The DataOps Blueprint: A Strategic Guide to Best Practices
DataOps emerges not as an incremental improvement but as a fundamental re-architecture of how organizations manage the entire data lifecycle. It is a strategic response to the systemic failures of the past, establishing a reliable, agile, and scalable "data factory" designed to consistently produce high-quality, analytics-ready data products.


In the contemporary enterprise, data is ubiquitously recognized as a critical asset, yet the realization of its potential value remains elusive for many. Traditional data management paradigms, characterized by siloed operations, manual processes, and protracted delivery cycles, have proven inadequate in the face of escalating data volume, velocity, and complexity. These legacy approaches frequently result in data that is slow to arrive, of questionable quality, and misaligned with business needs, thereby eroding trust and hindering data-driven decision-making. DataOps emerges not as an incremental improvement but as a fundamental re-architecture of how organizations manage the entire data lifecycle. It is a strategic response to the systemic failures of the past, establishing a reliable, agile, and scalable "data factory" designed to consistently produce high-quality, analytics-ready data products. By applying proven principles from software engineering and lean manufacturing, DataOps transforms the data and analytics function from a reactive, cost-intensive service center into a proactive, value-generating engine that fuels business innovation and competitive advantage.
1.2 Summary of Core Best Practices
This report provides a comprehensive blueprint for implementing and maturing a DataOps capability. The analysis synthesizes a vast body of best practices, which are organized around three foundational pillars that must be developed in concert for a successful transformation. A failure to address any one of these pillars will fundamentally undermine the entire initiative.
Culture and People: The transformation begins with a cultural shift that dismantles organizational silos. Success is predicated on fostering a highly collaborative, cross-functional environment where data engineers, analysts, scientists, and business stakeholders work as unified teams with shared accountability for business outcomes. This requires active executive sponsorship and a robust change management program to transition the organization from a risk-averse mindset to one that embraces iteration and continuous improvement.
Process and Governance: DataOps mandates the adoption of Agile methodologies to replace slow, monolithic data projects with rapid, iterative development cycles, or "sprints". A central tenet of this process transformation is treating data as a product. This means that data assets are managed with the same rigor as commercial software, with dedicated owners, clear roadmaps, and a relentless focus on meeting the needs of data consumers and delivering measurable business value. Governance is not an afterthought but is embedded by design into every stage of the data lifecycle.
Technology and Automation: Technology serves as the enabling force for DataOps principles. End-to-end automation of the data pipeline is a cornerstone, leveraged to eliminate manual toil, reduce human error, and ensure repeatability at scale. This is operationalized through the implementation of Continuous Integration and Continuous Delivery (CI/CD) pipelines for data, which automatically test and deploy changes to data workflows. This automation is coupled with continuous monitoring and observability of both pipeline performance and data quality, providing the real-time feedback necessary to maintain trust and drive improvement.
1.3 Key Outcomes and Business Value
A mature DataOps practice delivers tangible and significant business value, transforming the economics and impact of an organization's data assets. The outcomes are not merely technical efficiencies but extend to core business performance indicators. Organizations that successfully implement DataOps can expect to realize a dramatic acceleration in their time-to-insight, reducing analytics development cycles from months to days or even hours. This agility is paired with a profound improvement in data quality and reliability, with some organizations reducing data errors by over 99%, which in turn rebuilds business trust in data-driven decisions. Financially, DataOps drives down operational costs by automating manual processes and optimizing infrastructure usage. Furthermore, by embedding governance and security controls into automated workflows, it significantly enhances an organization's ability to meet stringent regulatory compliance mandates such as GDPR and CCPA, mitigating substantial financial and reputational risk. Ultimately, DataOps increases the return on investment (ROI) from data teams and technology, ensuring that data initiatives are directly and measurably aligned with strategic business objectives.
Defining the DataOps Paradigm
2.1 The Genesis of DataOps: An Intellectual Heritage
DataOps is not a monolithic, single-source invention but rather a powerful synthesis of several battle-tested methodologies from industrial and software engineering, adapted and applied to the unique challenges of the data domain. Its strength lies in this intellectual heritage, which provides a robust foundation for transforming how data is managed, processed, and delivered. Understanding these roots is critical to grasping the core philosophy of DataOps and implementing it effectively.
