Kubernetes for Data Engineering in Cloud Environments
This report provides a comprehensive analysis of both the tactical implementation and strategic implications of leveraging Kubernetes for data engineering in the cloud. It details how organizations can effectively deploy and manage data workloads, navigate common challenges, and position themselves to capitalize on future trends in the evolving data landscape.


Kubernetes has rapidly emerged as a cornerstone technology, fundamentally reshaping data engineering practices within cloud environments. Its capacity for orchestrating containerized applications offers unparalleled advantages in scalability, resource efficiency, and operational automation, addressing many limitations of traditional data platforms. Tactically, Kubernetes empowers data engineers to build resilient, dynamic data pipelines, run sophisticated data processing frameworks like Apache Spark, Apache Airflow, and Apache Kafka with greater agility, and manage diverse workloads from batch processing to real-time streaming. Strategically, it unlocks significant benefits, including enhanced portability across different cloud providers and on-premises systems, thereby mitigating vendor lock-in and enabling more flexible data architectures. Furthermore, Kubernetes provides robust mechanisms for cost optimization through dynamic resource allocation and facilitates the adoption of innovative paradigms such as MLOps and Data Mesh.
However, the transformative potential of Kubernetes is accompanied by inherent complexities, particularly concerning security in distributed environments, intricate networking configurations, and the management of persistent storage for stateful applications. Overcoming these hurdles necessitates a deep understanding of Kubernetes internals, a commitment to rigorous best practices, and strategic investments in skills and platform engineering. This report provides a comprehensive analysis of both the tactical implementation and strategic implications of leveraging Kubernetes for data engineering in the cloud. It details how organizations can effectively deploy and manage data workloads, navigate common challenges, and position themselves to capitalize on future trends in the evolving data landscape. Key recommendations emphasize the importance of upskilling teams, adopting a platform mindset, prioritizing security, implementing robust cost governance, strategically evaluating managed service alternatives, embracing automation through GitOps, and pursuing an iterative approach to adoption.
I. The Symbiotic Relationship: Kubernetes and Modern Data Engineering
The confluence of burgeoning data volumes and the demand for agile, scalable data processing has catalyzed a significant evolution in data platform architecture. Kubernetes, at the vanguard of container orchestration, has become a pivotal force in this transformation, offering a robust foundation for modern data engineering practices.
A. The Evolution of Data Platforms and the Rise of Containerization
Traditional approaches to big data application management often encountered substantial obstacles. These systems typically struggled with dynamic scaling to meet fluctuating processing needs, involved intricate and time-consuming installation procedures for specialized software, and exhibited a general inflexibility that hampered rapid adaptation to new requirements. Such rigidity frequently led to the maintenance of distinct, costly ecosystems for production environments versus Big Data processing, thereby inflating operational expenditures and reducing overall efficiency. The inherent difficulties in quickly adding or removing servers to adjust computing capacity, coupled with environments often siloed for specific Hadoop-based applications rather than versatile use, underscored the need for a more adaptable infrastructure paradigm.
This environment of inflexibility and high operational costs created a compelling demand for more agile, efficient, and scalable solutions. Containerization technology, primarily through Docker, and container orchestration, with Kubernetes as the leading platform, emerged as the key enablers for this critical shift. Docker provides the means to encapsulate applications and their dependencies into lightweight, portable containers, ensuring consistency across different environments. Kubernetes then takes on the role of managing and orchestrating these containers at scale, automating deployment, scaling, and operational tasks. This combination is foundational to modernizing data engineering, offering a clear pathway away from the constraints of rigid, server-bound data platforms and towards more dynamic, software-defined infrastructures.
The adoption of Kubernetes in data engineering signifies more than a mere technological upgrade; it represents a fundamental paradigm shift. Data infrastructure is increasingly treated akin to software – versionable, consistently deployable, and amenable to extensive automation. This evolution aligns data engineering practices more closely with established DevOps principles, fostering greater agility and reliability. The capability to simplify Continuous Integration and Continuous Deployment (CI/CD) pipelines using Docker for packaging and Kubernetes for seamless deployments, including rolling updates, is a testament to this change. This results in safer changes, a lower risk profile for deployments, and a reduction in manual steps, allowing teams to automate a greater number of tasks. Such a transformation moves data infrastructure management from manual, often bespoke configurations to automated, reproducible environments, a core tenet of modern software and operations engineering.
Consequently, this technological and procedural evolution has profound implications for the skill sets required of data engineers. Proficiency in containerization technologies like Docker, orchestration platforms like Kubernetes, and CI/CD tooling is rapidly becoming as crucial as traditional knowledge of data processing frameworks and database systems. Employers increasingly prioritize candidates who can build reliable systems that perform consistently across multiple environments and leverage Kubernetes for efficient, automated resource management. This shift necessitates a re-evaluation of talent acquisition strategies, internal training programs, and the overall composition of data engineering teams to ensure they are equipped to design, build, and maintain these advanced, cloud-native data platforms.
B. Core Tenets: Why Kubernetes is a Game-Changer for Data Workloads
Kubernetes introduces several fundamental capabilities that are particularly transformative for data-intensive workloads, addressing long-standing challenges in scalability, resource utilization, environmental consistency, and operational resilience.
1. Unparalleled Scalability and Elasticity
A primary advantage of Kubernetes is its inherent ability to dynamically scale resources to meet the demands of fluctuating data workloads, capable of managing data volumes from terabytes to petabytes. This is particularly critical as data processing needs are rarely static, often varying significantly based on time of day, business cycles, or event-driven data influxes. Kubernetes achieves this through mechanisms such as Horizontal Pod Autoscaling (HPA), which automatically adjusts the number of running application instances (pods) based on observed CPU utilization, memory consumption, or custom metrics. This automated scaling capability allows data engineering teams to efficiently manage large-scale data projects and run more computational jobs on potentially less hardware by optimizing resource usage.
The direct consequence of such automated elasticity is significant cost efficiency, especially in cloud environments where resources are often billed on a pay-as-you-go basis. By automatically scaling infrastructure up to handle peak demand and, crucially, scaling down during off-peak periods, Kubernetes prevents the wasteful overprovisioning of resources while ensuring that sufficient capacity is always available to meet performance targets. This dynamic adjustment is a key enabler for effectively handling the unpredictable and often spiky nature of modern data sources, such as those found in Internet of Things (IoT) applications or real-time analytics platforms.
2. Optimized Resource Management and Efficiency
Kubernetes excels at efficient resource allocation and management, ensuring that computational jobs, such as Apache Spark processing tasks, are placed on nodes where they can execute most rapidly and effectively. This is achieved through sophisticated pod scheduling algorithms that consider node availability, resource requirements, and user-defined constraints to deploy containers onto optimal server nodes. Furthermore, Kubernetes allows for the definition of resource quotas, which enable administrators to allocate and prioritize resources for specific tasks or teams. This helps in controlling costs by preventing resource starvation for critical processes while managing overall consumption.
The benefits of Kubernetes's optimized resource management extend beyond direct infrastructure cost savings. By ensuring that applications have the resources they need when they need them, and by placing workloads intelligently, Kubernetes improves job throughput and reduces data processing times. This acceleration can significantly shorten the time-to-insight for data analytics initiatives and speed up the training cycles for machine learning models. In a competitive landscape where rapid decision-making is paramount, the ability to derive insights from data more quickly translates into a tangible business advantage.
3. Enhanced Portability and Consistency Across Environments
A long-standing challenge in software development and data engineering has been ensuring that applications behave consistently across different environments—from a developer's laptop to staging and production systems. Docker addresses this by packaging applications and their dependencies into portable containers, creating consistent runtime environments. Kubernetes orchestrates these containerized applications, guaranteeing that the setup remains identical from development through to deployment. This consistency dramatically simplifies debugging, as issues can be traced without the added complexity of environmental differences.
