Quantum Large Language Model Fine-Tuning Leveraging Cloud
This report provides a comprehensive overview of the theoretical foundations, architectural designs, practical implementation advice, and future trajectory of quantum LLM fine-tuning within cloud environments.


The landscape of artificial intelligence is undergoing a profound transformation with the emergence of quantum-enhanced Large Language Model (LLM) fine-tuning. This report explores the strategic integration of quantum computing into LLM adaptation, highlighting its capacity to significantly improve model performance, particularly in scenarios characterized by data scarcity and complex data correlations. Hybrid quantum-classical approaches are at the forefront of this evolution, demonstrating superior accuracy and remarkable parameter efficiency compared to purely classical methods. The pivotal role of cloud computing in democratizing access to this nascent technology is also examined, as Quantum-as-a-Service (QaaS) platforms enable broader experimentation and accelerate the development of advanced quantum-enhanced LLM applications without necessitating substantial upfront infrastructure investments. While the field faces considerable challenges related to hardware limitations, quantum noise, and integration complexity, ongoing research and sophisticated mitigation strategies are paving the way for practical applications in specialized domains. This report provides a comprehensive overview of the theoretical foundations, architectural designs, practical implementation advice, and future trajectory of quantum LLM fine-tuning within cloud environments.
1. Introduction: The Convergence of Quantum, LLMs, and Cloud
The rapid advancements in artificial intelligence (AI), particularly in Large Language Models (LLMs), have revolutionized numerous industries. Concurrently, quantum computing is progressing from theoretical concepts to tangible hardware, offering unprecedented computational capabilities. The convergence of these two fields, specifically in the context of LLM fine-tuning, represents a frontier with immense potential.
Defining LLM Fine-Tuning
LLM fine-tuning is a critical process for adapting pre-trained models to specific tasks or domains, effectively leveraging the general knowledge acquired during their initial training on vast datasets. This technique is a form of transfer learning, which proves more efficient and cost-effective than training a new model from scratch for niche applications. The process typically involves further training a pre-existing LLM on a smaller, task-specific dataset to enhance its performance and relevance. Through fine-tuning, an LLM's conversational tone can be adjusted, or its foundational knowledge can be supplemented with proprietary or domain-specific data, enabling specialization for particular use cases.
Quantum Computing Fundamentals Relevant to AI
Quantum computing introduces a new paradigm for computation, utilizing the principles of quantum mechanics. Unlike classical computers that employ bits representing 0s or 1s, quantum computers use quantum bits, or qubits, which can exist in multiple states simultaneously, a property known as superposition. Furthermore, qubits can become entangled, meaning their states are intrinsically linked such that the state of one instantly influences the state of another, regardless of distance. This entanglement enables quantum computers to process vast amounts of information in parallel. Quantum algorithms can also exploit quantum interference to amplify correct solutions while suppressing incorrect ones. These unique quantum properties hold the promise of enabling quantum computers to solve certain complex problems significantly faster and with greater accuracy than their classical counterparts.
The Emerging Synergy: Why Quantum Computing for LLMs?
LLMs, particularly models like GPT, are inherently data-intensive and computationally demanding, requiring the processing of massive datasets and the adjustment of billions of parameters during training. Quantum computing offers a compelling solution to these challenges, with the potential for faster training, enhanced Natural Language Processing (NLP) capabilities, and improved security and privacy.
The integration of quantum computing into LLM fine-tuning is primarily driven by its ability to enhance the model's classification capabilities, especially in tasks involving complex data correlations. Quantum layers possess the potential to capture non-local correlations in data more effectively than classical networks, leading to improved accuracy, particularly in low-data regimes. The most impactful near-term quantum applications are anticipated to be hybrid, strategically augmenting classical systems where quantum capabilities deliver the most value.
A key motivation for quantum LLM fine-tuning is to address the expressive bottleneck observed in classical low-rank approximation methods, such as Low-Rank Adaptation (LoRA). While LoRA is effective, its representation capacity is constrained in complex tasks or high-rank dependency settings, potentially limiting model adaptability. By introducing quantum layers, the aim is not to replace classical LLMs entirely, but to strategically enhance their ability to learn and represent intricate, non-local data correlations that classical networks struggle with, particularly in resource-constrained or data-limited scenarios. The inherent properties of quantum mechanics, such as superposition and entanglement, allow quantum circuits to model higher-dimensional, non-linear relationships in data that are intractable or inefficient for classical methods. By strategically integrating these quantum components, the hybrid model gains a superior ability to discern subtle, complex patterns, thereby breaking through the expressivity limits of classical fine-tuning. This implies that quantum fine-tuning is not merely a marginal improvement but a fundamental shift in how LLMs can learn from complex data, potentially unlocking new applications in fields with intricate, high-dimensional data where classical models encounter limitations.
2. Quantum-Enhanced LLM Fine-Tuning: Benefits and Foundations
The integration of quantum computing into LLM fine-tuning is underpinned by robust theoretical foundations and offers several compelling advantages, particularly in specialized and data-constrained environments.
Theoretical Underpinnings
Hybrid quantum-classical approaches are designed to leverage quantum circuits to enhance classification capabilities, especially in tasks involving complex data correlations. Quantum layers are hypothesized to capture non-local correlations in data more effectively than classical networks, leading to improved accuracy, particularly in low-data regimes. The introduction of a Quantum Machine Learning (QML) layer is believed to enhance a model's expressivity and accuracy, especially when dealing with non-local data correlations. This is because quantum systems support operations beyond simply nearest-neighbor pairs of qubits, enabling more complex interactions. Furthermore, quantum-inspired embeddings, which are grounded in foundational quantum mechanics concepts like superposition and entanglement, redefine data representation by enabling more intricate and expressive embeddings. These embeddings have demonstrated superior performance compared to traditional methods in high-dimensional, low-sample scenarios.
Key Advantages
The strategic application of quantum computing to LLM fine-tuning yields a range of significant benefits:
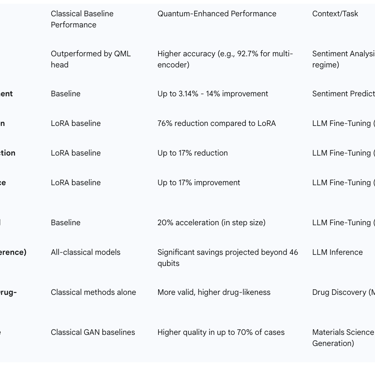
Improved Accuracy: Hybrid quantum-classical models have consistently demonstrated superior classification accuracy compared to classical baselines, such as logistic regression, Support Vector Classifiers (SVC), and basic neural networks, in sentiment analysis tasks like the Stanford Sentiment Treebank (SST-2). IonQ's research, for instance, reported accuracy improvements ranging from 3.14% to 14% over classical architectures of comparable model size. Notably, a multi-encoder quantum setup achieved a test accuracy of 92.7% on SST-2, even in a low-data regime, highlighting its efficiency in challenging conditions.
Parameter Efficiency and Reduced Computational Overhead: Parameter-Efficient Fine-Tuning (PEFT) methods are crucial for LLMs to reduce computational overhead while preserving performance. Quantum-enhanced PEFT methods, such as Quantum Tensor Hybrid Adaptation (QTHA) and Quantum Weighted Tensor Hybrid Network (QWTHN), integrate Quantum Neural Networks (QNNs) with tensor networks. These methods have shown remarkable efficiency, reducing trainable parameters by up to 76% compared to classical LoRA, while simultaneously improving test set performance by up to 17% and reducing training loss by up to 17%. This substantial reduction in parameters not only enhances model trainability but also accelerates convergence (by up to 20% in some scenarios) and mitigates overfitting risks, leading to lower computational costs.