Agile Development
For decades, data and analytics projects were managed using traditional "waterfall" methodologies, characterized by long, sequential phases of requirements gathering, design, development, and testing. This approach is notoriously slow and inflexible, often resulting in projects that are obsolete by the time they are delivered due to rapidly changing business needs. DataOps fundamentally rejects this model, instead importing the principles of Agile Development from the software world. In an Agile DataOps environment, work is broken down into small, manageable increments and executed in short cycles known as "sprints". This iterative process allows data teams to deliver value to business users early and often. Crucially, it creates a continuous feedback loop, enabling teams to reassess priorities and adapt to evolving requirements after each sprint, ensuring the final data product is precisely aligned with current business needs.
Lean Manufacturing
The conceptual model of a "data factory" is central to DataOps, a direct borrowing from the principles of lean manufacturing pioneered by companies like Toyota. This paradigm views the data pipeline—from ingestion to transformation to delivery—as a production line. The goal, as in manufacturing, is to maximize productivity and throughput while relentlessly minimizing waste. Waste in a data context includes time spent manually troubleshooting pipeline failures, effort expended on fixing data quality errors, and the development of analytics that provide no business value. One of the most potent tools adopted from lean manufacturing is Statistical Process Control (SPC). SPC involves continuously monitoring the operational characteristics of the data pipeline (such as data volume, processing times, or error rates) to ensure that statistical variance remains within acceptable limits. By applying SPC, teams can proactively detect anomalies in the process itself, often before they result in downstream data quality issues, leading to remarkable improvements in efficiency, quality, and transparency.
DevOps
DevOps provides the primary technical and cultural blueprint for DataOps. It arose in software development to break down the silos between development teams ("Dev") who write code and operations teams ("Ops") who deploy and manage it. By fostering collaboration and leveraging automation, DevOps dramatically shortens the software development lifecycle, enabling companies like Google and Amazon to release software thousands of times per day. DataOps applies this same ethos to the data lifecycle. It automates the integration, testing, and deployment of data pipelines through Continuous Integration and Continuous Delivery (CI/CD). It merges the worlds of data development (data engineering, data science) and data operations (pipeline monitoring, governance, infrastructure management) to create a streamlined, reliable, and rapid flow of data from source to value.
2.2 Core Principles and Objectives
From its intellectual foundations, a set of non-negotiable principles emerges that define the practice of DataOps. These principles serve as a guide for organizations seeking to implement a successful and sustainable DataOps capability.
Collaboration and Communication: At its core, DataOps is a human-centric methodology. Its primary objective is to dismantle the organizational silos that have historically separated data engineers, data scientists, data analysts, IT operations, and business stakeholders. It promotes a culture of open communication, shared tools, and frequent feedback to ensure all parties are aligned on common goals and have a unified understanding of the data and its purpose.
End-to-End Automation: Automation is the cornerstone of DataOps, serving as the primary mechanism for achieving speed, consistency, and scalability. The philosophy is to automate every repetitive task in the data lifecycle, including data ingestion, cleansing, transformation, testing, infrastructure provisioning, and pipeline deployment. This frees human talent from manual, error-prone work to focus on higher-value activities like analysis and innovation.
Continuous Integration & Continuous Delivery (CI/CD): Borrowed directly from DevOps, CI/CD is the practice of ensuring that any change to a data process—be it a new transformation script, an updated data model, or a configuration change—is automatically and continuously tested and deployed. This practice minimizes risk by deploying small, incremental updates and ensures that the data pipelines are always in a reliable, production-ready state, dramatically reducing the cycle time for delivering new analytics.
Monitoring, Measurement, and Observability: A core tenet of DataOps is that processes cannot be improved if they are not measured. This principle mandates the continuous monitoring and tracking of key metrics throughout the data lifecycle. This includes operational metrics like pipeline performance and error rates, as well as data quality metrics. The goal is to move beyond reactive troubleshooting to proactive observability, where teams can visualize pipeline health, detect anomalies in real-time, and understand the health of their data systems at any given moment.
