Perception-Reasoning-Action (PRA): A Framework for Autonomous Intelligence
The conceptual framework known as the Perception-Reasoning-Action (PRA) cycle is not an arbitrary engineering construct but rather a model with deep roots in cognitive science and neuroscience. Its evolution from a simple biological feedback loop to a sophisticated computational architecture for artificial intelligence (AI).


The conceptual framework known as the Perception-Reasoning-Action (PRA) cycle is not an arbitrary engineering construct but rather a model with deep roots in cognitive science and neuroscience. Its evolution from a simple biological feedback loop to a sophisticated computational architecture for artificial intelligence (AI) reveals a great deal about our attempts to understand and replicate intelligent behavior. This lineage demonstrates that the PRA model is a principled approach to designing autonomous systems, grounded in the fundamental processes of how living organisms interact with their world.
The Perception-Action Cycle in Cognitive Science and Neuroscience
The intellectual precursor to the PRA model is the Perception-Action Cycle (PAC), a foundational concept in cognitive science that describes the continuous, interactive loop between an organism and its environment. According to this model, perception is not the passive reception of sensory data but an active process fundamentally shaped by an organism's actions. In turn, these actions are continuously guided and refined by perception. Neuroscientist Joaquin Fuster articulated this concept as "the circular flow of information from the environment to sensory structures, to motor structures, back again to the environment, to sensory structures, and so on, during the processing of goal-directed behaviour".
At the heart of the PAC is a feedback loop. An organism performs an action, which causes a change in the environment. This change is then perceived, providing new sensory information that informs the next action. This cyclical process is essential for adaptive behavior, allowing organisms to learn from their interactions and respond effectively to dynamic conditions. This biological model is closely linked to broader theories such as Embodied Cognition, which posits that cognitive processes are not abstract and disembodied but are deeply rooted in the body's physical interactions with the world.
The Introduction of Cognition: Evolving to the Perception-Reasoning-Action Model
While the PAC effectively describes the immediate, often reflexive, behaviors observed in many organisms, it is insufficient for explaining more complex, long-term, goal-oriented tasks that require foresight, strategy, and memory. Building computational systems capable of solving such problems revealed the need for an intermediate stage between sensing and acting. This led to the evolution of the two-stage PAC into the three-stage Perception-Reasoning-Action (PRA) model.
The introduction of an explicit "Reasoning" component was a critical architectural addition, representing the cognitive deliberation that bridges perception and action. This stage encompasses a suite of higher-order processes, including knowledge representation, decision-making, conflict resolution, performance monitoring, and planning. The reasoning module allows an agent to move beyond direct stimulus-response and to consider future outcomes, evaluate alternative courses of action, and formulate multi-step strategies to achieve complex objectives. This capacity for deliberation is what fundamentally distinguishes a sophisticated, intelligent agent from a simple reactive system and is a computational necessity for bridging the "temporal gaps" in the perception-action cycle.
The Engineering Analogue: Sense-Plan-Act in Classical Robotics
The direct engineering implementation of the PRA concept in classical AI and robotics is the Sense-Plan-Act (SPA) paradigm, which was the predominant methodology for robot control for many years. The SPA framework formalizes the cycle into three distinct, sequential steps :
Sense: The robot gathers information about its environment using its sensors.
Plan: The robot uses this sensory data to create or update an internal "world model" and, based on this model and its goals, plans its next move.
Act: The robot executes the planned move using its actuators.
This cycle is iterative; after acting, the robot senses the new state of the world, and the entire process repeats. This iterative nature allows the robot to respond to environmental changes, though in classical implementations, the lengthy planning phase often resulted in slow and deliberate behavior.
The very structure of the PRA/SPA cycle—Sense, Plan, Act—codifies a specific and influential theory of intelligence: intelligence as rational deliberation. This architecture places the cognitive component at its center, implying that an agent's intelligence resides primarily in its ability to construct an accurate model of the world and devise an optimal plan within it. This perspective reflects the dominant paradigm in early AI research, which often equated intelligence with symbolic reasoning and logical deduction. This architectural choice prioritizes optimality and correctness over speed and reactivity, an assumption that proves to be a significant limitation in highly dynamic environments and which ultimately spurred the development of alternative control architectures.