Accelerated Training and Optimization: Quantum computers possess the capability to process multiple data points concurrently and perform complex matrix operations at a faster rate than classical systems. This can drastically reduce the training time for AI models and enable the handling of much larger and more complex datasets. Quantum computing is also well-suited for tackling computationally intensive optimization problems, with algorithms like Quantum Approximate Optimization Algorithm (QAOA) and Variational Quantum Eigensolver (VQE) enhancing AI optimization tasks, including fine-tuning. IonQ's research further projected significant energy savings for inference using hybrid quantum algorithms as the problem size scales beyond 46 qubits.
Enhanced Natural Language Processing (NLP) Capabilities: Quantum Natural Language Processing (QNLP) aims to adapt classical NLP techniques, such as word embeddings, recurrent neural networks, and transformers, for quantum computers. This adaptation can lead to more efficient processing of language structures and the development of improved AI assistants. Quantum neural networks, which utilize qubits instead of classical bits, hold the promise of revealing more profound linguistic patterns and subtleties in language data, thereby enhancing accuracy in tasks like sentiment analysis, language translation, and context-aware understanding.
Improved Security and Privacy: Quantum computing plays a significant role in strengthening the security and privacy aspects of LLMs. Quantum cryptography, particularly quantum key distribution (QKD) protocols, provides unmatched security measures for safeguarding sensitive information. This is particularly vital for industries such as healthcare, finance, and law, where maintaining data confidentiality is essential.
The combined benefits of improved accuracy in low-data scenarios and significant parameter efficiency (e.g., 76% reduction) demonstrate that quantum fine-tuning is not merely a performance boost but a strategic enabler for specialized LLM applications where data is scarce, expensive to label, or privacy-sensitive. Classical fine-tuning often struggles with generalization and can overfit in low-data scenarios, requiring substantial computational resources even with smaller datasets. Quantum layers, however, capture non-local correlations and leverage superposition and entanglement to explore broader solution spaces with fewer parameters. The ability of quantum circuits to encode and process information in high-dimensional Hilbert spaces, combined with parameter-efficient techniques, allows them to extract more meaningful patterns from smaller datasets. This directly leads to higher accuracy and reduced computational cost compared to classical methods that would either overfit or require massive data augmentation in such scenarios. This positions quantum fine-tuning as a compelling solution for highly specialized LLM applications in fields like medicine (patient history), chemistry (molecular properties), finance (fraud detection), and legal reasoning, where data is inherently limited or sensitive. It suggests a future where high-performance, specialized LLMs can be developed without the prohibitive data and compute costs associated with traditional large-scale training.
Table 1: Performance Comparison: Classical vs. Quantum-Enhanced LLM Fine-Tuning

3. Architectural Design and Optimization for Hybrid Quantum-Classical LLMs
The effective integration of quantum computing with LLMs necessitates a carefully designed hybrid architecture and sophisticated optimization strategies to maximize performance within current hardware constraints.
Hybrid Architectures
The foundational concept for quantum-enhanced LLM fine-tuning is a hybrid quantum-classical deep learning architecture. In this design, the classical portion of the architecture, often a sentence transformer, handles tasks like sentence embedding and other heavy preprocessing, leveraging its efficiency for dense linear algebra on massive data. The classical component then passes condensed features to a smaller quantum circuit, which performs pattern recognition in a high-dimensional Hilbert space. Specifically, this often involves replacing the final classification head of a classical model with a parameterized quantum circuit (PQC) to enhance classification accuracy. IonQ’s research, for example, introduced such a hybrid quantum-classical architecture to enhance LLM fine-tuning by supplementing a pre-trained LLM with a small, task-specific training dataset via Quantum Machine Learning (QML). More advanced approaches, like Quantum Tensor Hybrid Adaptation (QTHA), integrate a Quantum Neural Network (QNN) with a tensor network, decomposing pre-trained weights into QNN and tensor network representations to achieve parameter-efficient fine-tuning.
Quantum Neural Networks (QNNs) and Tensor Networks
Quantum Neural Networks (QNNs) are modeled after classical neural networks but utilize qubits, holding the promise of revealing more profound linguistic patterns and subtleties in language data. QNNs leverage the dynamic properties of quantum entanglement and superposition to achieve highly nonlinear feature modeling capabilities. In these hybrid frameworks, tensor networks, such as the Matrix Product Operator (MPO), are employed to efficiently extract abrupt features, while QNNs focus on effectively learning periodic features. This synergistic combination aims to overcome the limitations of classical linear layers in feature learning and achieve optimal allocation of computational resources. The QTHA framework, for instance, synergistically combines the expressive power of QNNs with the efficiency of tensor networks to achieve Parameter-Efficient Fine-Tuning (PEFT).
The architectural shift from classical classification heads to quantum layers or QNNs represents a fundamental transition towards models capable of handling non-linear, high-dimensional data relationships that are beyond the reach of classical linear layers. Classical networks, particularly their final classification layers, often rely on linear or simple non-linear transformations. While powerful, these can struggle to capture complex, non-local, or high-rank correlations in data, especially when data is limited or subtle. Quantum circuits, through superposition and entanglement, can naturally explore high-dimensional Hilbert spaces and represent complex, non-linear functions that are computationally challenging to simulate classically. QNNs specifically leverage these properties for finer-grained feature selection and optimal allocation of computational resources. By embedding data into a quantum state and applying quantum gates, the model can implicitly perform highly complex, non-linear transformations and feature mappings that would be computationally prohibitive or impossible for classical linear layers. This allows the hybrid model to learn more intricate patterns and improve classification accuracy, particularly for data with complex, non-obvious correlations. This architectural choice fundamentally enhances the model's ability to discern subtle relationships in data, making it suitable for tasks like nuanced sentiment analysis, complex drug discovery (molecular properties), or financial fraud detection where hidden, non-linear patterns are crucial for performance. It indicates that quantum components are being used as specialized accelerators for specific, quantum-advantageous sub-tasks within the larger LLM workflow.
Data Encoding and Feature Mapping
Quantum feature maps are a critical component for encoding classical data into quantum states, thereby leveraging the expressive power of high-dimensional Hilbert spaces. Quantum-inspired data embeddings, founded on the principles of superposition and entanglement, redefine data representation by enabling more intricate and expressive embeddings. Various encoding schemes exist, each suited to different data types and computational needs. These include Angle Encoding, which is robust on noisy hardware; Basis Encoding, effective for categorical data; Amplitude Encoding, which is memory-efficient but demands significant state preparation; and Hamiltonian Evolution, which excels in graph machine learning and chemistry applications. A crucial design consideration is to match the encoding scheme to the data structure; for instance, time-series data might benefit from angle encoding, while molecular data could leverage Hamiltonian encoding.
Optimization Strategies for Hybrid Workloads
Efficient computation in hybrid quantum-classical algorithms necessitates sophisticated optimization, especially given the resource constraints of current quantum computers. Optimization routines, adapted from classical methods, are applied to both the classical and quantum components of the code. These include Constant Propagation, which identifies and substitutes constant values; Live-Variable Analysis, which determines which variables are still in use; Constant Folding, which evaluates constant expressions at compile time; and Dead Code Elimination, which removes unreachable or irrelevant code.
Instruction Reordering is another vital strategy, designed to maximize the parallel execution of the Central Processing Unit (CPU) and Quantum Processing Unit (QPU), thereby minimizing idle time for either device. The "Latest Possible Quantum Execution" method aims to minimize the total execution time of the quantum device by executing as many classical instructions as possible before the QPU begins its operations.