Moreover, this combination of containerization and orchestration provides true portability for data pipelines and applications. Workloads can be moved between different cloud providers or from on-premises data centers to the cloud (and vice-versa) with minimal to no reworking of the application setup itself. This capability is a cornerstone for organizations pursuing hybrid-cloud or multi-cloud strategies. Such portability offers significant strategic leverage, reducing the risk of vendor lock-in and allowing businesses to select cloud providers based on specific service strengths, cost advantages, regional presence, or regulatory compliance requirements. This flexibility acts as both a powerful negotiating tool with vendors and a crucial component of a comprehensive risk mitigation strategy.
4. Robust Fault Tolerance and High Availability
Data pipelines and processing jobs are often critical, long-running processes whose uninterrupted operation is vital for business continuity. Kubernetes is engineered with robust fault tolerance and self-healing mechanisms to ensure high availability for these workloads. If a container or pod crashes, Kubernetes automatically detects the failure and relaunches a new instance to replace it. Similarly, if an entire server node becomes unreliable or fails, Kubernetes can detect this condition and reschedule the workloads running on that node to healthy nodes within the cluster, seamlessly maintaining operations. This inherent resilience ensures that data pipelines can withstand common hardware or software failures without requiring significant manual intervention.
The self-healing nature of Kubernetes significantly alleviates the operational burden on data engineering teams. By automating the recovery from common failures, it minimizes the need for urgent, manual interventions, thereby reducing the frequency of "late-night emergencies" and allowing engineers to dedicate more time to development and innovation rather than operational firefighting. This not only improves system stability but also contributes positively to team morale and overall productivity, as engineers can focus on higher-value tasks.
II. Tactical Blueprint: Implementing Data Engineering Workloads on Kubernetes
Leveraging Kubernetes for data engineering involves a series of tactical implementations, from orchestrating data pipelines to running specialized data processing tools. This section outlines the practical approaches for deploying and managing common data engineering workloads on Kubernetes.
A. Orchestrating Resilient Data Pipelines
Data pipelines are the lifelines of any data-driven organization, and Kubernetes provides a robust framework for building and managing them with enhanced resilience and efficiency.
1. Containerizing ETL/ELT Processes
Modern data workflows are complex, often involving a sequence of interconnected services that handle data ingestion, transformation, validation, and loading into storage or analytical systems. Kubernetes excels in managing these intricate processes by orchestrating Docker containers, ensuring that data pipelines operate smoothly and reliably. The fundamental steps of a data pipeline—Extract, Transform, Load (ETL) or Extract, Load, Transform (ELT)—can be effectively mapped to Kubernetes objects. Each distinct processing stage (e.g., data extraction from a source, a specific transformation logic, loading to a data warehouse) can be encapsulated within one or more pods, typically managed by Kubernetes Deployments or StatefulSets for stateless and stateful components, respectively. Intermediate or processed data can be persisted using Kubernetes Persistent Volumes.
This architectural pattern of containerizing each step of an ETL/ELT pipeline as a distinct microservice running in its own Kubernetes pod offers significant advantages. It allows for the independent scaling of pipeline components; for instance, if a transformation step becomes a bottleneck, only that component needs to be scaled out, without affecting other parts of the pipeline. Updates and maintenance also become more manageable, as individual components can be modified or replaced with minimal disruption to the overall workflow. This modularity enhances the resilience of the data pipeline, as a failure in one component is less likely to cascade and bring down the entire process. Furthermore, it promotes agility, as new features or fixes can be deployed to specific components more rapidly.
2. Implementing CI/CD for Data Pipelines
The principles of Continuous Integration and Continuous Deployment (CI/CD), widely adopted in software engineering, are increasingly vital for data engineering to ensure agility, reliability, and speed. Docker simplifies the CI/CD process by enabling new changes to data processing logic or pipeline configurations to be packaged into container images and tested in isolated, consistent environments. Kubernetes then facilitates seamless deployment of these updated components into staging or production environments. It supports strategies like rolling updates, which gradually replace old versions of pipeline components with new ones, ensuring minimal to zero downtime for the data pipeline.
Integrating CI/CD practices with Kubernetes for data pipelines fundamentally transforms data engineering from what can be a slow, manual, and error-prone process into a more agile, automated, and software-like development lifecycle. This transformation allows for faster iteration on data pipeline logic, leading to more reliable deployments. The ability to test changes in isolation and deploy them automatically with controlled rollouts significantly reduces the risk of breaking entire systems due to a single misconfiguration or bug. Ultimately, this accelerated and safer deployment cycle translates into quicker delivery of data products and insights to the business, enhancing the value derived from data assets.
B. Powering Data Ecosystems: Running Key Tools on Kubernetes
Kubernetes serves as a versatile platform for deploying and managing a wide array of data processing tools and frameworks, enabling organizations to build comprehensive data ecosystems.
1. Apache Spark on Kubernetes: From Batch to Real-Time Analytics
Apache Spark is a dominant distributed processing engine for large-scale data analytics and machine learning. Running Spark on Kubernetes allows organizations to leverage Kubernetes's dynamic scaling and resource management capabilities for their Spark workloads. The process of setting up Spark on Kubernetes typically involves several key steps:
Kubernetes Cluster Setup: A functional Kubernetes cluster is the primary prerequisite. This can be a local development cluster like Minikube or a production-grade managed Kubernetes service such as Amazon EKS, Google Kubernetes Engine (GKE), or Azure Kubernetes Service (AKS).
Apache Spark Preparation: The appropriate Spark distribution needs to be downloaded and configured. This includes setting environment variables like SPARK_HOME.
Docker Image Creation: Custom Docker images must be built for the Spark driver and executor pods. These images should include the Spark runtime and any necessary dependencies for the Spark applications.
RBAC Configuration: Kubernetes Role-Based Access Control (RBAC) must be configured with appropriate service accounts and roles to allow Spark components (driver and executors) to interact with the Kubernetes API server for creating and managing pods.
Job Submission: Spark applications are submitted to the Kubernetes cluster using the spark-submit command. This command requires specifying the Kubernetes master URL, the deployment mode (cluster mode, where the driver runs inside a pod, or client mode, where the driver runs outside the cluster), container image locations, and other Spark configurations.
To simplify the deployment and lifecycle management of Spark applications on Kubernetes, the Spark Operator can be utilized. The Spark Operator extends Kubernetes with Custom Resource Definitions (CRDs) such as SparkApplication and ScheduledSparkApplication, allowing users to define and manage Spark jobs declaratively using familiar Kubernetes YAML manifests. The operator automates the spark-submit process and manages the Spark application lifecycle, including monitoring and updates.
The choice between a manual spark-submit setup and using the Spark Operator often presents a trade-off. The Spark Operator significantly simplifies routine Spark job management and integrates well with Kubernetes-native workflows, making it easier for teams less deeply versed in Spark-on-Kubernetes internals. However, a manual setup, while more complex, offers finer-grained control over every aspect of the Spark deployment, which might be necessary for highly specific performance tuning or complex configurations. Organizations must weigh their need for operational simplicity against the requirement for deep customization and control based on their team's expertise and the nature of their Spark workloads.