2.3 DataOps vs. DevOps: A Critical Distinction
While DataOps owes a significant debt to DevOps, the common refrain of "DevOps for data" is an oversimplification that can lead to critical strategic errors. Technology leaders who fail to appreciate the fundamental differences between the two domains risk misallocating resources, selecting inappropriate tools, and ultimately failing in their DataOps transformation. The nature of data itself introduces unique complexities that require a distinct set of practices, skills, and technologies.
The Unique Nature of Data
The most fundamental distinction lies in the statefulness of the core artifact. Software code is essentially stateless logic; a bug can be fixed, and the code can be redeployed without altering the fundamental state of the application. Data, in contrast, is stateful, dynamic, and often irreplaceable. Data pipelines must contend with a "second source of variation" that does not exist in traditional software development: the data itself. Data volumes can fluctuate unpredictably, source schemas can change without warning, and data quality can drift over time. A perfectly written data transformation script can fail not because of a bug in the code, but because the underlying data has changed. This requires DataOps practices to focus as much on validating and monitoring the data as they do on testing the code.
Divergent Focus and Deliverables
The end products of each discipline are fundamentally different. DevOps teams deliver software applications, system updates, and infrastructure improvements, with a focus on application performance, uptime, and user experience. The output of DataOps is not an application but a trusted data product. This could be a clean, curated dataset, a business intelligence report, an interactive dashboard, or a machine learning model. This difference in deliverables leads to different success metrics. DevOps success is measured by metrics like deployment frequency and mean time to recovery (MTTR), whereas DataOps success is ultimately measured by the quality, timeliness, and business impact of the data it delivers.
Expanded Collaboration Scope
While DevOps was revolutionary in bridging the gap between software developers and IT operations, the collaborative scope of DataOps is significantly broader and more complex. A successful DataOps initiative must create a seamless working relationship not just between technical teams but also with a diverse array of business stakeholders. It unites data engineers who build the pipelines, data scientists who model the data, data analysts who visualize the insights, and the end business users who consume the data to make decisions. This expanded scope makes effective communication and alignment with business objectives even more critical than in a typical DevOps environment.
Technology Stack Differences
Although both methodologies leverage foundational tools like Git for version control and CI/CD orchestrators, their core technology stacks are specialized and distinct. A typical DevOps toolchain includes platforms like Jenkins, Docker for containerization, and Kubernetes for orchestration. A DataOps toolchain, while potentially using some of the same CI/CD tools, relies on a specialized set of technologies designed for data-centric workflows. This includes data integration and ETL/ELT tools (e.g., Talend, Fivetran), data pipeline orchestration frameworks (e.g., Apache Airflow, Dagster), data quality and observability platforms (e.g., Monte Carlo, Great Expectations), and data governance tools like data catalogs. Attempting to manage complex data pipelines using a purely DevOps-native toolset is a common cause of failure.
To provide leaders with a clear, actionable summary of these critical distinctions, the following table offers a comparative analysis.