To evaluate the effectiveness of these optimizations, specific metrics are employed: Wall Time, which measures the total program execution time; Quantum Instruction Number (QIN), aimed at minimizing errors introduced by quantum gates on noisy intermediate-scale quantum (NISQ) devices; and Quantum Calculation Time (QCT), which minimizes the duration for which the QPU must maintain qubit coherence.
The explicit focus on optimizing hybrid quantum-classical code, including instruction reordering and specialized metrics like QIN and QCT, underscores that current quantum hardware limitations (the NISQ era) make efficient orchestration of classical and quantum components paramount for achieving any practical advantage. Current quantum processors are "significantly resource-constrained," "noisy," and offer "limited and costly access". They cannot host deep quantum neural networks due to noise. The inherent limitations of NISQ devices (noise, limited qubits, short coherence times) mean that simply offloading a task to a QPU is insufficient. Without sophisticated hybrid optimization, the overheads of classical-quantum communication, qubit decoherence during idle times, and gate errors would negate any potential quantum speedup or accuracy gain. Optimizing for metrics like QIN (minimizing noisy gates) and QCT (minimizing coherence time) directly addresses these hardware frailties, making practical execution feasible. Instruction reordering ensures that the slower quantum component is not waiting unnecessarily for the faster classical component, maximizing throughput. This implies that the "quantum advantage" in the near term is not a standalone quantum phenomenon but a result of highly intelligent co-design and optimization between classical and quantum systems. It highlights the engineering challenge as much as the quantum physics challenge, emphasizing the need for specialized compilers and workflow managers for hybrid computation to unlock utility in the NISQ era.
4. Leveraging Cloud Platforms for Quantum LLM Fine-Tuning
The burgeoning field of quantum-enhanced LLM fine-tuning is significantly propelled by the accessibility offered through cloud computing platforms. The Quantum-as-a-Service (QaaS) model is central to this accessibility, democratizing the use of advanced quantum technologies.
Quantum-as-a-Service (QaaS) Model
QaaS, often referred to as Quantum-Computing-as-a-Service (QCaaS), operates on a model similar to other "as-a-Service" offerings (e.g., SaaS, PaaS, IaaS), providing quantum technologies, services, and solutions via cloud-based platforms, typically through subscriptions or pay-as-you-go arrangements. This model offers several distinct advantages, including lower barriers to entry for organizations and researchers who may lack the resources or expertise to develop quantum technologies in-house. It promotes cost-efficiency, enables rapid experimentation, and facilitates scalability, while also providing access to expert support communities. Furthermore, QaaS allows organizations to begin developing quantum algorithms and applications immediately, making future migration easier as quantum hardware matures. Cloud-based quantum computing services, such as Amazon Braket and Google's Quantum AI, are becoming viable options for organizations that do not possess their own on-premises quantum computers.
Major Cloud Provider Offerings
Leading cloud providers are actively integrating quantum computing capabilities into their platforms, offering diverse services relevant to quantum LLM fine-tuning:
AWS (Amazon Braket, SageMaker integration): Amazon Braket provides access to a variety of quantum hardware, including superconducting, trapped-ion, and neutral atom devices from providers like IonQ, Rigetti, IQM, and QuEra, alongside robust circuit simulators. It offers a consistent set of development tools, transparent pricing, and comprehensive management controls for both quantum and classical workloads. Braket enables faster execution of hybrid quantum-classical algorithms by offering priority access to quantum computers and eliminating the need for users to manage classical infrastructure. The integration with Amazon SageMaker Experiments allows users to track and manage hybrid quantum-classical experiments, facilitating organization, logging, comparison, and reproduction of results. While specific quantum LLM fine-tuning details on Braket are not explicitly detailed, its support for hybrid jobs and integration with SageMaker, a widely used machine learning platform, indicates a clear pathway for such applications. IonQ's quantum hardware, for instance, is directly accessible via Amazon Braket.
IBM Quantum (IBM Quantum Platform, Qiskit): IBM has long been a pioneer in quantum computing, making its quantum resources accessible through the IBM Quantum Experience cloud platform. The IBM Quantum Platform is dedicated to building scalable quantum systems and advancing quantum software and algorithms. Qiskit, an open-source Python library, provides fundamental computational building blocks for quantum machine learning (QML), including Quantum Kernels and Quantum Neural Networks (QNNs). Qiskit ML is specifically designed to handle quantum hardware workloads and seamlessly integrates with classical machine learning frameworks such as PyTorch and scikit-learn. Additionally, IBM's Data Prep Kit (DPK), an open-source toolkit, streamlines data preprocessing for LLMs, encompassing critical steps like PDF conversion to Parquet, identification of Personally Identifiable Information (PII) and hate/abuse/profanity (HAP) content, data deduplication, document chunking, and quality assessment, all of which are essential for effective quantum LLM fine-tuning.
Google Cloud (Quantum AI, Cirq, Vertex AI): Google Quantum AI focuses on advancing quantum algorithms and hardware, notably recognized for its Sycamore processor. Google Cloud provides Quantum AI services, enabling users to run quantum computing programs on Google's quantum processors using Cirq, an open-source Python framework. Google's Vertex AI platform supports fine-tuning LLMs with domain-specific datasets and offers techniques such as embedding-based retrieval and Retrieval-Augmented Generation (RAG). While direct quantum integration with Vertex AI for LLM fine-tuning is not explicitly detailed, the platform's robust support for LLM fine-tuning and Google's significant investments in quantum research suggest a future convergence of these capabilities.
Microsoft Azure (Azure Quantum, Azure AI Foundry): Microsoft Quantum is actively developing scalable and stable quantum computers, offering its Quantum Development Kit and the Azure Quantum cloud platform. Azure Quantum provides a powerful synergy between Azure's high-performance computing, AI capabilities, and the transformative potential of quantum technologies. Azure AI Foundry offers advanced enhancements for LLM fine-tuning, including Reinforcement Fine-Tuning (RFT) and Supervised Fine-Tuning (SFT) for various models. This platform has been utilized for fine-tuning on proprietary legal data to improve response accuracy, as demonstrated by companies like DraftWise. Although specific quantum LLM fine-tuning offerings are not yet detailed for Azure Quantum, its deep integration with Azure AI Foundry and a strategic focus on hybrid quantum-classical AI research indicate a clear direction for future developments.
D-Wave Systems: D-Wave is recognized for its pioneering work in quantum annealing technology, which is particularly effective for solving optimization problems. Their Advantage quantum computer is accessible via the cloud, allowing businesses to leverage quantum computing power for various applications. A notable case study involves D-Wave's Leap™ quantum cloud service, which was used by Japan Tobacco to enhance LLMs for drug discovery. This quantum-hybrid approach demonstrably outperformed classical methods in generating novel, more "drug-like" molecular structures. This example directly illustrates the utilization of cloud resources for quantum-hybrid LLM training.
The widespread availability of Quantum-as-a-Service (QaaS) offerings from major cloud providers signifies a critical shift from exclusive, on-premise quantum hardware to a more democratized, accessible model. Owning and maintaining quantum computers is prohibitively expensive and requires specialized infrastructure, such as cryogenic cooling and advanced error correction systems. This creates a significant barrier to entry for most organizations. Cloud providers, by offering QaaS, abstract away the complexities and costs of quantum hardware ownership. This on-demand access to powerful, albeit nascent, quantum processing units (QPUs), coupled with existing cloud machine learning platforms (like SageMaker, Vertex AI, Azure AI Foundry), enables the development and fine-tuning of quantum-enhanced LLMs without the need for in-house quantum expertise or infrastructure. This significantly accelerates research and adoption. This model is particularly crucial for the "NISQ era," where quantum hardware is still noisy and limited. It fosters innovation by allowing a wider range of developers and organizations to experiment with hybrid quantum-classical solutions, potentially leading to unforeseen breakthroughs and faster commercialization of quantum AI. It also positions cloud providers as central facilitators in the evolving quantum computing ecosystem.