2. Apache Airflow on Kubernetes: Dynamic Workflow Orchestration
Apache Airflow is a widely adopted platform for programmatically authoring, scheduling, and monitoring workflows. Deploying Airflow on Kubernetes enhances its capabilities by enabling dynamic resource allocation and task execution in isolated containerized environments. There are several common methods for running Airflow on Kubernetes :
KubernetesPodOperator: This Airflow operator allows individual tasks within a Directed Acyclic Graph (DAG) to be executed as a Kubernetes pod running a specified Docker image. It is particularly useful for running containerized workloads that might have specific dependencies or resource requirements, and it's often considered the easiest way to start integrating existing containerized tasks into Airflow workflows running on Kubernetes. Setup and management are minimal, and it offers high flexibility as parameters and arguments can be customized per workload.
KubernetesExecutor: When Airflow is configured with the KubernetesExecutor, each task instance defined in a DAG is natively run as a separate pod on the Kubernetes cluster. This approach leverages Kubernetes's elasticity for every task, allowing for fine-grained resource allocation and scaling on a per-task basis. It eliminates the need to build custom containers for simple Python tasks if the base Airflow worker image suffices, though custom images can still be specified.
KEDA (Kubernetes Event-Driven Autoscaling) with CeleryExecutor: This method combines the CeleryExecutor, a popular Airflow executor for distributed task processing, with KEDA. KEDA scales the number of Airflow Celery workers (running as pods) dynamically based on the number of tasks in the queue (typically by querying the Airflow metadata database). A key advantage is its ability to scale workers down to zero when there are no tasks, and then scale up as new tasks arrive, leading to efficient resource utilization.
A PostgreSQL database is commonly used as the backend for the Airflow metadata DB when deploying on Kubernetes. The choice of executor significantly impacts resource utilization, task isolation, and operational overhead. The KubernetesExecutor provides strong task isolation and per-task resource specification but might incur higher startup latency for each task pod. The KubernetesPodOperator offers flexibility for diverse containerized tasks. The CeleryExecutor with KEDA can offer lower overhead for many sequential tasks within a worker and efficient scaling to zero, but introduces Celery as an additional component to manage alongside KEDA. This architectural decision requires careful consideration of workload characteristics, desired elasticity, and the team's familiarity with the different components.
3. Apache Kafka on Kubernetes: Building Scalable Streaming Platforms
Apache Kafka is a distributed streaming platform essential for building real-time data pipelines and streaming applications. Due to its stateful nature (brokers store data in topics and partitions), deploying and managing Kafka has traditionally been complex. Kubernetes, particularly when augmented with Operators, provides a robust environment for running Kafka clusters with high availability and scalability.
Kafka can be deployed on Kubernetes using Helm charts or, more commonly for production systems, through a Kubernetes Operator such as Strimzi. Strimzi is an open-source project that simplifies running Kafka on Kubernetes by providing container images and Operators to manage the Kafka cluster (brokers, Zookeeper), as well as related entities like Kafka Connect, Kafka MirrorMaker, and even Kafka topics and users. Kubernetes features like rolling updates for brokers, service discovery for client connectivity, and automated scaling based on metrics like CPU or network traffic are highly beneficial for managing Kafka clusters.
Key tactical considerations for deploying Kafka on Kubernetes include:
Operator Selection: Using a mature Operator like Strimzi is highly recommended as it encapsulates domain-specific knowledge for Kafka lifecycle management (e.g., handling broker scaling, ordered updates, configuration management, certificate management).
High Availability: Deploy Kafka brokers across multiple availability zones (AZs) within a Kubernetes cluster to ensure fault tolerance against AZ failures.
Persistent Storage: Kafka brokers require persistent storage. This must be configured using Kubernetes PersistentVolumes and PersistentVolumeClaims, often backed by network-attached storage or cloud provider block storage. The choice of storage class can significantly impact performance.
Zookeeper Management: Kafka relies on Zookeeper for metadata management and coordination. Operators like Strimzi typically manage the Zookeeper ensemble alongside the Kafka brokers.
Networking: Exposing Kafka brokers to clients outside the Kubernetes cluster requires careful network configuration, often using Kubernetes Services of type LoadBalancer or NodePort, or an Ingress controller, along with appropriate security group/firewall rules.
Resource Allocation: Kafka brokers can be resource-intensive (CPU, memory, disk I/O). Proper resource requests and limits must be set for Kafka pods.
Monitoring: Integrate with monitoring solutions like Prometheus and Grafana to track Kafka cluster health, broker performance, topic metrics, and consumer lag.
For complex stateful systems like Kafka, Kubernetes Operators are more than a convenience; they are often a near necessity for reliable production deployments. They codify operational best practices and automate intricate lifecycle management tasks that would otherwise require deep expertise in both Kafka and Kubernetes internals. This significantly lowers the barrier to entry and reduces the ongoing operational burden for running such critical infrastructure on Kubernetes.
C. Managing Diverse Data Workloads
Kubernetes provides native constructs and supports patterns for managing a wide spectrum of data workloads, from traditional batch processing to modern real-time streaming analytics.
1. Efficient Batch Processing with Kubernetes Jobs and CronJobs
Batch processing remains a fundamental component of many data engineering workflows, used for tasks such as nightly ETL operations, periodic report generation, data validation, and machine learning model training. Kubernetes offers native resources specifically designed for managing these types of finite, run-to-completion tasks:
Kubernetes Job: A Job object creates one or more pods and ensures that a specified number of them successfully terminate. If a pod created by a Job fails (e.g., due to an application error or node failure), the Job controller can retry the execution by creating a new pod until the desired number of completions is reached. Kubernetes supports different types of Jobs:
Simple Job: Runs a single pod to completion. Suitable for tasks that can be completed in a single, self-contained execution.
Parallel Job: Runs multiple pods concurrently. This can be configured as a "work queue" pattern (where pods pick up tasks independently) or to run a fixed number of pods in parallel until a certain number of total completions is achieved. The parallelism field specifies how many pods can run concurrently, and the completions field specifies the total number of successful completions needed for the Job to be considered finished.
Kubernetes CronJob: A CronJob object manages Job objects on a time-based schedule, similar to a traditional cron daemon. Users define a cron schedule (e.g., "run every night at 2 AM"), and the CronJob controller creates a Job according to that schedule. This is ideal for recurring batch tasks.
Tactical implementation involves defining YAML manifests for Job or CronJob resources. For a Job, the manifest specifies a pod template, including the container image to run, commands, arguments, and resource requests/limits. The restartPolicy for pods within a Job is typically set to OnFailure or Never, as the Job controller handles retries at the pod level. For a CronJob, the manifest includes the cron schedule string and a jobTemplate that defines the Job to be created.
The use of Kubernetes Jobs and CronJobs for batch workloads offers significant advantages in resource optimization, particularly in cloud environments. Resources are consumed only when the batch job is actively running; once the job completes, the pods are terminated, and the resources are released. This on-demand resource consumption is highly cost-effective compared to maintaining dedicated servers or virtual machines that might sit idle for extended periods waiting for sporadic batch tasks. Common use cases include periodic ETL pipelines, data analysis tasks, scheduled backups, system maintenance routines, report generation, and image processing.
2. Enabling Real-Time Data Streaming and Analytics
Beyond batch processing, Kubernetes is increasingly utilized to host and manage real-time data streaming and analytics applications. These applications, often built using frameworks like Apache Flink, Kafka Streams, or Spark Streaming, process data as it arrives, enabling immediate insights and actions. Kubernetes can ensure that these streaming applications operate at peak efficiency and maintain high availability. The platform's ability to quickly scale out processing instances (pods) in response to increasing data velocity or processing load is crucial for real-time systems.
Key Kubernetes features that support real-time streaming include:
Scalability: Horizontal Pod Autoscaling can be used to adjust the number of stream processing pods based on metrics like message queue length, processing latency, or CPU utilization.