Table 1: DataOps vs. DevOps - A Comparative Analysis
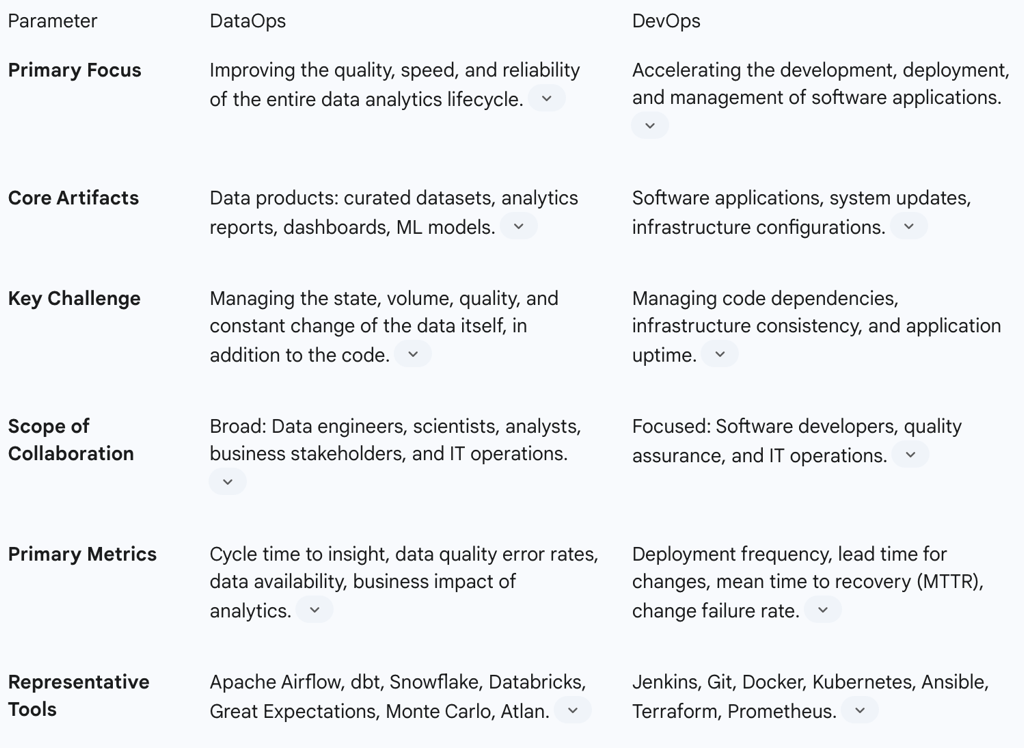
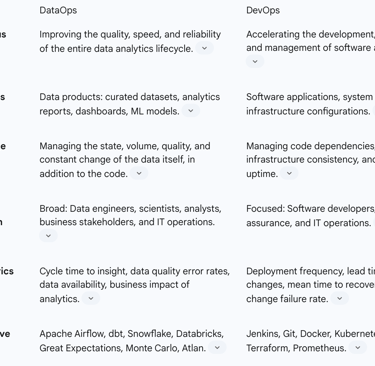
2.4 The "Ops" Ecosystem: Context and Synergy
DataOps does not exist in a vacuum. It is part of a growing family of "Ops" methodologies, each applying DevOps principles to a specific domain. Understanding how DataOps relates to its counterparts, particularly MLOps and AIOps, is crucial for developing a cohesive enterprise technology strategy. A clear dependency chain exists among these disciplines, creating a functional hierarchy where the success of more advanced initiatives is contingent upon the maturity of the foundational layers.
DataOps as the Foundation
Robust DataOps is the essential foundation upon which effective MLOps is built. Machine learning models are fundamentally dependent on a steady supply of high-quality, reliable, and timely data for both training and real-time inference. The core purpose of DataOps is to create and manage the automated, monitored data pipelines that provide this exact type of trustworthy data. An organization that attempts to scale its machine learning initiatives without first establishing a mature DataOps practice is building on sand. Their MLOps efforts will be perpetually hampered by data availability issues, poor data quality, and model drift, making it nearly impossible to reliably move models from experimental prototypes into production environments. This establishes a clear strategic sequence: DataOps must be prioritized as the foundational enabler of an organization's broader AI and machine learning ambitions.
MLOps (Machine Learning Operations)
MLOps extends the principles of DevOps and CI/CD to the complete lifecycle of machine learning models. While DataOps focuses on the data pipeline, MLOps focuses on the model pipeline. Its scope includes automating model training and validation, versioning models and datasets, deploying models as scalable services, and continuously monitoring their performance in production to detect degradation or drift. MLOps consumes the output of DataOps—the clean, prepared data—as its primary input.
AIOps (AI for IT Operations)
AIOps represents a further level of abstraction, applying artificial intelligence and machine learning techniques to automate and enhance IT operations. AIOps platforms analyze vast quantities of operational data, such as system logs, performance metrics, and network traffic, to proactively identify patterns, predict outages, and automate remediation tasks. In this context, AIOps is a consumer of the outputs of both DataOps and MLOps. It relies on DataOps pipelines to provide the real-time telemetry and log data it needs for analysis, and it often incorporates machine learning models (managed via MLOps) to perform its pattern recognition and predictive functions.