Deconstructing the Cycle: An Analysis of Core Components
The PRA cycle provides a structured framework for intelligent agency, with each stage serving a distinct but interconnected function. The evolution of AI technologies, particularly deep learning and large-scale models, has profoundly transformed the capabilities of each component, moving from rudimentary sensors and rigid logic to sophisticated perception and fluid, commonsense reasoning.
Perception: The Agent's Gateway to the World
The perception stage is the agent's sole source of information about its internal state and the external world. The quality and richness of this information fundamentally constrain the sophistication of any subsequent reasoning and action.
Sensory Modalities and Hardware
Perception begins with data acquisition through sensors. These can be broadly categorized into two types: proprioceptive sensors, which measure the agent's internal state (e.g., joint angles, motor speed, battery level), and exteroceptive sensors, which gather information about the external environment. For physical robots, the suite of exteroceptive sensors is diverse and includes:
Cameras (Visual Perception): Mimicking human sight to capture images and video for object recognition and scene understanding.
LiDAR (Light Detection and Ranging): Emitting laser pulses to create precise 3D point-cloud maps of the environment.
Radar: Using radio waves to detect objects and their velocities, effective in adverse weather conditions.
Ultrasonic and Infrared Sensors: Detecting proximity to objects for simple obstacle avoidance.
Tactile Sensors: Providing a sense of touch for manipulation tasks.
For software-based agents, perception occurs in the digital realm. Their "senses" include processing textual user queries, interpreting auditory commands, parsing structured data from API responses, and monitoring the state of a system. Modern foundation models have enabled a significant leap in this area, allowing agents to operate with multimodal perception, simultaneously processing and integrating information from text, images, audio, and code.
The Deep Learning Revolution in Machine Perception
The most significant advancement in machine perception has been the rise of deep learning, especially Convolutional Neural Networks (CNNs). Before deep learning, perception systems relied on hand-crafted feature extractors, which were brittle and difficult to generalize. Deep learning enables end-to-end learning, where the model automatically discovers relevant features from raw sensor data. This has led to superhuman performance in core perceptual tasks that are essential for autonomy, with major advancements often presented at premier computer vision conferences like CVPR and ICCV. These tasks include:
Object Detection and Classification: Identifying and categorizing objects within a scene, such as pedestrians, vehicles, and traffic signs.
Semantic Segmentation: Assigning a class label (e.g., "road," "building," "sky") to every pixel in an image, providing a rich, structural understanding of the environment.
Pose Estimation: Determining an object's precise 3D position and orientation, which is critical for robotic manipulation and interaction.
However, transferring these powerful vision models to robotic applications presents unique challenges, including the need for real-time operation on hardware with limited computational resources and power.
Reasoning: The Engine of Deliberation and Strategy
The reasoning stage is the cognitive core of the agent, responsible for transforming the rich, semantic information from the perception stage into a coherent plan or strategy.
From Symbolic AI to Foundation Models
Early AI systems approached reasoning through symbolic logic, developing algorithms that mimicked the step-by-step deduction humans use to solve puzzles. While effective for well-defined problems, these methods often succumbed to a "combinatorial explosion," becoming intractably slow as the problem size grew. This led to the development of more practical planning algorithms, such as sampling-based motion planners in robotics, which find feasible rather than optimal paths in complex spaces.
The contemporary landscape of AI reasoning has been completely reshaped by the advent of foundation models, particularly Large Language Models (LLMs) and Vision-Language Models (VLMs). These models now serve as the central reasoning engine for a new generation of AI agents. Their strength lies in handling tasks that were notoriously difficult for classical systems, such as:
Navigating ambiguous or incomplete instructions.
Inferring user intent and applying commonsense knowledge.
Synthesizing information and identifying relationships across vast amounts of unstructured data.
Specialized Large Reasoning Models (LRMs) are now being explicitly trained not just to provide an answer but to generate a structured, step-by-step "thinking part" that externalizes their logical process. This is often achieved through advanced techniques like reasoning fine-tuning with reinforcement learning, moving beyond the simpler "Chain-of-Thought" prompting used in standard LLMs.
Advanced Reasoning: Theory of Mind and Multi-Agent Collaboration
For agents designed to interact with humans, reasoning must extend beyond task planning to social cognition. Advanced architectures are incorporating a computational "Theory of Mind" (ToM), which allows the agent to model the mental states—beliefs, goals, and intentions—of its human collaborators. Possessing a ToM enables a robot to dynamically adjust its level of autonomy, for example, by proactively offering assistance when it infers a user is struggling, or by providing explanations for its actions to build trust. This capability is crucial for effective and trustworthy human-robot interaction (HRI).
