Leveraging Apache Kafka for Data Engineering
Apache Kafka has firmly established itself as a pivotal technology in modern data engineering, particularly within cloud infrastructures. Its dominance as a distributed streaming platform is evident in its widespread adoption for real-time data ingestion, processing, and integration.


Apache Kafka has firmly established itself as a pivotal technology in modern data engineering, particularly within cloud infrastructures. Its dominance as a distributed streaming platform is evident in its widespread adoption for real-time data ingestion, processing, and integration. Kafka effectively functions as the central nervous system for data-intensive applications, enabling a continuous flow of information across diverse systems.
This report delves into both the tactical and strategic dimensions of utilizing Apache Kafka in cloud environments. Key tactical takeaways revolve around understanding the optimal cloud deployment models—ranging from self-managed configurations on virtual machines or Kubernetes to leveraging fully managed services offered by cloud providers and specialized vendors. Critical operational practices, including robust security measures, effective monitoring, and diligent governance, are paramount for successful Kafka deployments. Strategically, Kafka empowers organizations to achieve significant business objectives, such as enhanced agility, massive scalability to handle fluctuating data volumes, and the ability to derive real-time insights that drive immediate action.
The cloud imperative for Kafka is undeniable. Cloud environments offer an ideal setting for Kafka deployments due to their inherent elasticity, the availability of sophisticated managed services that reduce operational burdens, and seamless integration capabilities with a vast ecosystem of other cloud-native tools and services. Kafka's journey began with its recognition as a highly capable message broker, adept at facilitating communication between disparate applications. This foundational strength in messaging provided a robust starting point for its subsequent development. However, the platform's inherent capabilities, such as durable, long-term message storage , the introduction of sophisticated stream processing functionalities via Kafka Streams , and the versatile Kafka Connect framework for external system integration , have collectively propelled it far beyond its initial messaging role. In cloud environments, these advanced features find a particularly fertile ground. The elasticity and scalability offered by cloud infrastructure, coupled with the availability of managed Kafka services , amplify Kafka's potential. Consequently, it is no longer merely a tactical component for data transport but has matured into a strategic platform. Organizations are increasingly leveraging Kafka in the cloud as the cornerstone for comprehensive event-driven architectures and as an enabler for sophisticated analytical workloads, including real-time machine learning applications. This trajectory suggests that investments in Kafka, particularly within cloud ecosystems, should be viewed as fundamental to an organization's overarching data strategy, rather than as isolated solutions for specific data pipelines. The cloud acts as an accelerator in this transformation by diminishing the initial setup complexities and providing an infrastructure that can dynamically adapt to Kafka's demanding workloads.
2. Foundations: Understanding Apache Kafka for Cloud-Native Data Architectures
A thorough understanding of Apache Kafka's fundamental concepts is essential for effectively designing and implementing data engineering solutions, especially in the context of cloud-native architectures. These core components and principles define Kafka's capabilities and its suitability for handling high-volume, real-time data streams.
2.1. Core Kafka Concepts: The Building Blocks of Streaming Data
Kafka's architecture is built upon several key abstractions that work in concert to deliver its powerful streaming capabilities.
Events/Messages/Records: At the heart of Kafka lies the concept of an event, also referred to as a message or record. An event signifies something that has occurred, such as a website click, a financial transaction, or a sensor reading. These events are the fundamental units of data within Kafka. Typically, an event is structured as a key-value pair, accompanied by a timestamp and optional metadata headers. The key is often used for partitioning, while the value contains the actual payload of the event. To ensure efficient transmission and storage, events are serialized using formats like JSON, Apache Avro, or Protocol Buffers. The choice of serialization format has implications for performance, schema evolution capabilities, and interoperability between different systems interacting with Kafka. Understanding the nature and structure of these events is paramount, as they constitute the lifeblood of any Kafka-based system.
Topics: Events in Kafka are organized into logical categories or channels known as topics. A topic can be thought of as a feed name to which events are published. For instance, an e-commerce application might have topics for "orders," "payments," and "inventory_updates". Topics serve as the primary abstraction for producers, which write data to them, and consumers, which read data from them, thereby defining distinct data streams and enabling mechanisms for access control. In essence, a topic is analogous to a table in a relational database, but designed specifically for handling streams of events.
Partitions: To achieve scalability and parallelism, each Kafka topic is divided into one or more partitions. A partition is an ordered, immutable sequence of records to which new events are continually appended. This structure is often described as a commit log. Partitions are the fundamental unit of parallelism in Kafka; they allow a topic's data to be distributed across multiple brokers in a cluster and enable multiple consumers to read from a topic simultaneously. When an event is published without a key, it is distributed across partitions in a round-robin fashion. However, if an event has a key, Kafka guarantees that all events with the same key will be routed to the same partition. This ensures that the order of events for a specific key is maintained, which is crucial for many applications requiring ordered processing. The number of partitions for a topic is a critical configuration parameter that significantly impacts Kafka's performance and scalability.
Brokers: Kafka runs as a cluster of one or more servers, each referred to as a broker. Brokers are the workhorses of a Kafka cluster. Each broker hosts a subset of the partitions for various topics and is responsible for handling incoming requests from producers (to write data) and consumers (to read data), as well as managing data replication between other brokers. A typical production cluster consists of multiple brokers to ensure redundancy, fault tolerance, and load distribution.
Producers: Producers are client applications or processes responsible for publishing (writing) events to Kafka topics. Producers can choose to send events to a specific partition within a topic or allow Kafka to determine the partition, often based on the event's key. The configuration of producers, such as batching strategies and acknowledgment settings, directly affects the throughput and reliability of data ingestion into Kafka.
Consumers and Consumer Groups: Consumers are applications or processes that subscribe to one or more Kafka topics to read and process the events published to them. To enable scalable and fault-tolerant consumption, consumers are often organized into consumer groups. Kafka ensures that each partition within a topic is consumed by exactly one consumer instance within a given consumer group. This mechanism allows the processing load to be distributed among the members of the consumer group. If a consumer in a group fails, Kafka automatically reassigns its partitions to other active consumers in the same group, thus ensuring continuous processing.
Offsets: Each event within a partition is assigned a unique, sequential identification number called an offset. Offsets are used by consumers to track their current position in the event stream for each partition they are consuming. Consumers store their offsets (typically in Kafka itself or an external store), allowing them to resume reading from where they left off in case of a restart or failure. This offset management is fundamental to providing different message delivery semantics, such as "at-least-once," "at-most-once," or "exactly-once" processing.
2.2. The Evolution of Cluster Coordination: ZooKeeper and KRaft
The coordination of brokers within a Kafka cluster, including tasks like metadata management and leader election for partitions, has undergone a significant evolution.
Traditional Role of ZooKeeper: Historically, Apache Kafka relied on Apache ZooKeeper, a separate distributed coordination service, for critical cluster management functions. ZooKeeper was responsible for maintaining metadata about brokers, topics, and partitions, electing a controller broker for the cluster, and tracking the status of brokers. While ZooKeeper provided essential coordination, it also introduced an additional distributed system that needed to be deployed, managed, and monitored alongside Kafka, adding to the operational complexity of running a Kafka cluster.
Introduction to KRaft (Kafka Raft Metadata mode): Recognizing the operational overhead associated with ZooKeeper, recent versions of Kafka have introduced KRaft mode. KRaft (an acronym for Kafka Raft) implements a built-in consensus protocol based on the Raft algorithm directly within Kafka brokers themselves, thereby eliminating the dependency on ZooKeeper. This architectural shift simplifies the overall Kafka deployment by reducing the number of moving parts. KRaft mode allows Kafka to manage its own metadata and cluster coordination internally, which can lead to simpler operations, potentially improved performance, and reduced resource consumption. The move to KRaft is particularly beneficial in cloud environments where minimizing the number of distinct distributed systems to manage can lead to significant operational efficiencies and cost savings. As noted in , KRaft offers "simpler usage and better performance," making Kafka more self-contained and easier to operate at scale. This simplification is not merely an operational tweak; it represents a strategic enhancement making Kafka a more streamlined and cloud-friendly platform. By internalizing consensus management, Kafka becomes more akin to a single, manageable system rather than a composite of two distinct distributed services. This is especially advantageous for managed Kafka services, which can now offer a more efficient and cost-effective solution, and for self-managed deployments (e.g., on Kubernetes), where the complexity of stateful service management is reduced. This evolution can contribute to faster deployment cycles, lower total cost of ownership (TCO), and enhanced stability.
2.3. Why Kafka for Data Engineering: Key Benefits in the Cloud Context
Apache Kafka offers a compelling set of benefits that make it a cornerstone technology for data engineering, especially when deployed in cloud environments.