The Cultural Imperative: People and Collaboration
3.1 Fostering a Collaborative Data Culture
While technology and process are critical enablers, the successful implementation of DataOps is, first and foremost, a cultural and organizational transformation. Attempting to layer DataOps tools and techniques onto a traditional, siloed organizational structure is a recipe for failure. The foundational prerequisite for DataOps is a culture that prioritizes collaboration, shared ownership, and a collective focus on delivering business value through data.
Breaking Down Silos
The most significant cultural barrier to DataOps is the prevalence of organizational silos. In many enterprises, data engineering, data science, business analytics, and various business units operate in isolation. This structure creates a series of handoffs rather than a continuous workflow, leading to fragmented ownership, misaligned priorities, duplicated work, and significant delays. For example, a data engineering team might build a pipeline based on their interpretation of requirements, only to "throw it over the wall" to an analytics team who finds it unfit for their purpose. DataOps demands the systematic dismantling of these silos. A key strategy for achieving this is the formation of persistent, cross-functional teams, often organized as "squads" or "pods" aligned with specific business domains (e.g., marketing analytics, supply chain intelligence). These teams contain all the necessary expertise—data engineering, analytics, and product ownership—to manage a data product's lifecycle from end to end, fostering deep collaboration and a unified sense of purpose.
Shared Goals and Accountability
Siloed teams naturally optimize for their own local metrics. Data engineers may focus on pipeline uptime, while analysts focus on report delivery, with neither group being fully accountable for whether the final insight actually drove a positive business outcome. DataOps inverts this model by aligning all teams around shared goals that are defined in business terms, not technical ones. Instead of measuring the number of pipelines built, success is measured by the reduction in customer churn, the increase in marketing campaign effectiveness, or the optimization of inventory costs. This shift fosters a culture of shared accountability, where the entire cross-functional team is collectively responsible for the success or failure of the data product in achieving its intended business objective.
Data as a Shared Asset
A critical mindset shift required for a DataOps culture is the transition from viewing data as a departmental possession to viewing it as a shared enterprise asset. Historically, departments have tended to "hoard" their data, seeing it as a source of power and control. This behavior creates new, more insidious silos and prevents the organization from realizing the full value of its data, which, unlike physical assets, actually gains value the more it is used and combined with other datasets. A true DataOps culture promotes the prudent sharing of data. This does not mean a free-for-all; rather, it requires the establishment of a robust data governance framework that provides clear policies on data access, security, and usage, enabling data to be shared responsibly and securely across the organization.
3.2 Leadership and Change Management
The cultural transformation required for DataOps cannot happen organically; it must be deliberately led from the top. The journey from a traditional, risk-averse data culture to an agile, collaborative one is fraught with challenges and requires active, persistent, and visible executive leadership.
A fundamental tension exists at the heart of this transformation. The goal of DataOps is to dramatically increase the speed and agility of data delivery, which necessitates a culture of experimentation and rapid iteration. However, the traditional domain of enterprise data management has been shaped by a culture of extreme caution, risk aversion, and a focus on control to prevent errors. These two cultural paradigms are in direct opposition. Simply introducing automated CI/CD pipelines into an organization that punishes failure and requires multiple layers of manual approval for any change will result in "agile theater," where new tools are constrained by old processes. The core challenge for leadership is to resolve this paradox. This requires creating an environment of "psychological safety," where teams are empowered to experiment, where small, fast failures are treated as valuable learning opportunities, and where iteration is rewarded over the illusion of initial perfection. Without this foundational shift, even the most sophisticated technological implementations of DataOps are destined to fail.
Executive Sponsorship
Successful DataOps initiatives are not delegated IT projects; they are strategic business transformations that require active and visible sponsorship from the highest levels of leadership. Executives must do more than simply approve the budget. They must "walk the talk" by championing the initiative, clearly communicating its importance, and actively using the data and analytics products generated by the DataOps teams in their own strategic decision-making processes. When a CEO opens a board meeting by referencing a dashboard produced by the new system, it sends a powerful message throughout the organization about the importance of the data-driven culture.