Action: Executing Intent in the Physical and Digital Realms
The action stage is where the agent's internal deliberations manifest as a tangible impact on its environment.
Actuation and Control Systems
For a physical robot, the plan generated during the reasoning stage is translated into low-level control commands that drive its actuators—the motors, servos, and other components that produce physical motion. For example, a high-level plan like "move forward one meter" is decomposed into a precise sequence of voltages sent to the wheel motors.
For a software agent, actions are digital operations. These can range from sending a message in a chat interface to more complex tasks like calling an external API to retrieve information, updating a record in a database, or executing a piece of code.
The Feedback Loop: Action's Influence on Future Perception
Crucially, action is not the final step but merely one turn of a continuous cycle. Every action, whether physical or digital, alters the state of the world. This new state is then captured in the next perception phase, creating a vital feedback loop. This loop is the basis for performance monitoring and error correction. By comparing the perceived outcome of an action with the expected outcome, an agent can detect whether its plan is succeeding and, if not, implement corrective measures in the next reasoning cycle.
The quality of an agent's reasoning is fundamentally constrained by the quality of its perception. A classical robot equipped only with simple bump sensors can only form simple plans, such as "if bumped, turn left". Its internal model of the world is extremely limited. In contrast, the revolution in deep learning-based perception provides the reasoning module with a rich, semantically detailed understanding of its surroundings—for instance, "a pedestrian is 10 meters ahead on the sidewalk and moving away". This high-fidelity input enables far more nuanced reasoning. An LLM-based reasoning engine can now generate sophisticated plans like, "Given the pedestrian's presence and trajectory, I will proceed with caution and slightly reduce speed, rather than executing an unnecessary emergency stop". The recent explosion in AI reasoning capabilities is therefore not an isolated event; it is directly enabled by and dependent upon the parallel revolution in machine perception.
Furthermore, the integration of LLMs as reasoning engines is blurring the traditional, rigid separation between the reasoning and action stages. In classical SPA, the "Plan" was a static data structure (e.g., a list of waypoints) passed to the action module for execution. In modern agentic frameworks like ReAct, the LLM's reasoning process is dynamic and interleaved with action. The model generates a "thought" (reasoning), which leads to an "action" (e.g., an API call). The result of that action is then immediately fed back into the LLM's context as new perceptual input for the next thought. This transforms the architecture from a sequential pipeline into an iterative dialogue between the agent's "mind" and its environment. The "Plan" is no longer a monolithic artifact but an emergent strategy that evolves with each action-feedback cycle.
The Architectural Landscape: A Comparative Analysis of Control Paradigms
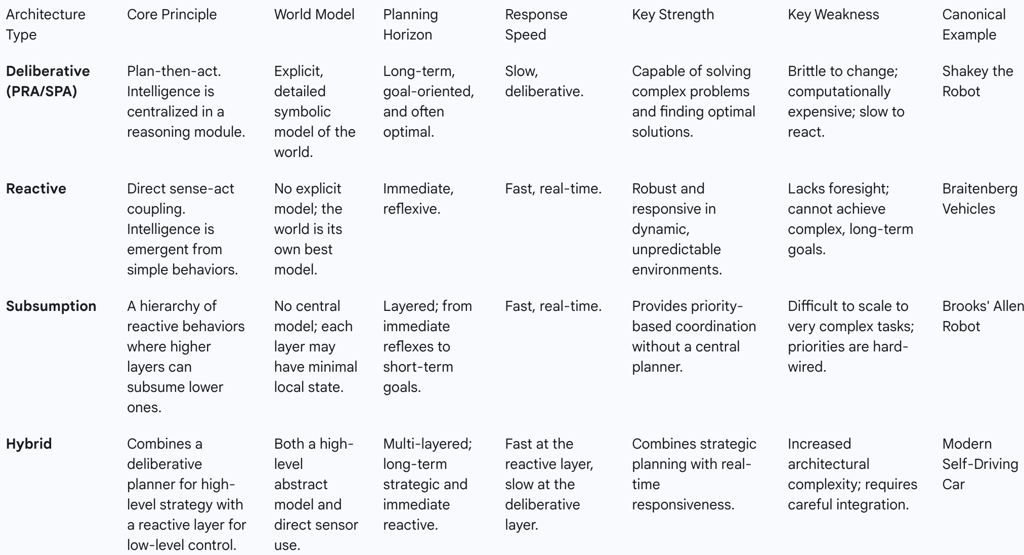
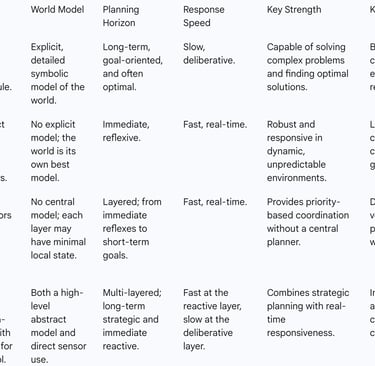
The Perception-Reasoning-Action model, while foundational, is not the only framework for designing autonomous systems. Understanding it in the context of alternative architectures—particularly reactive and hybrid models—is essential for appreciating its specific strengths, weaknesses, and the engineering trade-offs involved in building intelligent agents.