Real-time Processing: Kafka is fundamentally designed for ingesting and processing streaming data with very low latency. This capability is crucial for use cases that demand immediate insights and actions, such as fraud detection, real-time analytics, and dynamic personalization, all of which are increasingly common requirements in modern data engineering.
Scalability: Kafka's architecture, built around distributed brokers and topic partitioning, enables massive horizontal scalability. It can handle throughputs ranging from thousands to billions of events per minute. When deployed in the cloud, this inherent scalability is further amplified by the cloud's elasticity, allowing clusters to be dynamically resized to meet fluctuating data volumes and processing demands.
Durability and Fault Tolerance: Kafka provides strong durability guarantees by persistently storing messages on disk within the brokers. Furthermore, data is replicated across multiple brokers. If a broker fails, another broker with a replica of the data can take over, ensuring that no data is lost and the system remains available. This reliability is critical for mission-critical data pipelines where data integrity and continuous operation are paramount.
Decoupling of Systems: Kafka acts as an intermediary buffer between data producers and data consumers. This decoupling means that producers can publish data without knowing who the consumers are or how they process the data, and consumers can process data at their own pace without impacting the producers. This architectural pattern fosters the development of microservice architectures and makes systems more resilient, as the failure or slowdown of one component does not immediately cascade to others.
Data Replayability: Kafka retains messages for a configurable period (or until a certain size limit is reached), regardless of whether they have been consumed. This allows consumers to re-read messages from a specific point in time (offset). This replayability is a powerful feature for various scenarios, including debugging applications, recovering from consumer failures, backfilling data for new applications, or running A/B tests on historical data streams without impacting live production flows.
Kafka's core architectural tenets—distributed systems, horizontal scalability, fault tolerance via replication, and service decoupling —remarkably align with the principles of cloud-native design, even predating the widespread adoption of the "cloud-native" term. Cloud-native architectures similarly emphasize scalability, resilience, and often leverage microservice patterns. This inherent synergy means that Kafka's foundational design choices, such as its partitioned log model and distributed broker coordination, naturally complement the operational and architectural paradigms of the cloud. Consequently, deploying Kafka in a cloud environment is not merely about porting an existing application; it's about leveraging a technology whose fundamental characteristics are amplified by the cloud's strengths. For example, Kafka’s partitioning strategy maps effectively to distributed compute resources available in the cloud, and its data replication mechanisms align perfectly with multi-availability zone (multi-AZ) deployment patterns, which are standard for achieving high availability in cloud settings. This intrinsic compatibility reduces friction and allows organizations to more fully exploit cloud capabilities for their real-time data streaming requirements.
3. Tactical Implementation: Deploying and Operating Kafka in Cloud Environments
Successfully leveraging Apache Kafka in the cloud requires careful consideration of deployment models, operational best practices, and the effective application of its features to common data engineering use cases. Tactical decisions made during implementation directly impact performance, scalability, manageability, and cost.
3.1. Deployment Models
Organizations have several options for deploying Kafka in the cloud, each with its own set of trade-offs regarding control, operational effort, and cost.
3.1.1. Self-Managed Kafka on Cloud Infrastructure
Opting for a self-managed Kafka deployment gives organizations complete control over the configuration and underlying infrastructure but also entails significant operational responsibility.
Running on Virtual Machines (e.g., EC2, Compute Engine, Azure VMs): This is the traditional approach to self-managing Kafka. It involves provisioning virtual machines in the cloud and manually installing, configuring, and maintaining Kafka brokers, along with ZooKeeper (for older versions) or KRaft-mode configurations. While offering maximum flexibility, this model demands substantial expertise in Kafka administration, networking, storage management, security hardening, and ongoing operations such as patching, upgrades, monitoring, and disaster recovery.
Running on Kubernetes (e.g., Amazon EKS, Google GKE, Azure AKS): Deploying Kafka on Kubernetes has become an increasingly popular method for self-management, leveraging containerization and orchestration capabilities. Kubernetes Operators, such as Strimzi, significantly simplify the deployment, management, and operational tasks associated with running Kafka on Kubernetes.
Advantages: Kubernetes provides inherent benefits like automated scaling, self-healing of failed components, and streamlined rolling updates for Kafka brokers. Strimzi, for example, offers Kubernetes-native management of Kafka resources, allowing administrators to define and manage brokers, topics, users, and other Kafka components using Kubernetes Custom Resource Definitions (CRDs).
Setup and Configuration: This typically involves deploying the chosen Kafka Operator (like Strimzi) into the Kubernetes cluster. Once the operator is running, Kafka clusters and their components are defined and configured using YAML manifests that specify the desired state (e.g., number of brokers, replication factors, resource allocations). A detailed walkthrough for deploying Kafka on Amazon EKS using the Strimzi operator is available, covering infrastructure setup, verification, topic creation, and scaling.
Operational Best Practices: Effective operation requires robust monitoring using tools like Prometheus and Grafana, which can be integrated to collect and visualize Kafka and Kubernetes metrics. A solid understanding of Kubernetes networking, persistent storage options (e.g., EBS CSI driver for EKS), and resource management (CPU, memory requests, and limits) is crucial. Configuring liveness and readiness probes for Kafka pods helps Kubernetes manage broker health effectively. Strategies for scaling Kafka brokers and rebalancing partitions on Kubernetes are also important operational considerations.
3.1.2. Managed Kafka Services in the Cloud
Cloud providers and specialized companies offer Apache Kafka as a managed service, abstracting much of the underlying infrastructure management and operational complexity. This approach significantly reduces the operational overhead associated with running Kafka, allowing teams to focus more on developing applications that utilize Kafka rather than managing the Kafka platform itself.
Key Offerings:
Amazon MSK (Managed Streaming for Apache Kafka): Provided by AWS, Amazon MSK offers deep integration with other AWS services. It is available in two main deployment options: provisioned (where users manage broker instances and storage) and serverless (which automatically provisions and scales compute and storage resources). MSK clusters are deployed within a user's Virtual Private Cloud (VPC), enhancing network security. Recent innovations like MSK Express brokers provide significantly faster scaling capabilities (up to 20 times faster than standard brokers) and higher throughput per broker.
Azure Event Hubs for Kafka / HDInsight Kafka: Microsoft Azure provides Kafka capabilities through Azure Event Hubs, which offers a Kafka-compatible endpoint, allowing existing Kafka client applications to connect to Event Hubs without significant code changes. Azure HDInsight also offers managed Kafka clusters, though some sources note limitations such as only supporting upward scaling of broker nodes.
Google Cloud: While Google Cloud's Pub/Sub offers a robust messaging service, for Kafka-native experiences, it primarily relies on partnerships, most notably with Confluent Cloud, which is available on the Google Cloud Marketplace. Google Cloud Dataflow also provides native templates for integrating Kafka with services like BigQuery.
Confluent Cloud: Developed by the original creators of Apache Kafka, Confluent Cloud is a fully managed, cloud-native Kafka service available on major cloud platforms (AWS, Azure, GCP). It provides a comprehensive Kafka ecosystem, including features like a managed Schema Registry, ksqlDB for stream processing, and an extensive library of pre-built connectors. Confluent Cloud is often highlighted for its ability to reduce operational burden and provide proactive expert support.
Comparison Factors: When selecting a managed Kafka service, organizations should evaluate several factors:
Ease of Setup and Management: How quickly can a cluster be provisioned and configured? What level of operational tasks remain the user's responsibility?
Scalability and Performance: Does the service offer auto-scaling? What are the throughput and latency characteristics? Are there different performance tiers (e.g., MSK Express brokers )?
Ecosystem Integration: How well does it integrate with other cloud services and the broader Kafka ecosystem (e.g., Kafka Connect, Kafka Streams, Schema Registry, ksqlDB, Flink)?
Security Features: What authentication, authorization, encryption, and network isolation options are provided (e.g., VPC deployment, IAM integration, private networking)?
Monitoring and Logging: What tools and integrations are available for monitoring cluster health and performance?
Support and SLAs: What level of support is offered, and what are the service level agreements for uptime and performance?
Pricing Models: Is pricing based on provisioned resources, throughput, storage, or a combination? How do data transfer costs factor in?
The choice of deployment model—self-managed versus managed—carries profound tactical implications that extend beyond mere infrastructure preference. It directly influences daily operations, the skill sets required within the engineering team, and the overall speed of development and iteration. Self-managed Kafka, whether on virtual machines or Kubernetes, grants maximum control and customization but simultaneously demands a deep reservoir of expertise in Kafka itself, ZooKeeper/KRaft intricacies, network configuration, and ongoing infrastructure management. This path necessitates a dedicated operations team or highly skilled DevOps engineers proficient in these complex distributed systems. Conversely, managed Kafka services abstract away a significant portion of this operational complexity, allowing teams to redirect their focus towards application logic and business value rather than platform maintenance. This trade-off between control and operational ease is a central theme. The considerable operational burden associated with self-management—encompassing provisioning, patching, scaling, ensuring high availability, and managing disaster recovery—can introduce delays and divert valuable engineering resources from core data engineering objectives. Managed services mitigate this burden, often leading to faster time-to-market for Kafka-dependent applications due to streamlined infrastructure setup. Day-to-day operational concerns like monitoring, alerting, software updates, and security patching are largely handled by the service provider in a managed model, whereas these are explicit responsibilities for the in-house team in a self-managed scenario. Furthermore, managed services frequently offer a curated and supported ecosystem of connectors (as seen with Confluent Cloud ), which can substantially accelerate data integration tasks compared to the often more laborious process of identifying, configuring, deploying, and maintaining open-source connectors in a self-hosted environment.