Table 2: Cloud Quantum Computing Services for LLM Fine-Tuning


5. Practical Implementation: Tips & Tricks
Implementing quantum-enhanced LLM fine-tuning effectively requires attention to several practical aspects, from data preparation to workflow management, to maximize the benefits of this emerging technology.
Data Preparation for QNLP
Preprocessing is fundamental for transforming unstructured text data, such as legal contracts, into a structured format suitable for model training. Common preprocessing techniques include tokenization, which breaks down text into individual words or phrases ; stemming and lemmatization, which reduce words to their root or base forms; and stop-word removal, which eliminates common words that carry little meaning. Part-of-Speech (POS) tagging can further identify the grammatical role of each word, aiding in the extraction of meaningful information. A significant challenge in NLP is handling unknown words (Out-Of-Vocabulary, OOV); a common strategy is to replace rare words in the training data with a special UNK token and learn its representation.
For quantum-specific data encoding, word embeddings can be computed directly as parameterized quantum circuits. Instead of loading classical word vectors onto quantum memory, the parameters of quantum circuits are optimized to represent these embeddings. The development of large, high-quality datasets specific to quantum computing is crucial for LLMs to grasp the intricacies of this domain. QuantumLLMInstruct (QLMMI), for instance, is a groundbreaking dataset comprising over 500,000 problem-solution pairs related to quantum computing, designed to help LLMs understand quantum algorithms and circuit design. Tools like IBM's Data Prep Kit (DPK), an open-source toolkit, streamline preprocessing for LLMs, offering functionalities like converting PDFs to Parquet, identifying PII/HAP content, deduplication, chunking, and assessing document quality. A practical recommendation is to implement rigorous data curation, cleaning, and augmentation processes. This is crucial to mitigate issues arising from low-quality or biased data, which can degrade model performance and amplify biases.
Parameter-Efficient Fine-Tuning (PEFT) Methods
Parameter-Efficient Fine-Tuning (PEFT) methods are vital for reducing the number of trainable parameters, which in turn decreases computational demands and helps mitigate "catastrophic forgetting"—the phenomenon where an LLM loses previously learned core knowledge when exposed to new data. Widely used classical PEFT techniques include Low-Rank Adaptation (LoRA) and Adapters. Quantum-enhanced PEFT methods, such as Quantum Tensor Hybrid Adaptation (QTHA) and Quantum Weighted Tensor Hybrid Network (QWTHN), integrate Quantum Neural Networks (QNNs) with tensor networks. These methods have demonstrated remarkable efficiency, significantly reducing trainable parameters (by 76% compared to LoRA) while simultaneously improving performance. For practical application, exploring the quantum-llm and pyvqnet packages is advisable, as they offer vqc, quanTA, and tq fine-tuning methods for quantum macromodel fine-tuning. The VQNet-based vqc module, in particular, has shown superior loss convergence in training results.
Circuit Optimization
Optimizing quantum circuits is an active and complex field of research, often involving NP-hard problems like T-count optimization and parameter optimization. Studies have shown that classification accuracy can increase with the number of qubits, but there exists a "sweet spot" for circuit depth: circuits that are too shallow may lack expressivity, while those that are overly deep can become difficult to train. Optimization techniques include reducing gate count, applying pattern matching, and utilizing genetic programming. Interestingly, LLMs can be fine-tuned to automatically generate quantum circuits for optimization problems, producing syntactically correct and high-quality parameterized quantum circuits. A key recommendation for designing quantum circuits for LLM fine-tuning is to carefully balance the qubit count and circuit depth. Continuous monitoring of performance is essential to identify the "sweet spot" where expressivity is maximized without making the circuit excessively complex or challenging to train, especially when working with Noisy Intermediate-Scale Quantum (NISQ) devices.
Error Mitigation Techniques
Current quantum hardware is susceptible to noise, decoherence, and errors, which fundamentally limit the size, fidelity, and duration of quantum computations. IonQ, for example, offers error mitigation techniques like "Debiasing" to improve computational quality and accuracy, leveraging their systems' long coherence times and low gate error rates. Furthermore, artificial intelligence can play a crucial role in enhancing the reliability of quantum systems, reducing errors and fine-tuning performance. Deep learning models, in particular, can be employed to predict and correct errors in quantum computations, thereby accelerating quantum algorithms. A practical recommendation is to implement error mitigation techniques provided by quantum hardware vendors (e.g., IonQ's Debiasing on Amazon Braket) and to explore AI-driven error correction methods. These approaches are critical for enhancing the reliability and accuracy of quantum fine-tuning, especially when operating with NISQ devices.
Hybrid Workflow Management
Hybrid models are designed to combine the strengths of classical and quantum components. Classical layers are adept at handling dense linear algebra on massive datasets and then pass condensed features to a smaller quantum circuit for specialized processing. The training loop for such systems typically involves a classical forward pass, followed by quantum circuit execution, loss computation on the CPU or GPU, and subsequent gradient updates. The integration of quantum resources into existing High-Performance Computing (HPC) infrastructure is crucial for widespread adoption, enabling unified scheduling and robust support for hybrid applications. A key recommendation is to design workflows where classical components manage data preprocessing and large-scale neural network training, while quantum components are strategically utilized for specific, computationally intensive sub-tasks such as complex pattern recognition or optimization. Leveraging cloud platforms that offer integrated hybrid job management and resource scheduling capabilities is also highly beneficial.
The emphasis on Parameter-Efficient Fine-Tuning (PEFT), circuit optimization, error mitigation, and the strategic use of hybrid workflows reveals a pragmatic, iterative approach to achieving quantum advantage in LLMs. The current limitations of NISQ devices (noise, limited qubits, short coherence times) mean that fully quantum LLMs are not yet feasible. Given these constraints, the path to practical quantum LLM fine-tuning is necessarily hybrid and highly optimized. PEFT methods are essential to reduce the quantum resources needed. Circuit optimization and error mitigation directly address the noise and coherence challenges inherent in current quantum hardware. Hybrid workflow management ensures efficient allocation and communication between classical and quantum parts, making the most of limited QPU time. These "tricks" are not simply enhancements; they are enablers for any meaningful quantum integration in the near term. This suggests that current "quantum advantage" is often a "hybrid advantage" achieved through sophisticated engineering and algorithmic design that carefully allocates tasks to the most suitable computational paradigm—classical for bulk processing and quantum for specific, hard-to-simulate sub-problems. This approach implies that successful implementation requires a deep understanding of both classical machine learning and quantum computing, along with the ability to orchestrate them effectively.
6. Challenges and Mitigation Strategies
While quantum-enhanced LLM fine-tuning presents significant opportunities, its development and deployment are accompanied by substantial challenges that necessitate targeted mitigation strategies.
Hardware Limitations
Current quantum devices face considerable limitations in terms of qubit count, gate fidelity, and coherence times. Consequently, training a large-scale LLM entirely on a quantum computer is currently "nowhere near feasible with today's hardware". The quality and quantity of qubits remain major hurdles in advancing quantum computing capabilities. To mitigate these limitations, the focus is on developing hybrid models that strategically leverage quantum capabilities where they offer the most value, rather than attempting to replace classical systems entirely. Continued research and development efforts are crucial for building more scalable and robust quantum systems.