The Deliberative Approach: Strengths and Weaknesses of the PRA/SPA Model
The PRA/SPA cycle is the archetypal deliberative architecture. Its core strength lies in its capacity for strategic, long-term planning. By constructing a detailed internal model of the world, it can reason about future states and compute optimal or near-optimal sequences of actions to achieve complex goals. This makes it well-suited for tasks in stable, predictable environments where time for computation is not the primary constraint.
However, this same reliance on modeling and planning is its greatest weakness. The process is computationally expensive and slow. In dynamic and unpredictable environments, the world can change faster than the agent can update its model and create a new plan. This can lead to the agent executing actions based on an obsolete plan, making the system brittle and unresponsive. This challenge is famously known as the "frame problem" in AI—the difficulty of representing what remains the same in a dynamic world.
The Reactive Paradigm: Intelligence Without Representation
Developed in direct opposition to the deliberative model, reactive control architectures propose that intelligent behavior can emerge without explicit reasoning or world models. These systems rely on a tight, direct coupling of perception and action. They are built from a collection of simple rules or behaviors that map sensor inputs directly to actuator outputs (e.g., "if an obstacle is detected within 0.5 meters, turn left").
The primary advantages of reactive systems are their speed, simplicity, and robustness in dynamic environments. Because they do not engage in time-consuming deliberation, they can react almost instantaneously to changes. Their main limitation is a lack of foresight. Without a world model or planning capabilities, they cannot pursue long-term goals and are prone to getting stuck in simple traps, such as oscillating in a U-shaped obstacle.
The Subsumption Architecture: A Layered, Behavior-Based Approach
A highly influential implementation of the reactive paradigm is the subsumption architecture, proposed by roboticist Rodney Brooks. This architecture decomposes an agent's overall behavior into a hierarchy of simple, independent layers. Each layer corresponds to a specific level of behavioral competence. For example, a mobile robot might have a low-level layer for "Avoid Obstacles," a middle layer for "Wander," and a high-level layer for "Explore".
All layers run in parallel, but higher layers have the ability to subsume—that is, suppress or inhibit—the outputs of lower layers. In the example above, the "Wander" layer might be sending commands to the wheels to move forward. However, if the "Avoid Obstacles" layer detects an imminent collision, it can inhibit the "Wander" layer's output and take control of the wheels to execute a swerve. This provides a decentralized, priority-based mechanism for coordinating behaviors without a central planner.
Hybrid Architectures: Synthesizing Deliberation and Reaction
Recognizing the complementary strengths and weaknesses of deliberative and reactive approaches, most modern, complex robotic systems employ a hybrid architecture. These systems seek to combine the strategic foresight of a planner with the rapid response of a reactive system.
Typically, a hybrid architecture is structured in layers. A high-level deliberative layer performs tasks like global route planning, which do not require real-time updates. This layer passes sub-goals to a middle layer that sequences actions. At the lowest level, a reactive layer handles immediate concerns like collision avoidance and maintaining balance. This layered approach allows a robot to pursue a long-term, strategic goal while remaining robustly responsive to the immediate, dynamic conditions of its environment. It is widely considered the most practical and effective solution for building capable robots today.
The PRA Cycle in Practice: Real-World Applications and Impact
The Perception-Reasoning-Action framework is not merely a theoretical construct; it is the operational backbone of many of the most advanced autonomous systems in use today. Its application across diverse domains—from vehicles navigating public roads to software agents managing digital workflows—demonstrates its fundamental importance in creating functional and intelligent systems.