The following table provides a comparison of major managed Kafka services:
Table 1: Comparison of Major Managed Kafka Services in the Cloud
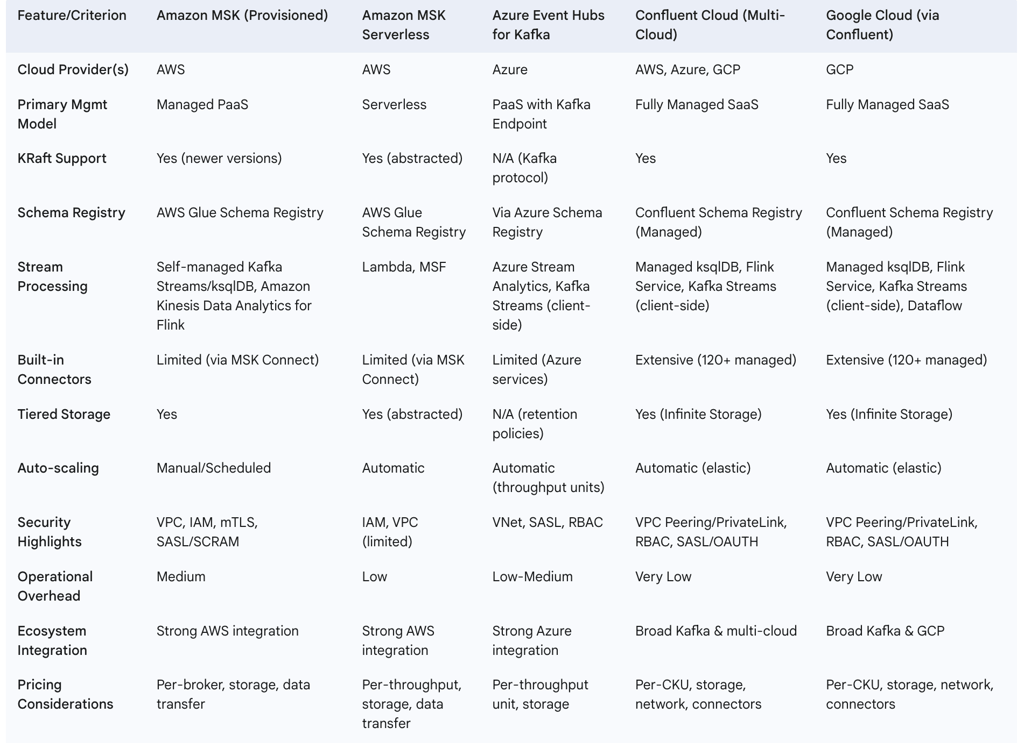
3.2. Core Tactical Use Cases
Apache Kafka serves as a versatile platform for a wide array of tactical data engineering use cases in cloud environments.
3.2.1. Building Real-Time Data Pipelines
One of the most common applications of Kafka is in constructing real-time data pipelines. These pipelines ingest continuous streams of data from diverse sources such as Internet of Things (IoT) devices, application logs, change data capture (CDC) from databases, and clickstreams. Kafka acts as the central, high-throughput buffer that reliably collects this data. From Kafka, data can then be transformed in-stream or routed to various destinations, including cloud-based data lakes (e.g., Amazon S3, Google Cloud Storage, Azure Data Lake Storage), data warehouses (e.g., Snowflake, BigQuery, Redshift), or real-time analytics and visualization applications. The cloud context enhances this by providing scalable storage and compute resources for both the sources and sinks of these pipelines.
3.2.2. Decoupling Microservices and Event-Driven Architectures (EDA)
Kafka is instrumental in building decoupled microservice architectures and enabling event-driven systems. In such architectures, Kafka serves as an asynchronous communication backbone. Instead of services making direct, synchronous calls to each other, they produce events to Kafka topics and consume events from topics relevant to their function. This decoupling offers significant benefits:
Improved Resilience: If a consuming service is temporarily unavailable, messages remain in Kafka and can be processed once the service recovers, preventing cascading failures.
Enhanced Scalability: Producers and consumers can be scaled independently based on their specific loads.
Independent Evolution: Services can be developed, deployed, and updated independently as long as they adhere to the event contracts (schemas) defined for the Kafka topics. The use of Kafka in EDA promotes responsiveness and flexibility, allowing systems to react to business occurrences in real time.
3.2.3. Stream Processing with Kafka Streams
Kafka Streams is a powerful client library that allows developers to build real-time stream processing applications and microservices directly within the Kafka ecosystem. With Kafka Streams, the input data is read from Kafka topics, processed (e.g., filtered, transformed, aggregated, joined with other streams or tables), and the output is written back to Kafka topics. It supports stateful operations, windowing for time-based aggregations, and provides exactly-once processing semantics. Kafka Streams applications are typically deployed as standard Java or Scala applications, which can be containerized and run on Kubernetes or other cloud compute platforms. When using Kafka Streams with managed services like Azure Event Hubs, specific client configurations, such as messageTimestampType, may need adjustment to ensure compatibility and correct behavior.
3.2.4. Integrating with Other Processing Engines
Kafka frequently serves as a high-throughput, reliable data ingestion and distribution layer for more specialized stream or batch processing frameworks.
Apache Flink: Kafka and Apache Flink are often used together in high-performance data processing pipelines. Kafka typically handles the data ingestion and buffering layer, capturing events from various sources. Flink then consumes these streams from Kafka to perform complex event processing, stateful computations, and advanced analytics. The results of Flink's processing can then be written back to Kafka for downstream consumption or to other systems.
Apache Spark Streaming / Structured Streaming: Kafka is a popular source and sink for Apache Spark's streaming capabilities. Spark Streaming (using DStreams) or the newer Structured Streaming (using DataFrames/Datasets) can consume data from Kafka topics, perform micro-batch or continuous processing for complex analytics and machine learning tasks, and then write results back to Kafka or other storage systems.
3.2.5. Utilizing Kafka Connect for Data Integration
Kafka Connect is a framework included with Apache Kafka designed to reliably stream data between Kafka and other external systems, such as databases, key-value stores, search indexes, and file systems. It uses "connectors" to achieve this:
Source Connectors: Ingest data from external systems into Kafka topics.
Sink Connectors: Export data from Kafka topics to external systems.
This framework simplifies the development and management of data integration pipelines.
Cloud Storage (S3, GCS, Azure Blob): A common use case is archiving data from Kafka to cost-effective cloud object storage. The Kafka Connect S3 sink connector, for example, allows data from Kafka topics to be written to Amazon S3 buckets, often for long-term storage, data lake population, or batch analytics. Aiven's S3 connector, for instance, requires specific AWS permissions (like s3:PutObject) and supports various output formats and file naming templates.
Data Warehouses (Snowflake, BigQuery):
Snowflake: Dedicated Snowflake Sink Connectors are available to move data efficiently from Kafka topics into Snowflake tables for analytics. Configuration typically involves providing Snowflake connection details (URL, user, private key), database/schema names, and the list of Kafka topics to sink.
BigQuery: Google Cloud Dataflow offers pre-built templates, such as the "Kafka to BigQuery" template, which create streaming pipelines to ingest data from Kafka (including managed Kafka services on GCP) and write it to BigQuery tables. This often involves setting up the Kafka cluster, topics, BigQuery datasets/tables, and then running the Dataflow job with appropriate parameters.
Managed Connectors: Many managed Kafka services, particularly Confluent Cloud, offer a wide range of pre-built and fully managed connectors. This simplifies the deployment, configuration, and maintenance of connectors, accelerating data integration efforts.