Quantum Noise and Decoherence
Quantum hardware is inherently susceptible to noise, decoherence, and errors, which constrain the size, fidelity, and duration of quantum computations. Noise can arise from various environmental interferences, leading to the corruption of qubit states and information loss.
Error Correction: While fault-tolerant devices aim to employ error correction schemes, these are challenging to implement and can, in some cases, introduce new sources of errors. Achieving true fault-tolerant quantum computing remains an active area of research.
Error Mitigation Techniques: Practical approaches involve implementing software-based error mitigation techniques, such as IonQ's "Debiasing," which can counter and eliminate certain types of errors.
AI for Error Correction: Artificial intelligence can significantly contribute to making quantum systems more reliable by improving error detection and correction mechanisms, leading to more reliable performance and enabling longer, more complex computations. Deep learning models, for instance, can be trained to predict and correct errors in quantum computations, thereby accelerating quantum algorithms.
Computational Overhead and Data Loading Bottlenecks
Training LLMs is a resource-intensive and time-consuming process on classical hardware, involving the processing of vast datasets and the adjustment of billions of parameters. The "von Neumann bottleneck," a fundamental limitation in classical computer architecture where memory and processing units are separate, causes significant lag as data moves slower than computation. This results in high energy costs and increased latency, particularly for large models. In the quantum domain, amplitude encoding, a method for encoding classical data into quantum states, currently presents a data loading bottleneck.
Parameter-Efficient Fine-Tuning (PEFT): Methods like QTHA and QWTHN offer a significant mitigation strategy by substantially reducing the number of trainable parameters. This enhances model trainability and has the potential to lower computational costs.
Hybrid Architectures: Strategically deploying quantum resources to augment key parts of existing classical workflows can leverage quantum computing's ability to process high-dimensional data spaces, thereby reducing overall computational time.
Quantum-Inspired Algorithms: Research into "quantum-inspired" linear algebra methods, such as random projection and approximate matrix factorization, is already yielding benefits for classical High-Performance Computing (HPC).
Complexity of Algorithm Development and Integration
Developing AI algorithms compatible with quantum hardware is inherently complex and demands specialized expertise. Combining performance features to ensure effective algorithm operation presents a significant challenge. Furthermore, designing and implementing a quantum-based LLM pipeline is "extremely non-trivial" due to the evolving nature of tools, frameworks, and mental models in this nascent field.
Cloud-based QaaS Platforms: These platforms offer Software Development Kits (SDKs) and tools that simplify development and integration, lowering the barrier to entry.
Collaboration and Community Support: Open-source frameworks and communities, such as Qiskit and PennyLane, are crucial for fostering collaboration and sharing knowledge.
Talent Development: Investing in strategic skilling and training for a "quantum-ready" workforce is essential to navigate the evolving landscape effectively.
Overfitting and Catastrophic Forgetting
Overfitting, where a model excessively memorizes training examples and fails to generalize to unseen data, is a persistent problem in LLM fine-tuning. Catastrophic forgetting occurs when an LLM loses previously learned language capabilities upon being fine-tuned on new data.
PEFT Methods: Employing PEFT techniques helps to reduce trainable parameters, which in turn mitigates both overfitting and catastrophic forgetting.
Regularization Techniques: Applying regularization techniques like dropout or weight decay can help prevent overfitting.
Cross-validation: Utilizing cross-validation for hyperparameter tuning is a standard practice to optimize performance and generalization.
Quantum Tensor Networks: These networks can emphasize local correlations within input signals, which helps prevent the training process from becoming trapped in suboptimal local minima.
Barren Plateaus
A significant challenge in training quantum models is the phenomenon of barren plateaus, which manifest as a flat loss landscape where gradient variance vanishes exponentially as the number of qubits increases. This severely impedes the effectiveness of optimization techniques.
LLM-driven Search Frameworks: Novel approaches, such as LLM-driven search frameworks like AdaInit, iteratively search for optimal initial parameters of QNNs to maximize gradient variance and thereby mitigate barren plateaus.
The extensive list of challenges, particularly hardware limitations, noise, and barren plateaus, serves as a crucial assessment of the current state of quantum LLMs. It highlights that while the potential is immense, the technology is still in a foundational research phase, requiring sophisticated mitigation strategies to extract any practical value. The fundamental physical limitations of current quantum hardware, such as decoherence causing noise, limited qubit connectivity, and difficulties in scaling, directly lead to computational challenges like barren plateaus, which make training difficult, and data loading bottlenecks due to the classical-quantum interface. These challenges necessitate complex mitigation strategies, including error correction, PEFT, and hybrid optimization, which add overhead and complexity. This prevents immediate, widespread "quantum advantage" for general LLM tasks. This indicates that the practical advice and strategies are often about navigating these fundamental limitations rather than simply optimizing an already mature technology. It also implies that true transformative impact is still years away, contingent on significant breakthroughs in quantum hardware and error correction.
7. Current Landscape: Case Studies and Leading Research
The current landscape of quantum LLM fine-tuning is characterized by promising real-world applications and significant research efforts from leading institutions and companies.
Real-World Applications
Quantum-enhanced LLM fine-tuning is demonstrating its value across several key domains:
Sentiment Analysis: Hybrid quantum-classical models fine-tuned for sentiment analysis tasks, such as the Stanford Sentiment Treebank (SST-2), have consistently shown higher accuracy than classical methods, particularly in low-data regimes. This highlights quantum computing's ability to extract more nuanced patterns from limited data.
Drug Discovery: A notable collaboration between D-Wave and Japan Tobacco utilized a quantum-hybrid workflow to enhance LLMs for generating novel, more "drug-like" molecular structures. This approach demonstrably outperformed classical methods, indicating quantum computing's potential to accelerate drug discovery by improving molecule identification and chemical reaction simulations.
Financial Modeling: Quantum models offer the capability to analyze high-dimensional datasets more efficiently using fewer parameters, making them ideal for complex financial tasks such as fraud detection, portfolio optimization, and risk assessment.
Code Generation: LLMs are being fine-tuned to automatically generate quantum circuits for optimization problems, producing syntactically correct and high-quality parameterized quantum circuits. Datasets comprising PennyLane-specific code samples are being curated to train and fine-tune LLMs for quantum code assistance, bridging the gap between natural language instructions and quantum programming.
Materials Science: Quantum-enhanced Generative Adversarial Networks (QGANs) are being developed to optimize materials science properties. These systems can generate synthetic images of rare anomalies and have achieved higher quality scores than classical GANs, addressing the scarcity of high-quality, domain-specific datasets in industrial AI.
Personalization and Privacy: Fine-tuning techniques can be used to encapsulate individual patient health histories or adapt models for company-specific industrial applications where privacy and sensitive data are critical considerations. Quantum cryptography further enhances data security in these sensitive domains.