Autonomous Vehicles: Navigating the Complexities of the Real World
The software stack of a self-driving car is a canonical example of a sophisticated, hybrid PRA architecture. Each stage of the cycle is implemented as a complex subsystem:
Perception: An extensive array of sensors, including cameras, LiDAR, and radar, work in concert. Their data is fused to create a comprehensive, 360-degree, 3D model of the vehicle's surroundings. Deep learning models perform tasks like detecting and classifying other vehicles and pedestrians, reading traffic signs, and identifying lane markings.
Reasoning/Planning: This is a multi-layered deliberative process.
Route Planning: At the highest level, a global path is calculated from the start to the final destination, similar to a GPS navigation system.
Behavior Planning: This tactical layer makes decisions based on traffic rules, road conditions, and the predicted movements of other agents. It decides on maneuvers like changing lanes, yielding, or overtaking.
Motion Planning: At the lowest planning level, a precise, smooth, and collision-free trajectory is generated for the vehicle to follow over the next few seconds.
Action/Control: The control subsystem takes the planned trajectory as input and translates it into low-level commands for the vehicle's actuators—steering, acceleration, and braking—to execute the maneuver precisely.
Recent advancements are integrating Vision-Language Models (VLAMs) into the reasoning stage, enabling the vehicle to generate natural language explanations for its actions, such as, "I am slowing down because I detect a pedestrian preparing to cross the street," enhancing transparency and trust.
Autonomous Drones: Perception and Planning in Three Dimensions
Unmanned Aerial Vehicles (UAVs), or drones, rely on the SPA/PRA cycle for a wide range of applications, including aerial surveillance, package delivery, and agricultural monitoring.
Sense: Onboard sensors, including cameras, GPS, and Inertial Measurement Units (IMUs), gather data about the drone's position, orientation (attitude), and external conditions like wind speed.
Plan: Path planning algorithms must operate in three dimensions, generating trajectories that avoid obstacles (e.g., buildings, trees) while considering factors like aerodynamic forces and battery consumption.
Act: The plan is executed by the flight controller, which sends commands to the actuators—the motors—to adjust the rotational speed of each propeller, thereby controlling the drone's movement and stability.
Agentic AI: The PRA Loop in Modern Software Agents
The PRA loop serves as the cognitive engine for the new wave of "agentic AI," systems that can autonomously perform complex, multi-step tasks in digital environments.
Perceive: The agent ingests information from various sources, such as a user's natural language request, data from a connected application via an API, or the current state of a workflow.
Reason: At its core, an LLM decomposes the user's high-level goal into a sequence of smaller, executable steps. It then decides which tool to use for the current step—for example, a web search engine for information gathering, a code interpreter for calculations, or another specialized API.
Act: The agent executes the chosen action by calling the selected tool or function. The output of this action is then fed back into the agent's context, becoming the perceptual input for the next turn of the PRA loop, allowing it to iteratively progress toward the goal.
This framework powers applications like customer support bots that can manage an entire resolution workflow, AI co-pilots that automate research and coding tasks, and autonomous systems that monitor and manage cloud infrastructure.
Interactive Entertainment: Simulating Believable Behavior in Video Game AI
The non-player characters (NPCs) that populate virtual worlds in video games operate on a simplified version of the PRA cycle to create believable and interactive behaviors.
Perception: The NPC's code "perceives" the state of the game world, including the player's location, the positions of other NPCs, and the status of environmental objects.
Reasoning: Based on its pre-programmed goals (e.g., "patrol this area," "attack the player on sight"), the AI uses a decision-making system, such as a behavior tree or a finite-state machine, to select an appropriate action from its repertoire.
Action: The chosen action is executed through the game's animation and physics engines, causing the character to move, speak, or interact with objects. The feedback loop is essential for creating adaptive behavior; by comparing the perceived outcome of an action with its predicted outcome, an AI agent can learn from its mistakes and adjust its strategy.
The modular separation of Perception, Reasoning, and Action, while a significant advantage for software engineering, also introduces a potential systemic weakness. In a complex system like a self-driving car, specialized teams can develop each module independently. However, this creates rigid interfaces. An error or a measure of uncertainty from the perception module—for instance, misclassifying a harmless plastic bag as a dangerous rock—is often passed downstream to the planning module as an incontrovertible "fact". The planner then diligently computes an "optimal" plan based on this flawed input, leading to a perfectly executed but contextually incorrect action, such as an unnecessary and dangerous swerve. This fundamental trade-off between engineering tractability and holistic, uncertainty-aware reasoning is a primary motivator for research into more integrated, end-to-end learning models.