A "North Star" Vision
To inspire and align the organization, leaders must craft and communicate a compelling "North Star" vision for the DataOps transformation. This vision should not be focused on the implementation of specific tools or technologies. Instead, it should articulate the tangible business outcomes that will be achieved: how the company will create new value, gain a competitive advantage, and better serve its customers through a more agile and reliable data capability. A clear and inspiring North Star provides direction and purpose, helping to motivate teams and guide decision-making throughout the challenging process of transformation.
Navigating Resistance
Any significant organizational change will inevitably be met with resistance. This resistance can stem from a lack of understanding of the benefits of DataOps, apprehension about learning new technologies and processes, or a fear of losing control or relevance. A proactive and well-resourced change management strategy is therefore not optional, but essential. This strategy must include comprehensive education and training programs to build data literacy and new skills across the organization. It requires clear, consistent, and transparent communication about the reasons for the change, the expected benefits, and the progress of the implementation. As research from McKinsey suggests, leading organizations often invest twice as much in the change management and adoption aspects of a transformation as they do in building the technical solution itself, a testament to the critical importance of managing the human side of change.
3.3 Aligning Data Operations with Business Objectives
A common and critical failure pattern in DataOps implementations is treating the initiative as a purely technical exercise, with success measured by engineering metrics like pipeline throughput or deployment speed. While these metrics are important for operational efficiency, they are not the ultimate goal. The true purpose of DataOps is to generate business value. Therefore, every aspect of the DataOps strategy must be explicitly and continuously aligned with the strategic objectives of the business.
From Technical Metrics to Business Value
The success of a DataOps team should not be judged on its technical output, but on its business impact. The focus must shift from delivering pipelines to delivering answers that help the business make better, faster decisions. This requires a deep engagement between the data teams and their business stakeholders to understand the key questions the business is trying to answer and the critical decisions it needs to make. Key Performance Indicators (KPIs) for the DataOps initiative should reflect this business alignment, focusing on metrics like the reduction in time-to-insight for critical business questions, the ROI of data-driven marketing campaigns, or the measurable impact of analytics on operational efficiency.
The "Data as a Product" Mindset
The most effective framework for ensuring business alignment is the adoption of a "Data as a Product" mindset. This paradigm shift involves treating data assets with the same discipline and customer-centric focus as a commercial software product. In this model, a "data product" is a durable, reusable data asset designed to serve a specific set of use cases for a defined group of data consumers. Each data product has a dedicated Data Product Owner, a role that is typically business-facing and is responsible for defining the product's vision and roadmap, gathering requirements from users, prioritizing development work, and being accountable for the product's adoption and value creation. This approach directly combats the problem of data teams building technically elegant but commercially irrelevant solutions, ensuring that development effort is always focused on solving real business problems.
Structuring for Success: Teams and Responsibilities
4.1 Anatomy of a Modern DataOps Team
Successfully implementing DataOps requires more than just adopting new processes; it necessitates structuring teams with clearly defined roles and responsibilities to execute these processes effectively. While the specific titles may vary between organizations, a mature DataOps capability is typically composed of a set of core and specialized roles that work in concert to manage the end-to-end data lifecycle. The following table and descriptions provide a blueprint for staffing a modern DataOps team, clarifying the unique contribution of each role and preventing the common pitfall of overloading a single "data engineer" with the full spectrum of DataOps responsibilities.