Fault Tolerance: Kubernetes's self-healing capabilities ensure that if a stream processing pod fails, it is quickly restarted or replaced, minimizing data loss and processing interruptions.
Service Discovery and Load Balancing: Kubernetes Services provide stable network endpoints for streaming applications and can distribute incoming data streams or client connections across available processing pods.
Resource Management: Fine-grained resource requests and limits ensure that streaming applications get the necessary CPU and memory, while also preventing them from monopolizing cluster resources.
Log Streaming: For real-time monitoring, debugging, and operational visibility, Kubernetes provides mechanisms to stream logs continuously from running containers using commands like kubectl logs -f. This allows operators to observe application behavior and diagnose issues as they occur.
The architectural paradigm of microservices, which Kubernetes excels at managing, is highly synergistic with modern streaming architectures. Complex streaming pipelines often consist of multiple, independently deployable and scalable components—for example, separate services for data ingestion, data enrichment, real-time analytics, and serving results. Kubernetes can manage each of these components as a distinct microservice, providing the necessary isolation, scalability, and resilience for the end-to-end real-time pipeline. This allows different parts of the streaming application to be scaled and updated independently, catering to their specific demands and enhancing overall system robustness and agility. Real-time processing is gaining significant traction for use cases requiring on-the-fly decision-making, such as fraud detection, IoT sensor data analysis, and personalized recommendations.
III. Strategic Imperatives: Leveraging Kubernetes in Cloud Data Architectures
Beyond the tactical implementation of data workloads, Kubernetes offers significant strategic advantages that can shape an organization's overall cloud data architecture, influencing decisions around cloud adoption models, financial governance, and the balance between custom-built solutions and managed services.
A. Navigating the Cloud Landscape: Multi-Cloud and Hybrid-Cloud Strategies
The inherent portability of Kubernetes, stemming from its abstraction over the underlying infrastructure, is a powerful enabler for organizations pursuing multi-cloud or hybrid-cloud strategies. Data pipelines and applications containerized and orchestrated by Kubernetes can, in principle, be moved between different public cloud providers (e.g., AWS, Azure, GCP) or between on-premises data centers and public clouds with reduced friction. Kubernetes can manage workloads across both on-premises and cloud resources, providing a unified operational fabric that simplifies the management of such hybrid deployments. A multi-cloud Kubernetes strategy involves deploying and managing Kubernetes clusters across multiple cloud providers concurrently, potentially running different components of an application or different applications in distinct clouds.
Organizations adopt these complex cloud strategies for various reasons: to avoid vendor lock-in, optimize costs by leveraging competitive pricing or specialized services from different providers, meet stringent data sovereignty or regulatory requirements by keeping data in specific geographies, or enhance disaster recovery capabilities. Kubernetes provides the consistent orchestration layer that makes these strategies technically feasible.
However, while Kubernetes offers a common operational interface, achieving optimal performance, cost-efficiency, and seamless integration in a multi-cloud or hybrid-cloud environment requires careful strategic planning beyond simple workload portability. Each cloud provider has its own unique set of services, APIs, networking capabilities, and storage solutions. A "pure abstraction" approach that ignores these underlying differences might fail to leverage platform-specific optimizations or could encounter unforeseen integration challenges. For instance, networking between clusters in different clouds needs robust and secure solutions like VPN peering or a service mesh (e.g., Istio), and data management might require distributed storage systems (e.g., Ceph, Portworx) or well-defined data synchronization strategies.
Key strategic considerations for implementing multi-cloud or hybrid-cloud data platforms with Kubernetes include:
Strategic Workload Placement: Decisions on where to run specific data workloads should be driven by factors such as cost, performance needs, data locality (proximity to data sources or consumers), data sovereignty regulations, and the availability of specialized cloud services.
Inter-Cloud Networking and Connectivity: A robust plan for secure, low-latency, and cost-effective network connectivity between Kubernetes clusters residing in different cloud environments or on-premises locations is critical.
Data Management, Storage, and Synchronization: Strategies for managing persistent data across distributed environments are essential. This may involve choosing distributed storage solutions that can span multiple clouds or implementing mechanisms for data replication, caching, or federation.
Unified Control Plane and Management: For managing a fleet of Kubernetes clusters across diverse environments, organizations may need to consider multi-cluster management tools or a unified control plane that provides centralized visibility and governance.
Consistent Security and Compliance: Enforcing uniform security policies, identity and access management, and compliance controls across all Kubernetes deployments, regardless of their location, is a significant challenge that requires careful planning and tooling (e.g., Open Policy Agent - OPA).
Successfully navigating this landscape means that while Kubernetes provides the common ground, the strategy must intelligently integrate Kubernetes with the unique strengths and characteristics of each chosen cloud environment or on-premises infrastructure.
B. Financial Governance: Cost Optimization for Kubernetes-Based Data Platforms
While Kubernetes offers powerful capabilities for dynamic scaling and resource management that can contribute to cost optimization , cloud costs can escalate rapidly if not proactively managed. Effective financial governance for Kubernetes-based data platforms is crucial. This involves a continuous process of monitoring resource consumption, identifying inefficiencies, implementing optimization measures, and tracking their impact.
Key cost optimization strategies for Kubernetes environments include:
Right-Sizing Resources: This is the foundational practice of matching the CPU and memory resources allocated to containers (via requests and limits in pod specifications) to the actual needs of the applications. Overprovisioning leads to wasted expenditure, while underprovisioning can cause performance degradation or application crashes. Regular monitoring of resource utilization patterns and adjusting configurations accordingly is essential.
Leveraging Autoscaling Mechanisms:
Horizontal Pod Autoscaler (HPA): Automatically adjusts the number of pod replicas based on observed metrics like CPU utilization or custom metrics, scaling out during high load and in during low load.
Vertical Pod Autoscaler (VPA): Dynamically adjusts the CPU and memory requests and limits for individual running pods based on their historical usage patterns, helping to fine-tune resource allocation for applications with unpredictable loads.
Cluster Autoscaler: Adds or removes nodes from the Kubernetes cluster based on overall demand, ensuring that there is enough capacity to run all pods without maintaining excessive idle nodes.
Utilizing Spot Instances or Preemptible VMs: For fault-tolerant and interruptible workloads, such as many batch processing jobs or some types of data analysis, using lower-cost Spot Instances (AWS) or Preemptible VMs (GCP, Azure) can yield significant savings. However, applications must be designed to handle potential interruptions. Notably, Azure and GCP tend to offer more predictable spot pricing with less frequent changes compared to the highly dynamic spot market on AWS.
Efficient Scheduling and Resource Quotas: Kubernetes resource quotas can be used to allocate resources to specific teams or projects, helping to control costs and ensure that critical applications are not starved of resources.
Optimizing Instance Selection: Choosing the most cost-effective virtual machine instance types from cloud providers is important. For example, Arm-based CPU instances often offer better price-performance ratios than traditional x86 instances, with Azure showing a particularly large pricing gap that can be leveraged for savings.
Reserved Instances and Committed Use Discounts: For workloads with predictable, long-term resource needs, committing to 1-year or 3-year Reserved Instances (AWS), Reserved Savings (Azure), or Committed Use Discounts (GCP) can provide substantial discounts over on-demand pricing.
Streamlining Logging and Monitoring: Consolidating logging and monitoring tools can reduce the overhead costs associated with running multiple, potentially overlapping systems that consume compute resources.
Cost Management Tools: Specialized Kubernetes cost optimization tools, such as PerfectScale, can provide AI-driven recommendations, real-time alerts for cost anomalies, and detailed visibility into resource usage, helping teams proactively manage and reduce cloud expenses.