Furthermore, a direct relationship exists between the complexity of an agent's action space and the required sophistication of its reasoning module. A simple thermostat with two actions ("on," "off") needs only rudimentary conditional logic. In contrast, an autonomous vehicle possesses a continuous and intricate action space (steering, acceleration) and must reason about its interactions with numerous other dynamic agents, necessitating a complex, multi-layered planning system. An agentic LLM has a virtually infinite action space—any tool it can call, any text it can generate—which demands a reasoning engine capable of open-ended problem decomposition and dynamic planning. As we build agents with more expressive capabilities, the performance bottleneck increasingly shifts from perception and action to the core challenge of reasoning.
The Modern Synthesis: Integrating Advanced Learning Paradigms
The classical PRA framework, with its distinct and often hand-engineered modules, is being reshaped by modern machine learning. Advanced paradigms like end-to-end learning and deep reinforcement learning are not necessarily replacing the conceptual cycle but are instead automating, optimizing, and integrating its components in powerful new ways. This synthesis is leading to more capable, adaptive, and robust autonomous systems.
End-to-End Learning: Challenging the Modular Orthodoxy of PRA
End-to-end (E2E) learning presents a radical departure from the modular PRA approach. Instead of breaking the problem into separate stages of perception, planning, and control, E2E learning aims to learn a direct mapping from raw sensor inputs to final action outputs using a single, large neural network. This method bypasses the need for intermediate, human-designed representations like a symbolic world model or a set of behavioral rules. The "reasoning" process becomes an implicit, emergent property distributed across the learned weights of the network.
The primary benefit of this approach is its potential for greater adaptability and robustness. By learning directly from data, E2E systems can discover complex behaviors and correlations that a human engineer might not anticipate, allowing them to handle uncertainty more gracefully. However, this comes at the cost of interpretability. Unlike the modular PRA cycle, where each component's inputs and outputs can be inspected, an E2E system often functions as a "black box," making it difficult to debug, verify, or trust, which is a major concern for safety-critical applications.
Deep Reinforcement Learning: Optimizing Decision-Making and Action Selection
Deep Reinforcement Learning (DRL) is a machine learning technique that has become a dominant method for training the decision-making component of autonomous agents. In the context of the PRA cycle, DRL is a powerful tool for developing the
Reasoning module. Rather than having a programmer explicitly define the logic for choosing actions, a DRL algorithm discovers an optimal strategy, known as a "policy," through a process of trial and error.
The DRL agent interacts with its environment (or a simulation of it), taking actions based on its perceptions. For each action, it receives a numerical "reward" signal—positive for desirable outcomes, negative for undesirable ones. The agent's goal is to learn a policy that maximizes its expected cumulative reward over time. DRL has proven highly effective for complex control problems, such as robotic manipulation and autonomous navigation in cluttered, dynamic environments, where traditional planning methods struggle.
It is important to recognize that these advanced learning paradigms do not abolish the conceptual PRA framework; rather, they automate and optimize its constituent parts. An E2E neural network still performs the functions of perception (in its initial layers), reasoning (in its hidden layers), and action selection (in its output layer). Likewise, DRL is not a new architecture but a training methodology used to learn the optimal policy that maps perceptions to actions. These techniques shift the engineering focus from designing explicit logic for each module to designing the network architecture, the reward function, and the training data curriculum. The fundamental loop of sensing, thinking, and acting persists.
The ReAct Framework: Interleaving Reasoning and Action for Enhanced Performance
A key challenge in using LLMs as reasoning engines is their tendency to "hallucinate" or generate plans based on outdated or incorrect factual knowledge. The ReAct (Reason + Act) framework is a novel paradigm designed to mitigate this issue by tightly grounding the model's reasoning in real-world feedback.
Instead of generating a complete plan upfront, a ReAct agent interleaves steps of reasoning and acting. First, the LLM generates a "thought"—an explicit, verbal reasoning trace outlining what it needs to do next and why. Based on this thought, it generates an "action," typically a simple call to an external tool like a search engine or calculator. The "observation," or the result from that tool, is then fed back into the LLM's context. This new information grounds the next reasoning step, allowing the agent to dynamically update its plan, handle exceptions, and correct its own mistakes in a tight loop.