The recurring themes in these case studies—sentiment analysis in low-data regimes, drug discovery, materials science, and financial modeling—indicate that quantum LLM fine-tuning is currently most impactful in domains characterized by complex, high-dimensional data where classical methods struggle, or where data is sparse. These are the "sweet spots" for early quantum advantage, rather than general-purpose language tasks. What unites these diverse applications is their involvement in either: a) "complex data correlations" and "low-data regimes" (e.g., sentiment analysis, medical, industrial personalization) ; b) computationally intensive optimization or simulation of complex systems (e.g., drug discovery, materials science, financial modeling) ; or c) the generation of complex, structured data (e.g., quantum circuits). Quantum computing's strengths, such as superposition, entanglement, and the ability to explore vast solution spaces and handle non-local correlations, are uniquely suited to these types of problems, where classical methods often encounter computational or expressivity bottlenecks. Therefore, the "quantum advantage" is being realized where quantum mechanics provides a fundamentally different way to process information that aligns with the inherent complexity or data scarcity of the problem. This suggests a strategic roadmap for quantum LLM adoption: instead of attempting to apply quantum to all LLM tasks, efforts are concentrated on niche, high-value problems where quantum offers a distinct, measurable improvement over classical methods. This also implies that the "quantum LLM" is not a monolithic entity but a specialized tool integrated into existing workflows for specific, hard-to-solve tasks.
Key Research Institutions and Companies
Major players are actively driving research and development in quantum LLM fine-tuning:
IonQ: A prominent commercial quantum computing company specializing in trapped-ion quantum computing, IonQ has demonstrated quantum-enhanced applications in LLM fine-tuning and materials science. Their quantum technology is accessible via all major public clouds, facilitating broader adoption.
D-Wave Systems: Known for its quantum annealing technology, D-Wave provides cloud-based solutions and has successfully demonstrated quantum-hybrid LLM training for drug discovery.
IBM Quantum: A trailblazer in the field, IBM Quantum focuses on building scalable quantum systems and developing quantum software through its IBM Quantum Experience and Qiskit platforms.
Google Quantum AI: Renowned for achieving quantum supremacy with the Sycamore processor, Google Quantum AI is actively advancing quantum algorithms and hardware.
Microsoft Quantum: Microsoft is engaged in research on topological qubits and offers the Azure Quantum cloud platform for quantum experimentation.
SECQAI: This company recently launched what it claims to be the world's first Quantum Large Language Model (QLLM), with a focus on developing a quantum attention mechanism integrated within existing LLM models.
IQM Quantum Computers: IQM is developing next-generation quantum processors and exploring real-life use cases for machine learning applications.
Quantinuum: This company is actively working on Generative Quantum AI to optimize machine learning techniques specifically for Natural Language Processing (NLP) using quantum computers.
8. Future Outlook and Roadmap
The trajectory of quantum LLM fine-tuning is closely tied to the advancements in quantum hardware and the continued development of hybrid quantum-classical architectures.
Projections for Quantum Advantage
Analyses from leading firms like BCG predict a broad quantum advantage emerging in the early 2030s. Breakthroughs in Quantum AI are anticipated by the late 2020s or early 2030s, coinciding with the projected availability of error-corrected quantum computers featuring tens to hundreds of logical qubits. However, the full implementation of quantum computing across various sectors, including automation, energy, computer security, and complex chemistry/drug design, may extend beyond a decade. Notably, Hyperion Research projects that 18% of quantum algorithm revenue will be derived from AI applications by as early as 2026.
Roadmaps for Fault-Tolerant Quantum Computers
Major players in the quantum computing space have outlined ambitious roadmaps toward achieving fault-tolerant quantum computers:
Google: Google's roadmap aims to unlock the full potential of quantum computing by developing a large-scale, error-corrected quantum computer. Key milestones include building a long-lived logical qubit (requiring 10^3 physical qubits and targeting a 10^-6 logical error rate) and creating a logical gate. These steps are intended to lead to engineering scale-up (100 logical qubits) and ultimately a large error-corrected quantum computer with 1 million physical qubits.
IBM: IBM has unveiled a clear path to construct IBM Quantum Starling, which is anticipated to be the world's first large-scale, fault-tolerant quantum computer, with delivery projected by 2029. Starling is designed to perform 20,000 times more operations than current quantum computers, utilizing 200 logical qubits to execute 100 million quantum operations. This system is intended to lay the foundation for IBM Quantum Blue Jay, which will be capable of executing 1 billion quantum operations over 2,000 logical qubits.
Quantum Art: This developer targets scalable commercial quantum advantage by 2027, aiming for 1,000 qubits and 100 logical qubits. Their long-term roadmap includes a 1 million physical qubit system by 2033.
The Role of Hybrid Models in the Near and Long Term
Despite the ambitious roadmaps for fault-tolerant quantum computers, hybrid quantum-classical systems are expected to dominate the early stages of Quantum Machine Learning (QML) adoption. These hybrid approaches will complement classical methods rather than entirely replacing them. They serve as the pragmatic bridge between the current classical AI dominance and the future era of fault-tolerant quantum deep learning. Hybrid models will continue to be strategically integrated into classical AI workflows, leveraging increased expressivity to enhance traditional AI LLMs, particularly in rare-data regimes where classical models struggle.
The roadmaps from major players clearly indicate that fault-tolerant quantum computers, with millions of physical qubits and hundreds/thousands of logical qubits, are still a decade away. This reinforces the necessity and longevity of the hybrid quantum-classical approach as the primary means to achieve practical quantum advantage for LLMs in the interim. The current limitations of NISQ devices, including noise, limited qubits, and short coherence times, mean that fully quantum LLMs are not yet feasible. Therefore, the industry is focusing on hybrid architectures that strategically integrate quantum components for specific, advantageous sub-tasks. This hybrid approach allows for incremental gains and practical applications today, while simultaneously driving the development of the underlying fault-tolerant hardware needed for more ambitious quantum AI in the future. The hybrid model serves as a necessary stepping stone, mitigating current hardware deficiencies while allowing for continued progress and exploration of quantum utility. This implies that organizations should invest in hybrid quantum-classical expertise and infrastructure now, as this paradigm will be dominant for the foreseeable future. It also suggests that a "quantum-ready" strategy is not merely about preparing for a distant future but about actively engaging with hybrid solutions to gain a competitive advantage in the present decade. The long-term vision for quantum LLMs is intrinsically tied to the maturation of fault-tolerant hardware, but the immediate future is firmly rooted in hybrid approaches.
Anticipated Breakthroughs and Industry-Wide Adoption Trends
Quantum computing holds the potential to significantly increase the total supply of usable data by enabling access to vast, underutilized oceans of unstructured data. Quantum-enhanced language models are expected to drive better customer interactions, more accurate predictions, and enhanced decision-making processes across various industries, including healthcare, finance, and e-commerce. The future of AI is anticipated to be quantum-enhanced, leading to unprecedented innovation and efficiency across numerous sectors.
9. Conclusion and Recommendations
Summary of Key Findings and Transformative Potential
Quantum-enhanced LLM fine-tuning, primarily realized through hybrid quantum-classical architectures, presents significant advantages in terms of improved accuracy, enhanced parameter efficiency, and accelerated training speeds. These benefits are particularly pronounced in low-data regimes and for tasks that involve complex data correlations, where classical methods often encounter limitations. Cloud platforms, operating on a Quantum-as-a-Service (QaaS) model, are playing a pivotal role in democratizing access to quantum computing resources. This accessibility enables broader experimentation and accelerates the development of advanced quantum-enhanced LLM applications by mitigating the need for substantial upfront infrastructure investments. While the field continues to grapple with inherent challenges such as hardware limitations, quantum noise, and the complexities of integration, ongoing research and the development of sophisticated mitigation strategies are progressively paving the way for practical applications in highly specialized domains.
Recommendations for Organizations and Researchers
Based on the current state of quantum LLM fine-tuning and its projected trajectory, the following recommendations are provided for organizations and researchers:
Prioritize Hybrid Approaches: Organizations should strategically focus on integrating quantum components into existing classical LLM workflows. This approach is most effective for specific, high-value tasks where quantum computing offers a clear advantage, such as complex pattern recognition in sparse datasets or solving intricate optimization problems.