Kafka Connect is a tactical linchpin for achieving seamless data integration within cloud ecosystems. However, its effective deployment and utility are heavily influenced by the chosen Kafka operational model (self-managed vs. managed) and the availability and quality of specific connectors. When self-managing Kafka Connect, teams are responsible for deploying the Connect framework itself, managing its worker nodes, and installing and configuring individual connector plugins. This involves careful resource allocation, ongoing monitoring, and ensuring compatibility between connector versions, Kafka versions, and target systems. In contrast, many managed Kafka providers, especially comprehensive platforms like Confluent Cloud , offer Kafka Connect as a managed service. This significantly simplifies the deployment and lifecycle management of connectors, providing a substantial tactical advantage by reducing operational burden. The availability of robust, well-maintained, and officially supported connectors for critical cloud services (e.g., a mature S3 sink connector or a reliable Snowflake connector ) is paramount. Teams might otherwise need to vet open-source alternatives or invest in developing custom connectors. Configuration of these connectors, particularly for aspects like data serialization formats (Avro, JSON), schema evolution management (often involving a Schema Registry), and ensuring desired delivery semantics (e.g., exactly-once), requires meticulous attention to detail and thorough understanding of both Kafka and the target system.
3.2.6. Serverless Kafka Consumption (e.g., AWS Lambda Triggers)
Serverless computing paradigms offer a cost-effective and scalable way to process Kafka messages. Services like AWS Lambda can be configured to consume events from Kafka topics, enabling event-driven processing without managing underlying server infrastructure.
AWS Lambda: Lambda functions can be triggered by messages in Amazon MSK topics or self-managed Kafka clusters through an event source mapping (ESM). The ESM polls Kafka topics for new messages, batches them, and invokes the target Lambda function with the message payload. This approach is well-suited for event-driven workloads with variable or bursty traffic patterns. Configuration involves specifying the Kafka cluster ARN, topic name, batch size, and authentication details (e.g., storing Kafka credentials in AWS Secrets Manager). AWS offers multiple ways to integrate Lambda with Kafka, including Kafka Connect sink connectors for Lambda, Amazon EventBridge Pipes (for light ETL to supported targets), and the direct Lambda ESM, with ESM being ideal for rich processing within Lambda.
Redpanda Serverless: Emerging platforms like Redpanda offer Kafka-compatible streaming data services with a serverless model. This allows developers to use Kafka APIs and client libraries while the platform handles infrastructure provisioning, scaling, and maintenance on a pay-as-you-go basis.
The following table outlines key Kafka configuration parameters and their optimization considerations in cloud environments, particularly relevant for self-managed deployments:
Table 2: Key Kafka Configuration Parameters for Cloud Optimization
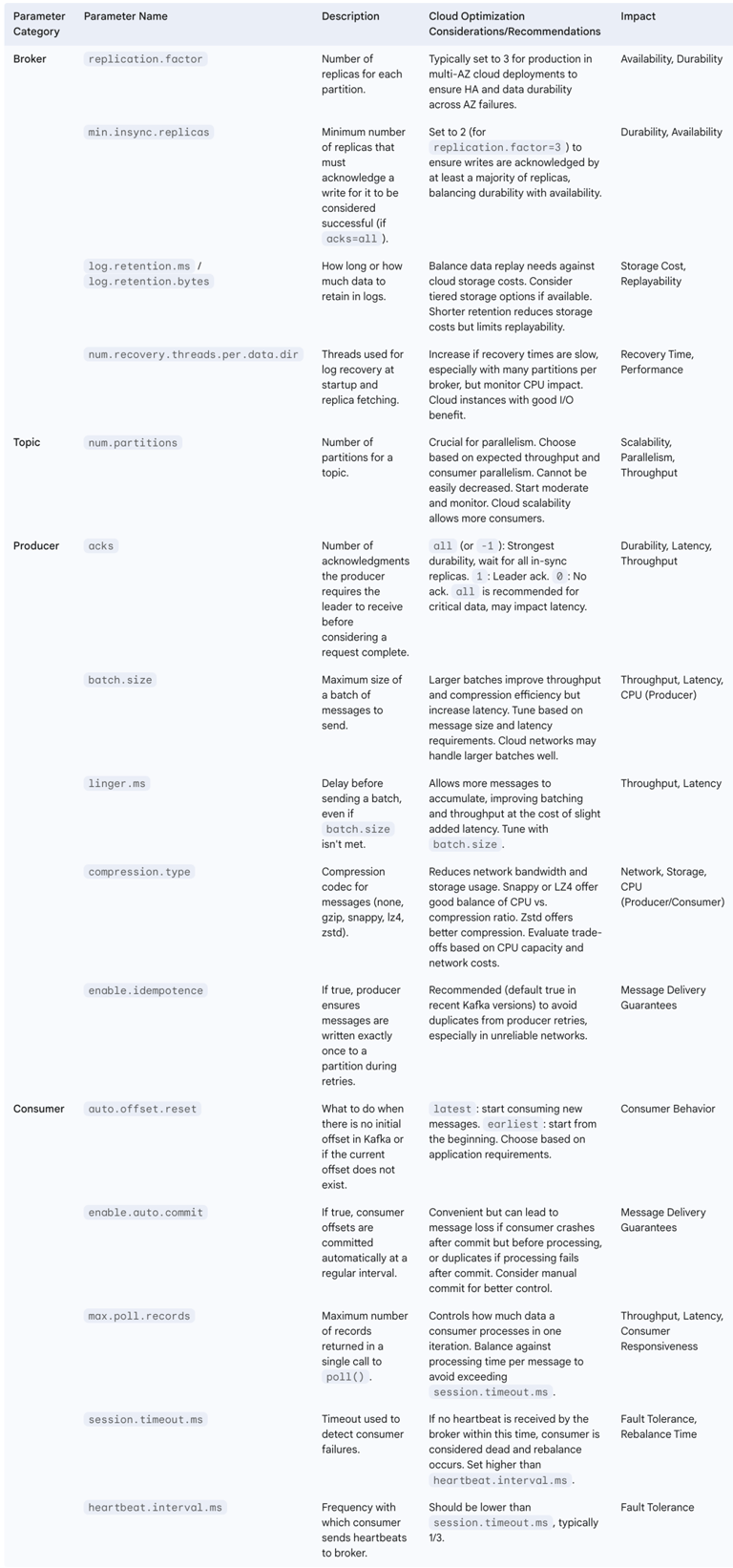
4. Strategic Imperatives: Architecting Long-Term Kafka Solutions in the Cloud
Beyond tactical implementation, leveraging Apache Kafka effectively in the cloud for sustained advantage requires strategic planning around deployment models, scalability, resilience, governance, security, cost management, and the adoption of advanced architectural patterns. These strategic imperatives ensure that Kafka not only meets current data engineering needs but also supports future growth and evolving business requirements.
4.1. Choosing the Right Cloud Deployment Strategy
The foundational strategic decision for Kafka in the cloud is selecting the appropriate deployment model. This choice has long-term implications for operational efficiency, cost, control, and agility.
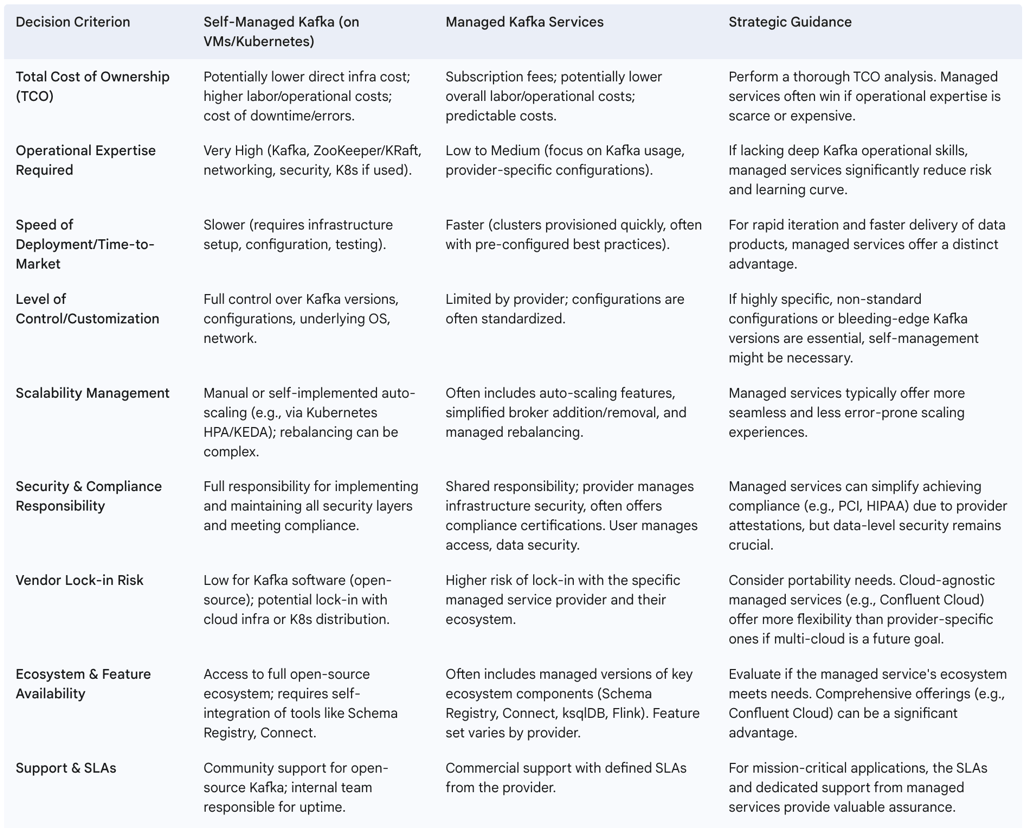
4.1.1. Self-Hosted vs. Managed Services: A Decision Framework
The decision between self-hosting Kafka (on VMs or Kubernetes) and utilizing a managed Kafka service is a critical one, with significant trade-offs.