The ReAct framework represents a powerful convergence of the historically distinct deliberative and reactive principles. The "Reason" step is deliberative, involving explicit planning and hypothesis formation. The "Act" step is small and reactive, providing immediate feedback from the environment. The rapid loop connecting them creates a hybrid system that possesses the goal-directedness of a planner but the real-time grounding and error-correction of a reactive system. This was impractical with classical AI, as symbolic planners were too slow to operate in such a tight cycle. The speed and flexibility of LLMs have made this potent architectural pattern possible, synthesizing the long-standing dichotomy between planning and reaction.
Challenges, Limitations, and the Future of Autonomous Agency
Despite significant progress, the PRA framework and its modern implementations face persistent challenges that define the frontiers of AI research. Overcoming these limitations is key to developing more robust, general-purpose, and trustworthy autonomous agents.
The Frame Problem and Combinatorial Explosion in Deliberative Systems
The classical challenges that first exposed the limitations of purely deliberative systems remain relevant. The frame problem—the difficulty of efficiently representing which aspects of the world remain unchanged after an action—and combinatorial explosion—the exponential growth of possible future states and action sequences—make exhaustive planning intractable for all but the simplest problems. While modern computational power and heuristic algorithms have greatly mitigated these issues, they represent fundamental theoretical limits on any system that relies on explicit, long-horizon planning.
Latency, Brittleness, and the Challenge of Uncertainty
A core limitation of any deliberative model is latency. The time required to perceive, reason, and act can be too great for highly dynamic environments, where an unexpected event can render a carefully constructed plan obsolete before it can be executed. This brittleness is compounded by the pervasive issue of uncertainty. While early AI systems were limited by computational power, modern systems are primarily limited by their ability to handle uncertainty at every stage of the cycle.
Perceptual Uncertainty: Sensors are noisy, and environments can be partially occluded, leading to incomplete or inaccurate perceptions.
Reasoning Uncertainty: The outcomes of actions are often probabilistic, and the agent's model of the world is never perfect.
Action Uncertainty: Motor commands may not be executed with perfect precision.
Therefore, the focus of modern robotics research is shifting from finding the single "optimal" plan to developing "robust" policies that can succeed under a wide range of uncertain conditions. This involves the use of Bayesian techniques and probabilistic models to represent and reason about uncertainty throughout the entire PRA cycle.
Furthermore, while LLMs have revolutionized the reasoning stage, they possess their own unique limitations. A critical issue for robotics is that these models reason in the abstract space of language, not in the concrete space of physics and geometry. They lack an innate, intuitive understanding of spatial relationships and physical forces, a challenge that newer models aim to address by grounding reasoning in perception tokens that explicitly encode geometric information.
The Path Forward: Active Perception, Embodied Cognition, and AI Safety
The future of autonomous agency lies in creating tighter integrations between the stages of the PRA cycle and developing systems that can learn and generalize more effectively.
Active Perception: The next evolution of perception is moving from a passive to an active process. In an active perception system, the agent's reasoning module directs its sensors. It decides where to look or what to sense next in order to gain the most mission-critical information, making perception a goal-driven action in itself.
Embodied Cognition: This brings the discussion full circle, reinforcing the idea that true intelligence is not an abstract computation but an emergent property of the dynamic interaction between an agent's body, its control system, and its environment. Future architectures will likely move beyond a rigid PRA pipeline toward deeply integrated systems where perception, reasoning, and action are co-dependent and co-evolve through learning.
AI Safety and Explainability: As AI systems become more powerful and autonomous, ensuring they are safe and trustworthy is paramount. The modularity of the PRA cycle provides a valuable framework for this endeavor. By separating the components, it offers distinct points for inspection, debugging, and verification. We can analyze the perception module to understand what the agent "sees," examine the reasoning module's output to understand its "intentions," and monitor its actions to verify its "behavior." Frameworks like ReAct, which compel an LLM to externalize its reasoning trace, are a direct application of this principle, making the agent's decision-making process more transparent.
In conclusion, the Perception-Reasoning-Action cycle remains a cornerstone of AI and robotics. It provides an essential conceptual blueprint for building intelligent systems. Even as advanced techniques like end-to-end learning and DRL automate and integrate its components, the fundamental loop of sensing, thinking, and acting endures. The ongoing challenges of handling uncertainty and ensuring safety mean that the principles embodied in the PRA framework will continue to guide the development of AI that is not only more capable but also more accountable and aligned with human goals.