Effective cost optimization in Kubernetes is not a one-time configuration task but an ongoing lifecycle. It begins with robust observability—collecting historical data on CPU, memory, and other metrics to understand consumption patterns. This is followed by analysis to identify areas of overprovisioning or inefficiency. Optimization strategies are then implemented, and their impact is continuously monitored. This iterative feedback loop of monitoring, analyzing, acting, and re-monitoring is crucial for achieving and maintaining cost control as data workloads and application requirements evolve.
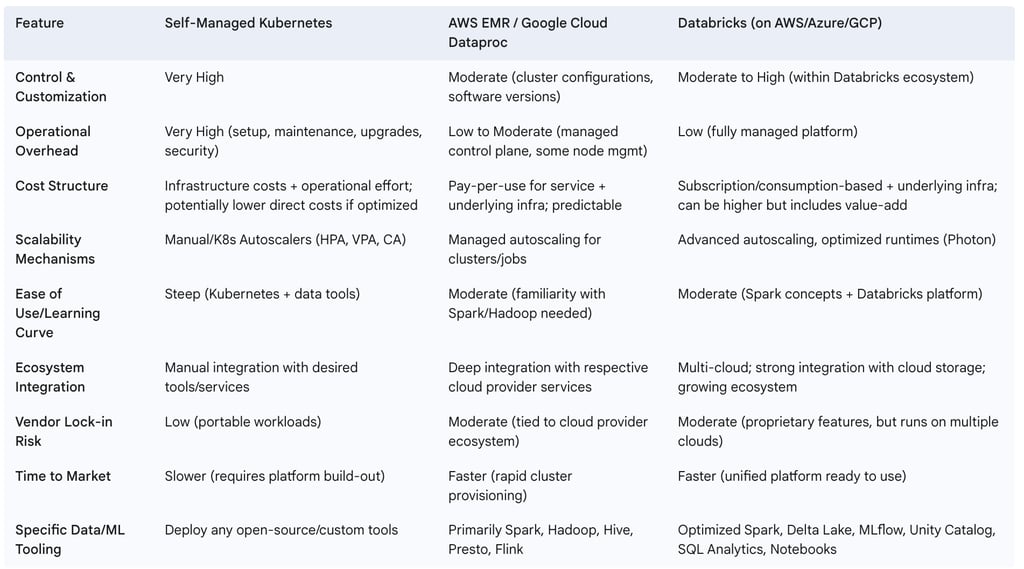
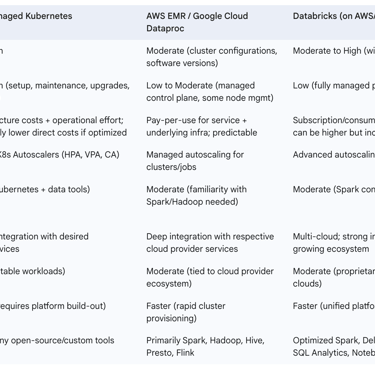
C. The Build vs. Buy Dilemma: Kubernetes vs. Managed Data Services (e.g., EMR, Dataproc, Databricks)
A critical strategic decision for organizations adopting cloud-based data engineering is whether to build their data platforms on self-managed Kubernetes or to utilize managed data services offered by cloud providers, such as AWS EMR (Elastic MapReduce), Google Cloud Dataproc, or unified analytics platforms like Databricks (available on AWS, Azure, and GCP).
Self-Managed Kubernetes offers the highest degree of control and customization. Organizations can tailor every aspect of the cluster and the deployed data tools to their specific requirements. It provides maximum portability across different cloud providers and on-premises environments, mitigating vendor lock-in. While direct software licensing costs might be lower if relying on open-source components, self-managed Kubernetes incurs significant operational overhead. Teams require deep expertise in Kubernetes administration, networking, security, storage, and the data tools themselves. Setup, configuration, maintenance, upgrades, and troubleshooting are entirely the organization's responsibility.
Managed Data Services abstract away much of this infrastructure complexity. Services like AWS EMR and Google Cloud Dataproc provide managed environments for running big data frameworks like Spark and Hadoop, offering rapid cluster provisioning, automated scaling, and integration with their respective cloud ecosystems. Platforms like Databricks go further, providing a unified analytics platform with an optimized Spark runtime (Databricks Runtime, Photon engine), collaborative notebooks, integrated MLOps tools (MLflow), a feature store, and robust data governance features (Unity Catalog). These services aim to reduce operational burden, allowing data teams to focus more on deriving insights from data rather than managing infrastructure.
The choice between these approaches involves a trade-off along a spectrum of abstraction, primarily balancing the value-added features and operational ease of managed services against the granular control and customization potential of self-managed Kubernetes. There isn't a universally "best" choice; the optimal path depends on factors such as:
Organizational Maturity and Skillset: Teams with limited Kubernetes expertise may find managed services more accessible and productive.
Time-to-Market Pressures: Managed services generally offer faster deployment and setup times for data platforms.
Need for Customization: Highly specific or unique requirements might necessitate the control offered by self-managed Kubernetes.
Cost Considerations: This includes not just direct infrastructure or service costs, but also the "opportunity cost" of engineering effort spent on building and maintaining infrastructure versus developing data products. While self-managed Kubernetes might seem cheaper "on the books," the total cost of ownership (TCO), including staffing and operational effort, can be higher. Some users report higher direct spending on platforms like Databricks compared to EMR but justify it with a more robust and enjoyable platform that boosts developer productivity.
Strategic Importance of Specific Features: Platforms like Databricks offer proprietary optimizations and integrated tooling that would be complex and costly to replicate on a self-managed Kubernetes stack.
The following table provides a comparative analysis:
Table 1: Kubernetes vs. Managed Data Services - A Comparative Analysis
Ultimately, the decision requires a thorough assessment of the organization's specific needs, resources, strategic priorities, and tolerance for operational complexity versus the desire for managed convenience and specialized features.
IV. Navigating Complexity: Challenges and Best Practices
While Kubernetes offers immense power and flexibility for data engineering, its adoption is not without challenges. Understanding these hurdles and adhering to established best practices are crucial for building stable, secure, efficient, and cost-effective data platforms on Kubernetes.
A. Common Hurdles in Kubernetes Adoption for Data Engineering
Deploying and managing data workloads on Kubernetes can present several common challenges related to security, networking, storage, and operational complexity.
1. Addressing Security Concerns in Distributed Data Environments
Security is a paramount concern in any data platform, and the distributed and complex nature of Kubernetes can introduce unique vulnerabilities if not managed diligently. Misconfigurations are a frequent source of security gaps, potentially exposing sensitive data or control planes. Key areas requiring robust security measures include:
Kubernetes API Server Security: Protecting access to the API server, which is the control hub of the cluster.
Node Security: Hardening the underlying worker nodes that run data workloads.
Pod Security: Enforcing security policies for containers running within pods, such as restricting privileges and capabilities.
Data Security: Ensuring data is encrypted at rest (in persistent storage) and in transit.
Secrets Management: Securely storing and managing sensitive information like passwords, API keys, and certificates.
Cluster Access and Authentication: Implementing strong authentication and authorization mechanisms for users and services interacting with the cluster.
A critical aspect to recognize, especially when using managed Kubernetes services (like EKS, GKE, AKS), is the shared responsibility model for security. While the cloud provider secures the Kubernetes control plane and underlying infrastructure, the user is responsible for securing their workloads, network configurations within the cluster (e.g., NetworkPolicies), data stored and processed by their applications, identity and access management for their applications, and the container images themselves. Misunderstanding or neglecting these user-side responsibilities can lead to significant vulnerabilities, even on a managed Kubernetes platform. Data platforms, being repositories of valuable information, are prime targets, necessitating a multi-layered security approach.
