation capabilities will empower a broader range of practitioners to leverage and customize state-of-the-art AI models, potentially accelerating innovation across numerous domains.
For practitioners navigating this evolving landscape, a pragmatic approach is recommended. Rather than defaulting to full fine-tuning out of habit or treating newer methods with skepticism, conduct empirical evaluations comparing different approaches on your specific tasks and datasets. In many cases, the results will demonstrate that efficient methods like LoRA deliver comparable performance at a fraction of the cost. Start with established best practices for hyperparameters and adaptation targets, then iteratively refine based on validation performance. Remember that the goal is not theoretical purity but practical effectiveness—the best approach is the one that delivers the required performance within your resource constraints. By understanding the tradeoffs between different fine-tuning strategies and making informed decisions, you can maximize the value of your AI investments while developing solutions that precisely address your specific needs.
Frequently Asked Questions
Here are answers to some common questions about model fine-tuning strategies:
What is the difference between PEFT and LoRA? PEFT (Parameter-Efficient Fine-Tuning) is a general category of techniques that reduce trainable parameters during fine-tuning. LoRA (Low-Rank Adaptation) is a specific PEFT method that uses low-rank decomposition to efficiently adapt model weights.
Can I run LoRA fine-tuning on a consumer GPU? Yes, LoRA significantly reduces memory requirements, making it possible to fine-tune large models (up to 20B parameters) on consumer GPUs like RTX 4090 with 24GB VRAM. For even larger models, QLoRA can enable fine-tuning on consumer hardware.
How much performance do I lose with LoRA compared to full fine-tuning? LoRA typically retains 90-98% of full fine-tuning performance while training less than 1% of the parameters. The exact performance gap depends on the specific task, model architecture, and rank selection.
What rank should I use for LoRA fine-tuning? Common LoRA ranks range from 8 to 64. Smaller ranks (8-16) work well for many tasks while being very efficient. Larger ranks (32-64) may improve performance for complex tasks but require more memory and computation.
Can I combine multiple LoRA adapters? Yes, multiple LoRA adapters can be merged or composed. This enables techniques like adapter stacking for multi-task learning or knowledge composition from different specialized adapters.
What is QLoRA and how does it differ from standard LoRA? QLoRA (Quantized LoRA) combines 4-bit quantization of the base model with LoRA fine-tuning. It reduces memory requirements by up to 75% compared to standard LoRA, enabling fine-tuning of very large models on consumer hardware.
When should I use full fine-tuning instead of efficient methods? Full fine-tuning is preferable when maximum performance is critical, when adapting to domains very different from pre-training data, and when computational resources are abundant relative to the importance of the application.
How do I choose which layers to apply LoRA to? Common approaches include applying LoRA to attention layers only (query and value projections), to all linear layers, or selectively to layers based on empirical testing. Attention-only LoRA offers good efficiency while maintaining performance.
Does LoRA affect inference speed? LoRA adapters can be merged with the base model during inference, resulting in no speed impact. When used as separate adapters, they add minimal overhead (typically less than 5%).
What are the newest developments in efficient fine-tuning beyond LoRA? Recent advances include (1) DoRA which extends LoRA with magnitude changes, (2) hybrid approaches combining different PEFT methods, (3) sparse fine-tuning techniques, and (4) improved quantization methods for even greater memory efficiency.
Additional Resources
For readers interested in exploring fine-tuning strategies in more depth, here are some valuable resources:
Understanding Parameter-Efficient Fine-Tuning - A comprehensive guide to PEFT methods including practical implementation tips and case studies.
The Complete Guide to Quantization for LLMs - Learn about quantization techniques that can be combined with fine-tuning approaches for even greater efficiency.
Production Deployment Strategies for Fine-Tuned Models - Best practices for deploying fine-tuned models in production environments, with a focus on efficient serving and resource optimization.
Fine-Tuning Benchmarks: Performance vs. Efficiency Tradeoffs - Empirical comparisons of different fine-tuning approaches across various model sizes and tasks.
Emerging Techniques in Model Adaptation - Cutting-edge research and emerging approaches in the rapidly evolving field of model adaptation.