Factors to Consider:
Operational Capacity and Expertise: Self-hosting demands significant in-house expertise in Kafka, ZooKeeper/KRaft, networking, security, and infrastructure management. Managed services offload most of this burden.
Total Cost of Ownership (TCO): This includes not only direct infrastructure or subscription costs but also labor costs for management, monitoring, and maintenance. Self-hosting may appear cheaper initially but can have higher hidden operational costs.
Level of Control and Customization: Self-hosting provides maximum control over Kafka configuration, versioning, and the underlying environment. Managed services offer less granular control but provide a standardized, optimized platform.
Time-to-Market: Managed services generally allow for much faster deployment and provisioning of Kafka clusters, accelerating the delivery of data-dependent applications.
Security and Compliance: Managed services often come with built-in security features and compliance certifications, which can simplify meeting regulatory requirements. In self-hosted scenarios, the organization bears full responsibility.
Vendor Lock-in Concerns: Managed services, especially those proprietary or deeply integrated with a specific cloud provider, can lead to vendor lock-in. Self-hosting open-source Kafka offers more portability.
Ecosystem Requirements: The need for specific Kafka ecosystem components (e.g., Schema Registry, ksqlDB, specific connectors) and their availability/manageability within a chosen model is crucial. Confluent Cloud, for example, offers a rich, managed ecosystem.
Self-Managed Pros & Cons:
Pros: Complete control over all aspects of the deployment, potential for deep customization, no direct vendor lock-in for the Kafka software itself, and potentially lower direct infrastructure costs if substantial operational expertise is already available in-house.
Cons: Extremely high operational overhead, significant complexity in setup and ongoing management, slower deployment cycles, and the full burden of ensuring high availability, disaster recovery, security, and patching rests with the organization.
Managed Services Pros & Cons:
Pros: Greatly reduced operational burden, allowing teams to focus on application development; faster deployment and time-to-market; often includes built-in features for high availability, disaster recovery, and security; access to expert support and SLAs.
Cons: Potential for vendor lock-in with the service provider; less control over the underlying infrastructure and specific Kafka configurations; subscription costs can escalate with increasing scale or feature usage; some managed services might lag behind the latest open-source Kafka features or have limitations.
The choice between self-managed and managed Kafka is not merely an operational decision; it is a profound strategic one that significantly impacts an organization's agility, capacity for innovation, and long-term total cost of ownership. While self-managed Kafka offers the allure of ultimate control and customization, it demands a substantial and continuous investment in specialized engineering skills and considerable operational effort. This investment can divert resources from core business objectives. Managed services, by abstracting away much of this underlying complexity, free up valuable engineering talent to focus on building data-driven applications and deriving business value, rather than managing infrastructure. This shift aligns with a broader trend where businesses increasingly seek to offload non-differentiating operational tasks to cloud providers or specialized vendors, enabling them to concentrate on their core competencies. The high operational cost and inherent complexity of self-managing a distributed system like Kafka can act as a strategic impediment, slowing down innovation cycles. Managed services can strategically accelerate time-to-market for new data products and services by providing a readily available, scalable, and reliable Kafka platform. This allows data teams to experiment, iterate, and deliver value more rapidly. From a resource allocation perspective, opting for a managed service can strategically redeploy engineering resources from infrastructure upkeep to higher-value activities such as data analysis, machine learning model development, and innovative application design. While managed services incur direct subscription costs, a comprehensive TCO analysis must also account for the indirect costs of self-management, including salaries for specialized engineers, the opportunity cost of their diverted attention, and the potential financial impact of downtime caused by operational errors. For many organizations, a managed service strategically offers a lower TCO and reduced operational risk, often backed by SLAs and expert support.
The following table provides a decision framework for choosing between self-managed and managed Kafka in the cloud:
Table 3: Decision Framework: Self-Managed vs. Managed Kafka in the Cloud
4.1.2. Multi-Cloud and Hybrid Cloud Kafka Strategies
As organizations increasingly adopt multi-cloud or hybrid cloud architectures, extending Kafka deployments across these diverse environments becomes a strategic consideration.
Motivations: Common drivers include avoiding vendor lock-in with a single cloud provider, enhancing disaster recovery capabilities by having presence in different clouds, meeting data sovereignty or residency requirements, placing Kafka closer to specific cloud-native services or user bases for lower latency, and enabling workload portability.
Architectural Approaches:
Data Replication between Clusters: The most common approach involves running separate Kafka clusters in different cloud environments (or on-premises) and replicating data between them. Tools like Apache Kafka's MirrorMaker 2 are designed for this purpose, facilitating cross-cluster replication. Vendor-specific replication solutions, often offering more advanced features like exactly-once semantics and easier management, are also available from providers like Confluent. These setups can be configured in active-passive mode (one primary cluster, one standby for DR) or active-active mode (multiple clusters serving live traffic, often for different applications or regions, with bidirectional or hub-spoke replication topologies). Kafka Connect can also be employed to sink data from a Kafka cluster in one cloud and source it into another, or into other systems across clouds.
Stretched Clusters (Caution Advised): Attempting to stretch a single Kafka cluster across different cloud providers is generally not recommended due to the high inter-cloud network latencies and increased operational complexity, which can severely impact Kafka's performance and stability. However, stretching clusters across multiple availability zones or even regions within the same cloud provider is a more common pattern for achieving high availability and regional DR.
Kafka Mesh / Event Mesh: An emerging concept is the "Kafka Mesh" or, more broadly, an "Event Mesh." This involves using a network of interconnected event brokers to dynamically route events between various Kafka clusters, which might be of different "flavors" (e.g., open-source Kafka, Confluent Platform, managed services) and deployed across on-premises data centers, and multiple public/private clouds. In this model, individual Kafka instances act as sources and sinks within the larger mesh, which handles the complexities of inter-cluster communication, filtering, and routing. Technologies like Solace PubSub+ are positioned to enable such event mesh architectures, bridging disparate Kafka deployments.
Challenges: Multi-cloud and hybrid Kafka deployments introduce significant challenges:
Increased Complexity: Managing infrastructure, security configurations, networking, and data replication across multiple, often disparate, cloud environments is considerably more complex than a single-cloud setup. Each cloud provider has its own APIs, CLIs, and management consoles, steepening the learning curve and increasing operational burden.
Higher Costs: Data egress (transfer out) and ingress (transfer in) costs between different cloud providers can be substantial and must be carefully factored into the TCO. The operational overhead of managing increased complexity and potentially licensing proprietary replication tools also adds to the cost.
Data Consistency: Ensuring strong data consistency guarantees (like exactly-once semantics) and managing replication lag across clusters in different clouds, especially with variable and potentially high network latencies, is a difficult technical challenge.
Security Management: Implementing and maintaining consistent security policies, identity and access management (IAM), encryption mechanisms, and network security across multiple cloud providers requires meticulous planning, robust tooling, and often a Zero Trust security approach, which itself adds implementation complexity.
4.2. Ensuring Scalability, Resilience, and Performance
Strategic planning for Kafka in the cloud must prioritize robust mechanisms for scalability, high availability (HA), disaster recovery (DR), and sustained performance.
4.2.1. Cloud-Native Scaling Strategies for Kafka Clusters
Cloud environments offer unique advantages for scaling Kafka clusters dynamically.
Horizontal Scaling: The primary method for scaling Kafka is by adding more broker nodes to the cluster. Once new brokers are added, partitions from existing topics need to be reassigned (rebalanced) across the expanded set of brokers to distribute the load. Cloud platforms simplify the provisioning of new broker instances. If Kafka is deployed on Kubernetes, Horizontal Pod Autoscalers (HPAs) or Kubernetes Event-driven Autoscaling (KEDA) can be used to automate the scaling of broker pods based on metrics like CPU utilization or queue length.
Vertical Scaling: This involves increasing the resources (CPU, memory, disk I/O, network bandwidth) of the existing broker instances. Cloud platforms make it relatively easy to change instance types to more powerful ones. This can be a quicker way to address performance bottlenecks before resorting to horizontal scaling, but it has limits.