Recommended solutions and best practices include:
Implement strict Role-Based Access Control (RBAC): Grant permissions based on the principle of least privilege to users and service accounts.
Secure etcd: Ensure the etcd datastore (which stores cluster state and secrets) is protected with TLS encryption, firewall rules, and encryption at rest.
Isolate Kubernetes Nodes: Avoid exposing worker nodes directly to the public internet. Use private networks and bastion hosts for access.
Utilize Network Policies: Define granular network policies to control traffic flow between pods and namespaces, restricting communication to only what is necessary.
Employ Secure Secrets Management: Use tools like HashiCorp Vault or Kubernetes Secrets with encryption at rest enabled to manage sensitive information.
Regularly Scan Container Images: Scan container images for known vulnerabilities before deployment and continuously monitor them.
Keep Kubernetes Updated: Apply security patches and updates to Kubernetes components and node operating systems promptly.
Use Security Modules: Leverage Linux security modules like AppArmor or SELinux for enhanced process isolation on nodes.
2. Tackling Networking Complexities
Kubernetes networking is inherently powerful and flexible, but its complexity can be a significant hurdle. Traditional networking approaches often do not map directly to Kubernetes's dynamic, pod-centric model. Common challenges include:
Pod-to-Pod Communication: Ensuring reliable and secure communication between pods, potentially across different nodes.
Pod-to-Service Communication: Managing how pods discover and connect to internal services.
External Access (Ingress): Exposing services to users or systems outside the Kubernetes cluster in a secure and manageable way.
Multi-Tenancy: Isolating network traffic and enforcing policies in shared clusters where multiple applications or teams coexist.
Static IP Management: Difficulties in implementing traditional IP-based security policies due to the ephemeral nature of pod IPs.
For data-intensive applications, network performance, latency, and data locality are critical. Misconfigured or sub-optimal Kubernetes networking can lead to bottlenecks, high data transfer costs (especially across availability zones or regions), and degraded application performance. Advanced networking configurations, such as selecting an appropriate Container Network Interface (CNI) plugin that meets performance and feature requirements, implementing a service mesh for sophisticated traffic routing and observability, and defining precise network policies for security and segmentation, are often necessary to optimize data workloads. For instance, ensuring efficient communication between Spark driver and executor pods, particularly in client mode, is crucial and can be hampered by network misconfigurations.
Recommended solutions and best practices include:
Choose a Suitable CNI Plugin: Select a CNI plugin (e.g., Calico, Cilium, Flannel) that aligns with performance, scalability, and security policy enforcement needs.
Implement a Service Mesh: Consider using a service mesh like Istio or Linkerd for advanced features such as traffic management (e.g., canary deployments, A/B testing), mTLS encryption, observability, and fine-grained access control between microservices.
Use Ingress Controllers: Manage external access to HTTP/S services within the cluster using Ingress controllers (e.g., Nginx Ingress, Traefik), and secure them with TLS.
Define Clear Network Policies: Implement Kubernetes NetworkPolicies to control pod-to-pod communication based on labels and selectors, enforcing a default-deny stance where appropriate.
3. Managing Persistent Storage for Stateful Applications
Many critical data engineering tools, such as databases (e.g., PostgreSQL for Airflow metadata ), message queues (e.g., Apache Kafka ), and distributed file systems, are stateful and require persistent storage that outlives individual pods. Kubernetes provides the PersistentVolume (PV) and PersistentVolumeClaim (PVC) abstractions to manage storage dynamically. PVs represent a piece of storage in the cluster, while PVCs are requests for storage by users/pods.
However, simply providing persistence is not enough. The choice and configuration of the underlying storage solution can become a significant performance bottleneck for I/O-intensive data workloads, such as database operations or Spark shuffle stages. Factors like the storage class used, the capabilities of the storage provisioner (often a Container Storage Interface - CSI driver), network latency to the storage backend, and the provisioned IOPS (Input/Output Operations Per Second) all need careful consideration.
Several open-source solutions aim to provide robust and scalable persistent storage for Kubernetes:
OpenEBS: Employs a Container Attached Storage (CAS) architecture, where each volume has its own dedicated storage controller pod. It supports synchronous replication across availability zones.
Rook: An orchestration framework for various storage solutions, with Ceph being a popular backend. Rook with Ceph provides highly scalable distributed block, file, and object storage.
Longhorn: A distributed lightweight block storage solution built using microservices. It offers features like replication, snapshots, backups to S3/NFS, and cross-cluster recovery.
GlusterFS: A distributed network filesystem that can be integrated with Kubernetes, often using Heketi for volume management.
Recommended solutions and best practices include:
Select Appropriate Storage Solutions: Choose a storage system based on the specific performance (IOPS, throughput, latency), scalability, data protection (snapshots, backups), and high availability requirements of the stateful applications.
Understand PV Reclaim Policies: Configure PV reclaim policies correctly: Retain is crucial for critical production data to prevent data loss when a PVC is deleted, while Delete may be suitable for temporary or ephemeral data.
Use StatefulSets for Stateful Applications: For applications that require stable persistent storage, unique and stable network identifiers (hostnames), and ordered, graceful deployment and scaling, Kubernetes StatefulSets are the appropriate workload controller.
Consider Cloud Provider Storage: When running in a specific cloud, leveraging the provider's native storage services (e.g., Amazon EBS, GCE Persistent Disk, Azure Disk Storage) via their CSI drivers can offer optimized performance and integration, though this may impact portability.
4. Overcoming Operational Complexity and Skill Gaps
Kubernetes is an undeniably complex system, comprising multiple layers of abstraction from the underlying infrastructure (nodes, networking, storage) to the Kubernetes control plane components (API server, scheduler, controller manager, etcd) and the workloads running on it (pods, deployments, services, etc.). Troubleshooting issues in such an environment, where the root cause could lie at any level—from a misconfigured container definition to a network problem or a cluster-level issue—requires a high degree of Kubernetes knowledge and extensive containerization experience. This steep learning curve and the ongoing operational burden can be significant challenges for teams new to Kubernetes or those with limited dedicated platform operations resources.
The complexity of managing Kubernetes, especially for specialized and demanding workloads like data engineering and machine learning, is a key factor driving the emergence of Platform Engineering teams within organizations. These teams focus on building internal platforms on top of Kubernetes. Their goal is to abstract away the underlying intricacies of the Kubernetes environment and provide data scientists, ML engineers, and data engineers with simpler, standardized, and often self-service tools and workflows. This approach allows domain specialists to focus on their core tasks—developing data pipelines, training models, and deriving insights—without needing to become Kubernetes experts themselves. Data science platforms built on Kubernetes, for example, often aim to provide a user-friendly environment that hides the Kubernetes-native complexity from the end-users. By providing curated tools, CI/CD pipelines, monitoring solutions, and enforcing governance and best practices at the platform level, Platform Engineering can significantly reduce the cognitive load on data teams and accelerate innovation.
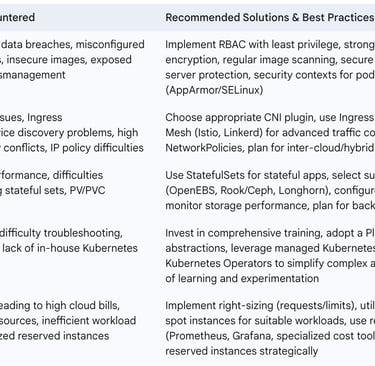
The following table summarizes common challenges and mitigation strategies:
Table 2: Common Challenges in Kubernetes for Data Engineering & Mitigation Strategies

B. Blueprint for Success: Best Practices for Data Engineering on Kubernetes
Adhering to a set of well-defined best practices is paramount for achieving stable, secure, efficient, and maintainable data engineering platforms on Kubernetes. These practices span resource management, application health, security, configuration management, and operational hygiene.