Leverage Cloud QaaS: To access cutting-edge quantum hardware and software without prohibitive upfront capital expenditure, it is advisable to utilize cloud-based quantum computing services. Platforms like Amazon Braket, IBM Quantum, Google Cloud Quantum AI, Azure Quantum, and D-Wave Leap offer diverse resources. Exploring their respective SDKs (e.g., Qiskit, PennyLane, Cirq) and their integration capabilities with established classical machine learning platforms (e.g., Amazon SageMaker, Google Vertex AI, Azure AI Foundry) is crucial.
Invest in Data Quality and Preparation: Robust data preprocessing pipelines are paramount. Organizations should invest in rigorous data curation, cleaning, and augmentation. Furthermore, exploring quantum-specific data encoding techniques and leveraging specialized datasets, such as QLMMI, can significantly maximize the benefits derived from quantum fine-tuning.
Adopt Parameter-Efficient Methods: Implementing Parameter-Efficient Fine-Tuning (PEFT) techniques is essential. Quantum-enhanced PEFT methods, such as QTHA and QWTHN, are particularly effective in reducing computational overhead, mitigating overfitting, and improving overall training efficiency.
Embrace Error Mitigation: Given the inherent noise in current quantum devices, actively applying error mitigation techniques provided by quantum hardware vendors (e.g., IonQ's Debiasing on Braket) is critical. Additionally, exploring and integrating AI-driven error correction methods can further enhance the reliability and accuracy of quantum computations on noisy hardware.
Cultivate Quantum-Ready Talent: Investing in comprehensive training and upskilling programs for teams is vital. Developing expertise in both quantum computing fundamentals and hybrid algorithm development will enable organizations to navigate the evolving landscape effectively and capitalize on emerging opportunities.
Monitor Roadmaps and Research: Continuously staying abreast of advancements in fault-tolerant quantum computing and new quantum AI breakthroughs is important. These developments will significantly expand the scope and impact of quantum LLM fine-tuning in the coming decade, informing strategic long-term planning.
Target Niche Applications: In the near term, efforts should be concentrated on identifying and targeting use cases in specialized domains. Fields such as drug discovery, materials science, financial modeling, and nuanced NLP tasks are prime candidates where quantum computing's unique capabilities can provide a demonstrable competitive edge.
FAQ
1. What is quantum-enhanced LLM fine-tuning, and why is it significant?
Quantum-enhanced Large Language Model (LLM) fine-tuning involves integrating quantum computing principles and hardware with classical LLMs. LLM fine-tuning is the process of adapting a pre-trained LLM to a specific task or domain using a smaller, task-specific dataset, making it more efficient and cost-effective than training a new model from scratch. Quantum computing, unlike classical computing, uses qubits which can exist in multiple states simultaneously (superposition) and become intrinsically linked (entanglement), allowing for parallel processing of vast amounts of information.
The significance of this convergence lies in its potential to overcome limitations of classical LLMs, especially in scenarios with scarce data or complex data correlations. Quantum layers can capture non-local correlations in data more effectively, leading to improved accuracy, particularly when data is limited. It addresses the "expressive bottleneck" of classical methods like LoRA by allowing hybrid models to learn intricate, non-linear relationships that are intractable or inefficient for classical methods. This can unlock new applications in fields with complex, high-dimensional data, such as medicine, chemistry, finance, and legal reasoning, where data is inherently limited or sensitive, potentially reducing the prohibitive data and compute costs associated with traditional large-scale training.
2. What are the key benefits of using quantum computing for LLM fine-tuning?
The integration of quantum computing into LLM fine-tuning offers several compelling advantages:
Improved Accuracy: Hybrid quantum-classical models demonstrate superior classification accuracy compared to classical baselines, especially in low-data regimes. For instance, in sentiment analysis (SST-2), improvements of 3.14% to 14% have been reported, with a multi-encoder quantum setup achieving 92.7% accuracy even with limited data.
Parameter Efficiency and Reduced Computational Overhead: Quantum-enhanced Parameter-Efficient Fine-Tuning (PEFT) methods, like Quantum Tensor Hybrid Adaptation (QTHA), can significantly reduce trainable parameters (up to 76% compared to classical LoRA). This enhances trainability, accelerates convergence (by up to 20%), mitigates overfitting, and reduces computational costs.
Accelerated Training and Optimisation: Quantum computers can process multiple data points concurrently and perform complex matrix operations faster than classical systems, reducing training time for AI models and enabling the handling of larger, more complex datasets. They are also well-suited for computationally intensive optimisation problems.
Enhanced Natural Language Processing (NLP) Capabilities: Quantum Natural Language Processing (QNLP) can lead to more efficient processing of language structures and reveal profound linguistic patterns, improving accuracy in tasks like sentiment analysis, language translation, and context-aware understanding.
Improved Security and Privacy: Quantum cryptography, particularly quantum key distribution (QKD) protocols, provides unmatched security for safeguarding sensitive information, which is crucial for industries like healthcare, finance, and law.
These benefits collectively make quantum fine-tuning a strategic enabler for specialised LLM applications where data is scarce, expensive to label, or privacy-sensitive.
3. How are quantum and classical components integrated in hybrid LLM fine-tuning architectures?
Hybrid quantum-classical deep learning architectures are foundational for quantum-enhanced LLM fine-tuning. The design typically involves a classical portion of the architecture, such as a sentence transformer, which handles tasks like sentence embedding and heavy preprocessing. This classical component efficiently processes massive data and then passes condensed features to a smaller quantum circuit.
This quantum circuit, often a Parameterised Quantum Circuit (PQC) or a Quantum Neural Network (QNN), then performs pattern recognition in a high-dimensional Hilbert space. A common approach is to replace the final classical classification head with a PQC to enhance classification accuracy. More advanced methods, such as Quantum Tensor Hybrid Adaptation (QTHA), integrate QNNs with tensor networks, decomposing pre-trained weights to achieve parameter-efficient fine-tuning.
This architectural shift allows the hybrid model to handle non-linear, high-dimensional data relationships that classical linear layers struggle with, especially when data is limited or subtle. Quantum circuits, through superposition and entanglement, can implicitly perform highly complex transformations and feature mappings, enabling the model to learn intricate patterns and improve accuracy in tasks like nuanced sentiment analysis, drug discovery, or financial fraud detection where hidden, non-linear patterns are crucial. The training loop for such systems typically involves a classical forward pass, followed by quantum circuit execution, loss computation, and subsequent gradient updates.
4. What is Quantum-as-a-Service (QaaS), and why is it crucial for quantum LLM fine-tuning?
Quantum-as-a-Service (QaaS), also known as Quantum-Computing-as-a-Service (QCaaS), is a cloud-based model that provides access to quantum technologies, services, and solutions, typically through subscriptions or pay-as-you-go arrangements. It is crucial for quantum LLM fine-tuning because it democratises access to advanced quantum technologies.
Owning and maintaining quantum computers is prohibitively expensive, requiring specialised infrastructure like cryogenic cooling and advanced error correction systems, creating a significant barrier to entry for most organisations. QaaS abstracts away these complexities and costs, providing on-demand access to powerful, albeit nascent, quantum processing units (QPUs).