Partition Scaling: The number of partitions for a topic is a key determinant of its parallelism and throughput capacity. Increasing the number of partitions allows for more consumers to process data in parallel from that topic. However, this decision requires careful planning, as the number of partitions for a topic cannot be easily decreased after creation. It's generally better to over-partition slightly than to under-partition, but excessive partitioning can also lead to increased overhead.
Managed Service Scaling: Most managed Kafka services provide features for scaling clusters, often with automated or simplified procedures. For example, Amazon MSK Express brokers are designed for rapid scaling, capable of expanding cluster capacity significantly faster than traditional Kafka broker scaling, often within minutes. Confluent Cloud offers elastic scaling based on throughput.
4.2.2. High Availability (HA) and Disaster Recovery (DR) Patterns in the Cloud
Ensuring continuous operation and data protection is critical for Kafka deployments.
Multi-AZ Deployments: The standard practice for achieving high availability within a single cloud region is to deploy Kafka brokers across multiple Availability Zones (AZs). AZs are physically separate data centers within a region with independent power, cooling, and networking. By setting a topic's replication factor to at least 3 (and min.insync.replicas to 2), and distributing broker replicas across three AZs, the cluster can tolerate the failure of an entire AZ without data loss and with minimal service interruption.
Cross-Region Replication (CRR) for DR: For disaster recovery against entire regional outages, data needs to be replicated to a Kafka cluster in a secondary, geographically distinct cloud region. This is typically achieved using tools like Apache Kafka's MirrorMaker 2 or proprietary replication solutions offered by managed service providers. This secondary cluster can be a hot standby (actively processing some traffic or ready for immediate failover) or a warm standby (requiring some ramp-up time).
Backup and Restore Strategies:
Filesystem Snapshots: Periodically taking snapshots of the persistent disks attached to Kafka brokers is one method of backup. In case of catastrophic failure, these snapshots can be used to restore broker data. Cloud providers offer snapshot capabilities for their block storage services (e.g., AWS EBS snapshots).
Kafka Connect to Durable Storage: Using Kafka Connect with sink connectors (e.g., S3 sink connector) to continuously stream topic data to durable, versioned object storage (like Amazon S3, Google Cloud Storage, or Azure Blob Storage) serves as another form of backup and archival. This data can potentially be rehydrated back into Kafka if needed, though the process might be complex depending on the format and volume.
Recovery Point Objective (RPO) and Recovery Time Objective (RTO): These are critical metrics that must be defined by the business to guide the DR strategy. RPO dictates the maximum acceptable amount of data loss (measured in time), while RTO specifies the maximum acceptable downtime. Asynchronous cross-region replication will inherently have an RPO greater than zero, meaning some recent data might be lost upon failover. Achieving RPO of zero typically requires synchronous replication, which is very challenging and often impractical across regions due to latency.
Tiered Storage: Some Kafka solutions and managed services (e.g., Confluent Cloud's Infinite Storage, Amazon MSK with tiered storage options) support offloading older, less frequently accessed data segments from expensive broker-local storage to more cost-effective object storage in the cloud. While primarily a cost optimization feature, tiered storage can also play a role in DR by ensuring long-term data retention in durable cloud storage, potentially simplifying recovery scenarios for historical data.
4.3. Governance, Security, and Cost Management
Strategic deployment of Kafka in the cloud necessitates robust frameworks for governance, comprehensive security measures, and diligent cost management.
4.3.1. Securing Kafka in Cloud Environments
Protecting data in Kafka, especially in shared cloud environments, is paramount. A multi-layered security approach is essential.
Authentication: Verifying the identity of clients (producers, consumers, applications) and brokers is the first line of defense. Kafka supports various authentication mechanisms:
SASL (Simple Authentication and Security Layer): A framework that supports pluggable authentication methods like SCRAM (Salted Challenge Response Authentication Mechanism), Kerberos, and OAuth/OIDC. SASL/SCRAM is common for username/password-based authentication. SASL/GSSAPI is used for Kerberos.
mTLS (mutual Transport Layer Security): Uses X.509 certificates for both client and server authentication, ensuring that both parties verify each other's identity.
Cloud IAM Integration: Some managed Kafka services, like Amazon MSK, allow integration with the cloud provider's Identity and Access Management (IAM) service for authenticating clients.
Authorization: Once authenticated, authorization controls what actions a principal (user, service account) can perform on Kafka resources (topics, consumer groups, cluster operations).
Access Control Lists (ACLs): Kafka uses ACLs to define permissions (e.g., Read, Write, Create, Describe) for specific principals on specific resources. The principle of least privilege should be strictly followed, granting only necessary permissions.
Encryption: Protecting data confidentiality both in transit and at rest.
Encryption in Transit: SSL/TLS should be enabled for all communication between clients and brokers, as well as for inter-broker communication. This prevents eavesdropping and tampering with data on the network. Security protocols like SASL_SSL (authentication + encryption) are recommended for production.
Encryption at Rest: Data stored on broker disks should be encrypted. This is typically achieved using disk-level encryption services provided by cloud platforms (e.g., AWS KMS for EBS encryption, Azure Key Vault for Azure Disk Encryption) or by using filesystem-level encryption. Kafka itself does not natively encrypt data on disk but relies on these underlying storage encryption mechanisms.
Network Security: Isolating Kafka clusters within secure network environments is crucial.
Virtual Private Clouds (VPCs)/Virtual Networks (VNets): Deploy Kafka brokers within private subnets in a VPC/VNet.
Security Groups/Network Security Groups (NSGs)/Firewall Rules: Use these to strictly control inbound and outbound traffic to Kafka brokers, allowing access only from authorized IP ranges or security groups on necessary ports.
Private Connectivity: For secure access from other VPCs/VNets or on-premises environments, use services like AWS PrivateLink, Azure Private Link, or Google Private Service Connect, or establish VPN/Direct Connect links. Many managed services like Amazon MSK are deployed within your VPC for enhanced security , and Confluent Cloud offers VPC peering or PrivateLink options.
Secure Credential Storage: Sensitive information like passwords, API keys, and private keys for mTLS or SASL should be stored securely using dedicated secrets management services such as AWS Secrets Manager, Azure Key Vault, or HashiCorp Vault, rather than hardcoding them in application configurations.
4.3.2. Data Governance for Kafka Topics and Schemas in the Cloud
Effective data governance is essential for maintaining data quality, ensuring compliance, and enabling data discovery within Kafka.
Schema Management: Implementing a Schema Registry, such as Confluent Schema Registry, is a best practice for managing and enforcing schemas (e.g., Avro, Protobuf, JSON Schema) for data published to Kafka topics. A Schema Registry helps ensure data quality by validating that producers adhere to defined schemas. It also facilitates schema evolution, allowing schemas to change over time in a compatible manner without breaking downstream consumers. This is critical for maintaining data integrity and interoperability in evolving data pipelines.
Topic Naming Conventions and Metadata Management: Establishing and enforcing clear, consistent naming conventions for Kafka topics is vital for organization, discoverability, and access control. Including tenant identifiers in topic names can be useful for multi-tenant environments. Maintaining metadata (e.g., descriptions, ownership, data sensitivity) for topics, often in conjunction with a data catalog, improves understanding and usability of data streams.
Data Lineage and Cataloging: As data flows through Kafka and various processing stages, understanding its origin, transformations, and destinations (data lineage) becomes important for impact analysis, debugging, and compliance. Tools that provide data lineage capabilities, sometimes offered as part of advanced Kafka platforms (like Confluent Stream Lineage ) or integrated with broader enterprise data catalogs, are valuable.
Auditing: Enabling and regularly reviewing audit logs for Kafka clusters helps track access patterns, administrative actions, configuration changes, and authorization successes/failures. This is crucial for security monitoring, compliance reporting, and troubleshooting.
4.3.3. Optimizing Costs for Kafka Deployments in the Cloud
While the cloud offers flexibility and scalability, managing the costs of Kafka deployments requires careful planning and ongoing optimization.
Right-Sizing Resources: Continuously monitor the resource utilization (CPU, memory, disk I/O, network) of Kafka brokers and any associated ZooKeeper/KRaft nodes. Choose appropriate cloud instance types and sizes that match the workload requirements without significant overprovisioning. Tools like the Amazon MSK sizing tool can provide initial estimates, but load testing is essential for validation.
Storage Optimization:
Implement appropriate log retention policies (log.retention.ms or log.retention.bytes) for Kafka topics. Retain data only as long as necessary for operational or business requirements to minimize cloud storage costs.
Utilize tiered storage features if available and appropriate. These allow older data segments to be moved from more expensive, high-performance broker storage to cheaper object storage (e.g., S3), reducing overall storage costs while still allowing access to historical data.
Data Transfer Costs: Be acutely aware of data transfer costs in the cloud. This includes:
Inter-Availability Zone (AZ) traffic: Data replication between brokers in different AZs incurs costs.