Key best practices include:
Resource Management: Accurately define CPU and memory requests (guaranteed resources) and limits (maximum allowable resources) for every container within a pod. This prevents resource contention, ensures predictable performance, and aids the Kubernetes scheduler in making optimal placement decisions. Without proper limits, a single runaway pod could monopolize node resources, causing other critical workloads to be evicted or crash.
Health Probes: Configure livenessProbe, readinessProbe, and startupProbe for all applications.
livenessProbe: Checks if an application is still running; if it fails, Kubernetes will restart the container.
readinessProbe: Determines if an application is ready to accept traffic; if it fails, the pod is removed from service endpoints until it becomes ready. This is crucial for preventing traffic from being sent to pods that are starting up or temporarily overloaded.
startupProbe: Used for applications that have a slow startup time, preventing liveness/readiness probes from killing the application before it's fully initialized. Implementing these probes enables Kubernetes to manage application health automatically, leading to a proactive operational model where the system self-heals rather than requiring constant manual intervention.
Namespaces: Utilize Kubernetes namespaces to create logical partitions within a cluster for different environments (e.g., dev, staging, prod), teams, or applications. Apply resource quotas at the namespace level to limit total resource consumption and use network policies to control traffic flow between namespaces, enhancing security and isolation.
Role-Based Access Control (RBAC): Strictly implement the principle of least privilege using RBAC. Define roles with specific permissions and bind them to users or service accounts, ensuring they only have the access necessary to perform their tasks.
Network Policies: By default, all pods in a Kubernetes cluster can communicate with each other. Implement network policies to restrict pod-to-pod and namespace-to-namespace communication, allowing only explicitly permitted traffic flows. This significantly enhances the security posture.
Secure Container Images: Use minimal, trusted base images for containers. Regularly scan images for vulnerabilities using tools like Trivy or Clair. Avoid running containers as root where possible and minimize the software installed in images to reduce the attack surface.
GitOps for Configuration Management: Manage all Kubernetes resource configurations (YAML manifests, Helm charts, Kustomize overlays) declaratively using a version control system like Git as the single source of truth. Employ GitOps reconciliation tools (e.g., ArgoCD, FluxCD) to automatically synchronize the desired state defined in Git with the actual state of the cluster. This ensures consistency, auditability, simplifies deployments, and facilitates rapid recovery or rollback in case of issues.
Autoscaling: Strategically implement Horizontal Pod Autoscaler (HPA), Vertical Pod Autoscaler (VPA), and the Cluster Autoscaler to dynamically adjust resources based on demand, optimizing both performance and cost.
Persistent Storage Management: Choose appropriate reclaim policies for PersistentVolumes (Retain for critical data, Delete for transient data) and select storage solutions that meet the performance and durability requirements of stateful data applications.
Observability (Logging, Monitoring, Alerting): Implement a comprehensive observability stack. This includes centralized logging (e.g., EFK stack - Elasticsearch, Fluentd, Kibana), metrics collection and monitoring (e.g., Prometheus and Grafana), and proactive alerting to detect and diagnose issues quickly.
Workload Placement: Utilize node selectors, node/pod affinities and anti-affinities, taints, and tolerations to influence how pods are scheduled onto nodes. This can be used to optimize for performance (e.g., placing compute-intensive pods on nodes with powerful CPUs), ensure high availability (e.g., spreading replicas across different failure domains), or dedicate nodes for specific workloads.
Pod Disruption Budgets (PDBs): For critical applications, define PDBs to limit the number of pods that can be voluntarily disrupted simultaneously during planned maintenance activities (like node upgrades) or cluster scaling events. This helps maintain application availability.
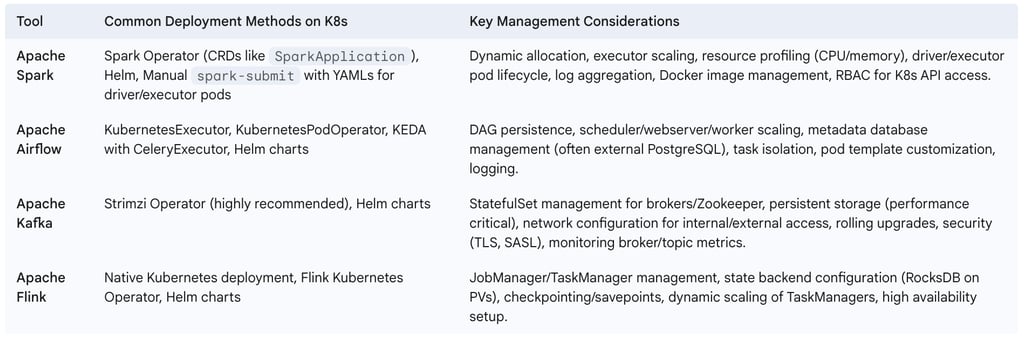
The following table offers a high-level overview of deploying and managing key data engineering tools on Kubernetes:
Table 3: Key Data Engineering Tools on Kubernetes - Deployment and Management Overview
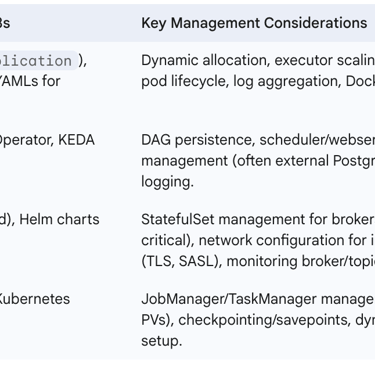
By proactively addressing potential challenges and consistently applying these best practices, organizations can significantly enhance the stability, security, performance, and cost-effectiveness of their Kubernetes-based data engineering platforms, thereby maximizing the return on their investment in this transformative technology.
V. The Horizon: Future Trends for Kubernetes in the Data Landscape
Kubernetes is not merely a static platform but an evolving ecosystem that continues to adapt and integrate with emerging paradigms in data management and machine learning. Its foundational capabilities in orchestration, scalability, and portability position it as a key enabler for several significant future trends in the data landscape.
A. Kubernetes as the Backbone for MLOps
Machine Learning Operations (MLOps) aims to bring the discipline and automation of DevOps to the machine learning lifecycle, streamlining the process of building, training, deploying, and monitoring ML models in production. Kubernetes, often in conjunction with platforms like Kubeflow, has emerged as the de facto infrastructure backbone for MLOps. Kubeflow provides a suite of tools and components built on Kubernetes to manage the entire ML lifecycle, from data preparation and feature engineering to model training using various frameworks (TensorFlow, PyTorch, Scikit-learn), hyperparameter tuning, model serving, and pipeline orchestration. Tools like MLflow, often used with or within Kubeflow, further enhance MLOps by providing capabilities for experiment tracking, model versioning, and model packaging.
The convergence of data engineering pipelines and MLOps pipelines is becoming increasingly apparent. Feature engineering, a critical step in ML, is heavily reliant on data processing. Data validation ensures the quality of data fed into models, and model training itself is a data-intensive computational task. Model serving requires robust, scalable infrastructure to handle inference requests. Kubernetes provides a unified platform to orchestrate both the data pipelines that prepare and feed data into ML models and the MLOps pipelines that manage the model lifecycle itself. This unified approach fosters closer collaboration between data engineers, ML engineers, and data scientists. It enables end-to-end automation, from raw data ingestion through data transformation and feature engineering, to model training, validation, deployment, and continuous monitoring and retraining. The scalability and reproducibility offered by Kubernetes are vital for handling the large datasets and complex computations involved in modern ML, ensuring that experiments are consistent and models can be reliably deployed and scaled in production.