This model significantly accelerates research and adoption by lowering barriers to entry, promoting cost-efficiency, enabling rapid experimentation, and facilitating scalability. It allows organisations and researchers to immediately begin developing quantum algorithms and applications without substantial upfront infrastructure investments or in-house quantum expertise. Major cloud providers like AWS (Amazon Braket), IBM (IBM Quantum Platform), Google Cloud (Quantum AI), Microsoft Azure (Azure Quantum), and D-Wave Systems offer diverse QaaS services, integrating with existing cloud machine learning platforms, thereby fostering innovation in the noisy intermediate-scale quantum (NISQ) era.
5. What practical considerations are important for implementing quantum-enhanced LLM fine-tuning?
Practical implementation of quantum-enhanced LLM fine-tuning requires attention to several key areas:
Data Preparation for QNLP: Rigorous data curation, cleaning, and augmentation are crucial, along with preprocessing techniques like tokenisation, stemming, lemmatisation, and stop-word removal. For quantum-specific encoding, word embeddings can be directly computed as parameterized quantum circuits, and high-quality, quantum-specific datasets (e.g., QuantumLLMInstruct) are vital. Tools like IBM's Data Prep Kit streamline this.
Parameter-Efficient Fine-Tuning (PEFT) Methods: Employing PEFT methods is essential to reduce trainable parameters, decrease computational demands, and mitigate "catastrophic forgetting." Quantum-enhanced PEFT methods, such as QTHA, offer significant efficiency gains.
Circuit Optimisation: Balancing qubit count and circuit depth is critical to maximise expressivity without making the circuit excessively complex or challenging to train, especially on NISQ devices. Techniques include reducing gate count, pattern matching, and using LLMs to automatically generate optimal quantum circuits.
Error Mitigation Techniques: Current quantum hardware is susceptible to noise and errors. Implementing software-based error mitigation techniques provided by hardware vendors (e.g., IonQ's Debiasing) and exploring AI-driven error correction methods are crucial for enhancing reliability and accuracy.
Hybrid Workflow Management: Designing workflows where classical components manage data preprocessing and large-scale neural network training, while quantum components are strategically used for specific, computationally intensive sub-tasks (e.g., complex pattern recognition or optimisation), is paramount. Leveraging cloud platforms with integrated hybrid job management is highly beneficial.
These practical "tricks" are not just enhancements but enablers for any meaningful quantum integration in the near term, given the limitations of current quantum hardware.
6. What are the main challenges facing quantum LLM fine-tuning, and how are they being addressed?
Quantum LLM fine-tuning faces several significant challenges, primarily stemming from the nascent stage of quantum technology:
Hardware Limitations: Current quantum devices have limited qubit counts, gate fidelity, and coherence times, making it unfeasible to train large-scale LLMs entirely on quantum computers. Mitigation: The focus is on hybrid models that strategically leverage quantum capabilities for specific advantages, rather than replacing classical systems entirely.
Quantum Noise and Decoherence: Qubits are fragile and susceptible to environmental interference, leading to errors and information loss. Mitigation: Error mitigation techniques (e.g., IonQ's "Debiasing") are employed, and AI is increasingly used for error detection and correction. Fault-tolerant quantum computing is a long-term research goal.
Computational Overhead and Data Loading Bottlenecks: LLM training is resource-intensive classically, and quantum amplitude encoding presents a data loading bottleneck. Mitigation: Parameter-Efficient Fine-Tuning (PEFT) methods reduce trainable parameters, and hybrid architectures strategically deploy quantum resources to reduce overall computational time.
Complexity of Algorithm Development and Integration: Developing quantum-compatible AI algorithms is complex, and integrating quantum components into existing LLM pipelines is challenging due to evolving tools and frameworks. Mitigation: Cloud-based QaaS platforms offer SDKs to simplify development, open-source frameworks foster collaboration, and investment in "quantum-ready" talent is essential.
Overfitting and Catastrophic Forgetting: LLMs can overfit to training data or lose previously learned knowledge when fine-tuned. Mitigation: PEFT methods reduce trainable parameters, regularization techniques (dropout, weight decay) prevent overfitting, and quantum tensor networks can help.
Barren Plateaus: A phenomenon in quantum models where the loss landscape becomes flat, impeding optimisation as qubit count increases. Mitigation: Novel approaches, like LLM-driven search frameworks (e.g., AdaInit), are being developed to find optimal initial parameters and maximise gradient variance.
These challenges highlight that practical "quantum advantage" in the near term is often a "hybrid advantage," achieved through sophisticated co-design and optimisation between classical and quantum systems, rather than a standalone quantum phenomenon.
7. Where are quantum-enhanced LLM fine-tuning applications currently having the most impact?
Quantum-enhanced LLM fine-tuning is currently having the most impact in specialised domains characterised by complex, high-dimensional data where classical methods struggle, or where data is sparse. Key areas include:
Sentiment Analysis: Hybrid quantum-classical models have shown higher accuracy than classical methods, particularly in low-data regimes, indicating quantum computing's ability to extract nuanced patterns from limited data.
Drug Discovery: Quantum-hybrid workflows have enhanced LLMs for generating novel, more "drug-like" molecular structures, outperforming classical methods and accelerating the drug discovery process. D-Wave's collaboration with Japan Tobacco is a notable example.
Financial Modelling: Quantum models can analyse high-dimensional datasets more efficiently with fewer parameters, making them ideal for complex financial tasks like fraud detection, portfolio optimisation, and risk assessment.
Code Generation: LLMs are being fine-tuned to automatically generate high-quality parameterized quantum circuits for optimisation problems, bridging the gap between natural language and quantum programming.
Materials Science: Quantum-enhanced Generative Adversarial Networks (QGANs) are optimising materials science properties, generating synthetic images of rare anomalies with higher quality than classical GANs, addressing data scarcity.
Personalisation and Privacy: Fine-tuning techniques can encapsulate individual patient histories or adapt models for company-specific industrial applications, with quantum cryptography enhancing data security for sensitive information.
These applications leverage quantum computing's unique strengths, such as superposition, entanglement, and the ability to explore vast solution spaces and handle non-local correlations, making it a strategic tool for niche, high-value problems where classical methods encounter bottlenecks.
8. What is the future outlook for quantum LLM fine-tuning, and what role will hybrid models play?
The future outlook for quantum LLM fine-tuning is intrinsically linked to advancements in quantum hardware and the continued development of hybrid quantum-classical architectures. Major firms like BCG predict a broad quantum advantage emerging in the early 2030s, coinciding with the projected availability of error-corrected quantum computers featuring tens to hundreds of logical qubits. Full implementation across various sectors, however, may extend beyond a decade. Leading quantum computing players, including Google, IBM, and Quantum Art, have ambitious roadmaps towards building large-scale, fault-tolerant quantum computers with millions of physical and thousands of logical qubits, though these are still a decade away.
Despite these ambitious long-term roadmaps, hybrid quantum-classical systems are expected to dominate the early and mid-stages of Quantum Machine Learning (QML) adoption, remaining the primary means to achieve practical quantum advantage for LLMs in the interim. These hybrid approaches will complement classical methods rather than entirely replacing them, serving as the pragmatic bridge between current classical AI dominance and the future era of fault-tolerant quantum deep learning.
Hybrid models will continue to be strategically integrated into classical AI workflows, leveraging increased expressivity to enhance traditional AI LLMs, particularly in rare-data regimes where classical models struggle. This approach allows for incremental gains and practical applications today, while simultaneously driving the development of the underlying fault-tolerant hardware needed for more ambitious quantum AI in the future. Organisations are therefore recommended to invest in hybrid quantum-classical expertise and infrastructure now, as this paradigm will be dominant for the foreseeable future, enabling a "quantum-ready" strategy that yields competitive advantages in the present decade.