Inter-Region traffic: Cross-region replication for disaster recovery can be expensive.
Data Egress: Transferring data out of the cloud provider's network to on-premises systems or other clouds. Careful architectural design, appropriate replication factors, and choice of region can help mitigate these costs.
Compression: Enable message compression (e.g., Snappy, Gzip, LZ4, Zstd) at the producer level. Compression reduces the size of messages, leading to lower network bandwidth consumption (and thus lower data transfer costs) and reduced storage footprint on brokers and in long-term storage. The choice of compression codec involves a trade-off between CPU overhead and compression ratio.
Managed Services Pricing Models: Thoroughly understand the pricing dimensions of any managed Kafka service being considered. Costs can be based on various factors, including the number and type of brokers, provisioned throughput, data ingestion volume, data processing volume, storage consumed, number of connectors, and data transfer. Choose a service and pricing tier that aligns with expected workload patterns and budget.
Autoscaling: Leverage autoscaling capabilities provided by managed services or Kubernetes deployments to dynamically adjust cluster capacity (brokers, compute resources) in response to changing demand. This helps avoid sustained overprovisioning and can lead to significant cost savings, especially for workloads with variable traffic.
Effective Kafka security and governance in the cloud are not optional extras or afterthoughts; they are foundational strategic pillars. A proactive, multi-layered approach is essential to strike the right balance between making data accessible for legitimate use and protecting it from unauthorized access or corruption. Kafka deployments, particularly in cloud environments, often handle high volumes of sensitive data, making their security posture a critical concern. While cloud platforms provide a rich set of powerful security tools (such as IAM for identity management, KMS for encryption key management, and VPCs for network isolation), they also operate under a shared responsibility model. The cloud provider secures the underlying infrastructure, but the customer is responsible for securing their data and applications within that infrastructure. Furthermore, cloud environments can introduce new attack vectors if not properly configured. Robust governance practices, including diligent schema management using a Schema Registry , clearly defined Access Control Lists (ACLs) , and comprehensive auditing , are indispensable for maintaining data quality, meeting compliance mandates, and ensuring that access to data streams is appropriately controlled. As Kafka's role becomes increasingly central to an organization's data strategy, the strength of its security and governance directly impacts business risk and the overall trustworthiness of the data it manages. A failure to implement robust security and governance can lead to severe consequences, including data breaches, non-compliance penalties, degradation of data quality, and uncontrolled data proliferation, all of which undermine the strategic value that Kafka is intended to deliver. Therefore, building a strong security and governance framework is not just a technical requirement but a strategic imperative that builds trust in the data, supports compliance with regulations like GDPR or HIPAA, and treats data as a valuable, well-managed asset. This involves designing security and governance into Kafka deployments from the outset, rather than attempting to retrofit them later, which is invariably more complex, costly, and less effective. This proactive stance should include regular security assessments and periodic audits of ACLs and other security configurations to adapt to evolving threats and business needs.
4.4. Advanced Architectural Patterns
As organizations mature in their use of Kafka, they can leverage it to implement more advanced architectural patterns that unlock further strategic value.
4.4.1. Kafka as a Unified Log for Data Consistency and Event Sourcing
Kafka's core design as an append-only, ordered, and durable log per partition makes it exceptionally well-suited for serving as a "unified log" or the backbone of an event sourcing architecture. In event sourcing, all changes to an application's state are captured as a sequence of immutable events. Instead of storing the current state directly, the system stores these events in chronological order. Kafka topics can act as this durable event store.
Benefits:
State Reconstruction: The current state of an application or entity can be rebuilt at any time by replaying the events from the log.
Auditing and Debugging: The complete history of changes is preserved, providing a comprehensive audit trail and simplifying debugging by allowing developers to inspect the sequence of events that led to a particular state.
Temporal Queries: It becomes possible to query the state of the system as it was at any point in the past.
Decoupled Views/Projections: Different consumers can process the same event stream to build various materialized views or projections of the data, tailored to specific needs, without affecting the source system.
Cloud Implication: The inherent durability provided by cloud storage (when used for Kafka broker persistence or tiered storage) combined with Kafka's replication mechanisms makes this pattern highly robust and reliable in cloud environments. Kafka's immutability and message replayability are key enablers for event sourcing. Kafka can act as the "source of truth" for application state changes.
4.4.2. Implementing Data Mesh Principles with Kafka
Data Mesh is a socio-technical architectural paradigm that advocates for decentralizing data ownership and architecture. It is founded on four key principles: domain ownership, data as a product, self-serve data infrastructure, and federated computational governance. Kafka can play a significant role in realizing a data mesh.
Kafka's Role in Data Mesh:
Data Products: Kafka topics, particularly when well-defined with clear schemas (managed by a Schema Registry) and associated metadata, can represent "data products." These data products are owned and managed by specific business domains.
Decentralized Ownership: The distributed nature of Kafka, where different teams can own and manage their topics (data products), aligns with the principle of domain ownership.
Self-Serve Data Infrastructure: While Kafka itself needs to be provisioned (often as a platform service), client libraries, Kafka Streams, and Kafka Connect enable domain teams to build their own data pipelines and processing logic, consuming and producing data products. Cloud platforms provide the underlying scalable infrastructure that can be provisioned on a self-serve basis to support these domain-specific Kafka workloads.
Interoperability: Kafka acts as an interoperability layer, allowing different domains to publish and subscribe to data products asynchronously.
Kafka Mesh Concept: The idea of a "Kafka Mesh" further supports data mesh principles by providing a way to link and route events between potentially disparate Kafka clusters that might represent different domains or data products, even across hybrid or multi-cloud landscapes. This mesh facilitates discovery and consumption of data products across the organization.
Cloud Synergy: Cloud platforms are natural enablers for data mesh architectures due to their support for self-service provisioning of resources, scalability on demand, and a wide array of tools that can be used by domain teams to build, deploy, and manage their data products leveraging Kafka.
4.4.3. Powering Real-Time Machine Learning and AI with Kafka
Kafka is increasingly becoming a critical component in real-time machine learning (ML) and artificial intelligence (AI) systems, moving beyond traditional batch-oriented ML pipelines.
Use Cases:
Real-Time Feature Engineering: Ingesting raw data streams (e.g., user clicks, sensor readings, transaction data) via Kafka, and then using stream processing engines like Apache Flink or Kafka Streams to compute features in real time for ML models.
Online Model Serving/Inference: Feeding these real-time features from Kafka topics to deployed ML models (e.g., hosted on TensorFlow Serving, Kubeflow, or cloud ML platforms) to generate predictions or classifications instantly. The predictions can then be published back to Kafka for downstream actions.
Continuous Model Training and Retraining: Streaming production data and model performance feedback through Kafka to continuously monitor models for drift (concept drift, data drift) and trigger retraining or online learning processes to keep models up-to-date and accurate.
Real-Time Anomaly Detection: Using Kafka to stream operational data, logs, or business metrics, and applying ML models to detect anomalies or outliers in real time.
Architecture: A typical real-time ML architecture involves Kafka as the central nervous system for data movement. Producers send raw data to Kafka. Stream processors (Flink, Spark Streaming, Kafka Streams) consume this data, perform feature engineering, and write features to new Kafka topics. ML model serving endpoints consume these features, make predictions, and publish results to output Kafka topics. Feedback loops for model monitoring and retraining also leverage Kafka to stream performance metrics and new training data. TikTok's recommendation system is a notable example, using Kafka and Flink extensively for real-time data ingestion, feature engineering, and online model updates to deliver personalized content at scale.
Cloud Benefits: Cloud platforms provide the scalable compute resources necessary for both training complex ML models and serving them at scale for real-time inference. They also offer managed ML services (e.g., Amazon SageMaker, Google AI Platform, Azure Machine Learning) that can be integrated into Kafka-based streaming pipelines. Kafka's ability to handle high-velocity event data reliably makes it an ideal backbone for these demanding AI/ML workloads.
5. Future Outlook and Strategic Recommendations
The landscape of data streaming, particularly with Apache Kafka in cloud environments, is continuously evolving. Understanding emerging trends and adhering to sound strategic and tactical recommendations will be crucial for organizations to maximize the value of their Kafka investments and maintain a competitive edge.
5.1. Emerging Trends in Kafka and Cloud Data Streaming
Several key trends are shaping the future of Kafka and its application in cloud-based data engineering:
Serverless Kafka: There is a growing momentum towards fully serverless Kafka offerings. These services aim to abstract away all infrastructure management, including cluster provisioning, scaling, and maintenance, allowing users to focus solely on producing and consuming data with a pay-per-use or pay-per-throughput pricing model. Examples include Amazon MSK Serverless and Redpanda Serverless. This trend aligns perfectly with broader cloud-native serverless paradigms, further lowering the barrier to entry for Kafka adoption and potentially optimizing costs for applications with intermittent or highly variable workloads.