B. The Convergence of Serverless Paradigms with Kubernetes
Serverless computing, characterized by abstracting away server management and offering event-driven, pay-per-use execution models, is a significant trend in cloud computing. Platforms like AWS Lambda, Google Cloud Functions, and Azure Functions are widely used for various tasks, including data processing, without requiring users to provision or manage underlying servers. This paradigm offers benefits such as automatic scaling in response to demand (including scaling to zero when not in use), reduced operational overhead, and potentially lower costs for sporadic or event-driven workloads.
Kubernetes itself is evolving to incorporate serverless concepts. Projects like Knative (which builds on Kubernetes to provide components for deploying, running, and managing modern serverless workloads) and KEDA (Kubernetes Event-Driven Autoscaling, as seen with Airflow ) enable event-driven architectures and fine-grained, scale-to-zero capabilities directly on Kubernetes clusters. This convergence allows organizations to achieve serverless-like benefits—such as deploying functions or applications without direct server provisioning and benefiting from event-based scaling—but on a Kubernetes platform that they may already manage or govern.
This "platform serverless" model, enabled by Kubernetes, can offer a compelling alternative or complement to public cloud FaaS offerings. It provides data teams with a serverless-like developer experience, reducing friction for deploying data processing tasks or microservices, while retaining more control over the underlying environment, networking, security, and tooling. This can be particularly advantageous for organizations that have already made a strategic investment in Kubernetes and wish to standardize their infrastructure, or for those with specific portability, customization, or compliance requirements that might be challenging to meet with public FaaS alone.
C. Enabling Data Mesh Architectures with Kubernetes
Data Mesh is an emerging socio-technical paradigm that challenges traditional centralized data architectures (like monolithic data lakes or data warehouses) by advocating for decentralized data ownership and architecture. Key principles of Data Mesh include:
Domain Ownership: Data is owned and managed by the business domains that understand it best.
Data as a Product: Domains treat their data as a product, responsible for its quality, accessibility, and lifecycle.
Self-Serve Data Infrastructure: Domains are empowered with self-service tools and platforms to build, deploy, and manage their data products.
Federated Computational Governance: A central set of standards and policies ensures interoperability, security, and compliance across the decentralized data products.
Kubernetes is well-positioned to serve as the foundational self-serve infrastructure layer that enables Data Mesh architectures. In a Data Mesh, each domain team needs the autonomy to develop, deploy, and operate its own data products (e.g., specific datasets, analytical APIs, stream processing services). Kubernetes, particularly when managed by a central platform engineering team that provides standardized tooling and abstractions, can offer the necessary capabilities for these domain teams:
Isolation: Kubernetes namespaces can provide logical isolation for different domain teams and their data products.
Resource Management: Resource quotas and limits can ensure fair sharing of cluster resources among domains.
Deployment Automation: CI/CD pipelines integrated with Kubernetes allow domains to independently deploy and update their data products.
Scalability and Resilience: Each data product can leverage Kubernetes's native scaling and self-healing capabilities.
Portability: The ability to deploy Kubernetes consistently across hybrid and multi-cloud environments supports the Data Mesh principle of "easy to deploy anywhere" , allowing domains to choose the best environment for their data products while adhering to global governance standards.
Immutable Infrastructure: The concept of immutable containers and deployments, inherent to Kubernetes, aligns well with the Data Mesh desire for reliable and reproducible data product deployments.
By providing this self-serve infrastructure platform, Kubernetes empowers domain teams to take true ownership of their data products, fostering agility and innovation, while a federated governance model ensures overall coherence and trust in the data ecosystem. This makes Kubernetes a critical enabler for organizations looking to move beyond centralized data bottlenecks and embrace the decentralized, product-oriented approach of Data Mesh.
VI. Conclusion and Strategic Recommendations
Kubernetes has unequivocally established itself as a transformative technology in the realm of data engineering, particularly within cloud environments. Its robust capabilities for container orchestration provide a powerful foundation for building scalable, resilient, and efficient data platforms. Tactically, Kubernetes empowers data engineers to automate the deployment and management of complex data pipelines, run diverse data processing frameworks like Apache Spark, Apache Airflow, and Apache Kafka with unprecedented agility, and efficiently handle a wide spectrum of workloads from large-scale batch processing to real-time data streaming.
Strategically, the adoption of Kubernetes unlocks significant advantages. Its inherent portability facilitates multi-cloud and hybrid-cloud strategies, reducing vendor lock-in and offering greater architectural flexibility. The dynamic resource allocation and autoscaling features contribute to substantial cost optimization in pay-as-you-go cloud models. Furthermore, Kubernetes serves as a crucial enabler for emerging data paradigms such as MLOps, providing a unified platform for the end-to-end machine learning lifecycle, and Data Mesh, by offering the self-serve infrastructure necessary for decentralized data product ownership.
However, the journey to successfully leveraging Kubernetes for data engineering is not without its complexities. Organizations must navigate challenges related to the inherent operational intricacy of the platform, the critical need for robust security in distributed data environments, the complexities of networking, the management of persistent storage for stateful applications, and the development of requisite in-house skills. Addressing these challenges proactively through strategic planning, investment in expertise, and adherence to established best practices is essential for realizing the full potential of Kubernetes.
For organizations aiming to harness Kubernetes for their data engineering initiatives in the cloud, the following strategic recommendations are proposed:
Invest in Skills and Training: The success of Kubernetes adoption hinges on the expertise of the teams managing and utilizing it. Organizations should invest in comprehensive training programs to upskill their data engineers, platform engineers, and operations staff in Kubernetes, Docker, and broader cloud-native principles and practices.
Adopt a Platform Mindset: For larger organizations or those with multiple data teams, consider establishing a dedicated Platform Engineering function. This team can build and maintain an internal data platform on Kubernetes, providing standardized tools, abstractions, and self-service capabilities that shield data scientists and application-focused data engineers from the underlying Kubernetes complexity, while ensuring governance and operational excellence.
Prioritize Security from Day One: Security must be an integral part of the design, deployment, and operation of Kubernetes-based data platforms, not an afterthought. Implement a multi-layered security strategy encompassing RBAC, network policies, secure container image management, secrets management, and continuous monitoring.
Implement Robust Cost Governance: Actively monitor, analyze, and optimize Kubernetes resource consumption to control cloud expenditures. Utilize right-sizing, autoscaling, spot instances where appropriate, and cost management tools to ensure financial efficiency.
Evaluate Managed Services Strategically: Continuously assess the trade-offs between self-managed Kubernetes deployments and managed cloud data services (e.g., EMR, Dataproc, Databricks). The optimal choice will depend on evolving business needs, team capabilities, cost considerations, and the strategic value of specific managed features versus the control offered by self-management.
Embrace Automation and GitOps: Automate as much of the deployment, configuration management, and operational lifecycle of data workloads on Kubernetes as possible. Adopting GitOps principles—using Git as the single source of truth for declarative configurations and automated synchronization—enhances consistency, auditability, and reliability.
Start Small, Iterate, and Scale: For organizations new to Kubernetes for data engineering, it is advisable to begin with well-defined pilot projects to gain hands-on experience, demonstrate value, and refine approaches before embarking on large-scale, mission-critical rollouts.
By strategically navigating its complexities and capitalizing on its strengths, organizations can leverage Kubernetes to build next-generation data platforms that are not only powerful and efficient but also agile and adaptable to the future demands of the data-driven world.