Convergence of Streaming and Batch Processing: The traditional lines between stream processing and batch processing are blurring. Platforms and frameworks are increasingly aiming to provide unified APIs and engines that can handle both types of workloads seamlessly. Kafka often sits at the heart of such architectures, serving as the ingestion and real-time processing layer, while also feeding data into systems that might perform batch-style analytics or transformations (e.g., Apache Flink's unified stream/batch capabilities , or platforms like Databricks integrating deeply with Kafka for both streaming and batch AI/ML workloads ). This convergence simplifies data architectures, reduces data silos, and allows for more holistic and efficient data processing strategies.
Deeper AI/ML Integration: The synergy between Kafka and Artificial Intelligence/Machine Learning is strengthening. Kafka is becoming indispensable for operationalizing AI/ML by enabling real-time feature engineering, low-latency model inference, continuous online model training to combat model drift, and building robust MLOps pipelines. The ability to stream data into and out of ML models in real time makes AI applications more responsive and adaptive.
Expansion to Edge Computing: As data generation at the edge (e.g., IoT devices, retail stores, manufacturing plants) explodes, there's a growing need for localized data processing. Kafka, potentially in lightweight forms or through compatible edge streaming platforms, is being extended to the edge to capture, filter, aggregate, and analyze data closer to its source before selectively transmitting relevant information to central cloud Kafka clusters. This addresses challenges related to latency, bandwidth constraints, and data privacy for distributed applications.
Improved Multi-Cloud and Hybrid Management: With the increasing adoption of multi-cloud and hybrid cloud strategies, there is a demand for better tools and managed services that simplify the operation, management, and replication of Kafka clusters across these diverse and distributed environments. Solutions are emerging to facilitate seamless data movement, consistent governance, and unified monitoring across Kafka deployments regardless of their physical location.
The future trajectory of Kafka within cloud environments appears increasingly intertwined with its capacity for seamless integration with serverless operational paradigms and sophisticated AI/ML workflows. This evolution is pushing Kafka beyond its traditional role in data pipelines, positioning it as a critical enabler of intelligent, real-time decisioning systems. The demand for instantaneous AI-driven insights and the persistent organizational desire to minimize operational complexity are powerful forces driving this transformation. Consequently, Kafka offerings are adapting to become more serverless in nature and to provide deeper, more native integrations with AI and ML frameworks. Strategically, organizations should anticipate this shift by planning for Kafka to not merely transport data, but to actively participate in the "sense-respond-learn" loops of intelligent applications. This entails investing in the skills, tools, and architectural patterns that bridge Kafka with modern ML platforms and serverless compute services. The strategic value derived from Kafka will progressively be measured by its contribution to these next-generation, event-driven intelligent systems, rather than solely by its raw throughput or data storage capabilities. Cloud platforms serve as the natural crucible for this evolution, offering the elastically scalable compute, managed AI/ML services, and flexible infrastructure required to support these advanced Kafka-centric architectures.
Furthermore, as Kafka deployments become increasingly mission-critical and pervasive within enterprise cloud strategies, the strategic significance of robust multi-cloud and hybrid cloud capabilities, coupled with sophisticated data governance, will only intensify. This is driven by the need to mitigate vendor lock-in, enhance disaster resilience, ensure data interoperability across complex IT landscapes, and meet stringent regulatory requirements. Organizations are progressively adopting multi-cloud and hybrid models to achieve strategic objectives such as risk diversification, leveraging best-of-breed services from different providers, or complying with data sovereignty laws. Since Kafka is often a central data hub, its data frequently needs to traverse these varied environments. However, managing Kafka—its security, data consistency, and operations—across multiple cloud platforms or between cloud and on-premises locations introduces considerable complexity. This trend towards increasingly intricate enterprise IT landscapes necessitates a strategic approach to Kafka deployment that anticipates these challenges. Relying on a single cloud provider for all critical Kafka infrastructure can represent a strategic vulnerability. Consequently, multi-cloud replication and disaster recovery strategies become essential components of business continuity planning. As data becomes more distributed, ensuring consistent governance policies, uniform security enforcement, and harmonized schema management across Kafka clusters in different environments is crucial for maintaining data integrity, usability, and compliance. Architectural concepts like the "Kafka Mesh" are emerging to address these interoperability and governance challenges in distributed Kafka ecosystems. Therefore, designing Kafka deployments with multi-cloud and hybrid considerations from the outset, even if such a deployment is not an immediate requirement, provides vital strategic flexibility for future architectural evolution. This forward-looking approach should influence choices around managed service selection (favoring cloud-agnostic options where appropriate) and the adoption of standardized replication and governance technologies.
5.2. Key Recommendations for Tactical Success and Strategic Advantage
To effectively harness Apache Kafka in cloud environments, organizations should consider the following tactical and strategic recommendations:
Tactical Recommendations:
Invest in Schema Management Early: Implement a Schema Registry (e.g., Confluent Schema Registry) and enforce schemas (Avro, Protobuf, JSON Schema) for Kafka topics from the very beginning of any project. This proactive approach is fundamental for ensuring data quality, facilitating schema evolution without breaking consumers, and maintaining interoperability across services.
Prioritize Monitoring and Observability: Establish comprehensive monitoring and observability for Kafka clusters, brokers, topics, producers, and consumers. Leverage cloud provider monitoring tools (e.g., Amazon CloudWatch, Azure Monitor, Google Cloud Monitoring) and integrate them with Kafka-specific monitoring solutions (e.g., Prometheus, Grafana, specialized Kafka monitoring tools). Track key metrics such as throughput, latency, error rates, partition lag, and resource utilization to proactively identify and address issues.
Automate Operations Where Possible: For self-managed Kafka deployments, especially on Kubernetes, leverage Kafka operators like Strimzi to automate deployment, scaling, configuration management, and upgrades. Employ Infrastructure-as-Code (IaC) tools (e.g., Terraform, AWS CloudFormation, Azure Resource Manager, Google Cloud Deployment Manager) to define and manage Kafka infrastructure and related cloud resources reproducibly and consistently.
Optimize Configurations Continuously: Regularly review and tune Kafka configurations (broker, topic, producer, and consumer parameters) based on observed workload patterns, performance metrics, and evolving application requirements. What works well initially may need adjustment as data volumes or access patterns change. Refer to best practices for cloud-specific tuning (as outlined in Table 2).
Secure by Default: Implement robust security measures as a baseline for all Kafka deployments from day one. This includes enabling encryption in transit (SSL/TLS) and at rest (using cloud provider disk encryption), configuring strong authentication mechanisms (SASL, mTLS), defining granular authorization using ACLs, and applying strict network security policies (VPCs, security groups).
Strategic Recommendations:
Align Kafka Strategy with Business Goals: Clearly articulate how the adoption and use of Kafka will support broader business objectives. Whether it's to enable real-time customer experiences, improve operational efficiency through process automation, develop new data-driven products and services, or enhance risk management, this alignment will guide investment decisions and help measure success.
Choose the Right Deployment Model Strategically: The decision between self-managed Kafka and managed Kafka services should be a strategic one, based on a thorough evaluation of long-term TCO, the organization's operational capacity and technical expertise, the required level of control and customization, speed-to-market considerations, and strategic partnerships with cloud vendors. This is not a one-time decision; it should be revisited periodically as organizational needs evolve and new cloud offerings become available.
Embrace Event-Driven Architectures (EDA): Strategically leverage Kafka to build decoupled, resilient, and scalable systems based on event-driven principles. Encourage architectural thinking that moves beyond simple point-to-point integrations towards a more holistic EDA where Kafka acts as the central event backbone.
Plan for Data Governance Holistically: Integrate Kafka into the organization's broader data governance framework. This involves establishing clear policies and processes for data quality, data lineage, metadata management, data security, and compliance (e.g., GDPR, CCPA, HIPAA) for all data flowing through Kafka.
Foster a Streaming-First Culture: Where appropriate, encourage development teams and data analysts to think about data in terms of continuous streams and real-time processing opportunities, rather than defaulting to traditional batch-oriented approaches. This cultural shift can unlock new possibilities for innovation and responsiveness.
Stay Abreast of Cloud and Kafka Evolution: The cloud computing and Kafka ecosystems are dynamic and rapidly evolving. Strategically invest in continuous learning and evaluation of new cloud services, emerging Kafka features (like advancements in KRaft or tiered storage), new architectural patterns (such as serverless Kafka or data mesh implementations), and evolving best practices to ensure that the organization's Kafka deployments remain modern, efficient, and capable of delivering sustained strategic advantage.
By thoughtfully combining tactical execution with strategic foresight, organizations can effectively utilize Apache Kafka in cloud environments to build robust, scalable, and real-time data engineering solutions that drive significant business value.