Table 2: Key Roles and Responsibilities in a DataOps Team
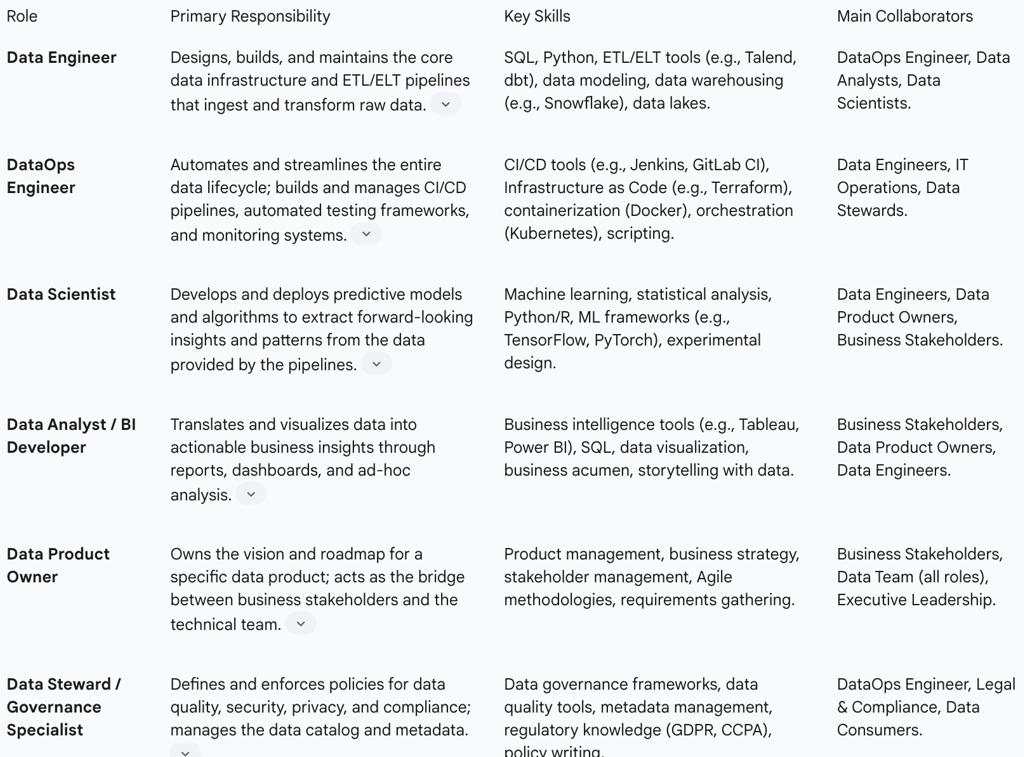
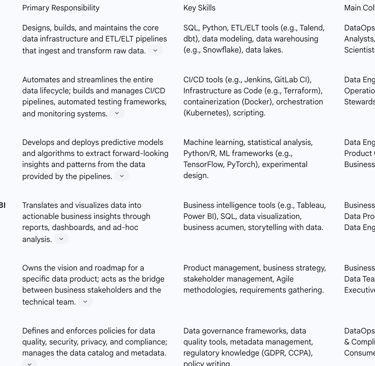
Data Engineer
The Data Engineer is the foundational builder of the data ecosystem. This role is responsible for the core tasks of data architecture and pipeline development. They design and construct scalable systems to collect, store, and process data from a multitude of sources. Their primary focus is on transforming raw, often messy, data into clean, structured, and usable formats that can be consumed by downstream analytics processes. This involves deep expertise in data modeling, ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) processes, and the management of data warehouses and data lakes.
DataOps Engineer
The DataOps Engineer is a specialized role that acts as the critical link between data engineering and operations, applying DevOps principles to the data domain. While a Data Engineer builds the data pipelines, the DataOps Engineer builds the "factory" that manufactures and delivers those pipelines reliably and efficiently. Their responsibilities are centered on automation and process optimization. They design, implement, and manage the CI/CD pipelines for data workflows, create automated testing frameworks to ensure data quality, and implement monitoring and alerting systems to ensure the health and performance of the production data environment. This role requires a hybrid skillset, combining data engineering knowledge with expertise in automation, infrastructure as code, and cloud operations.
Data Scientist
The Data Scientist is a primary consumer of the data products created by the data engineering pipelines. They leverage this clean, prepared data to build sophisticated statistical and machine learning models that uncover hidden patterns, predict future outcomes, and drive strategic business decisions. Their work often involves experimentation, hypothesis testing, and the development of complex algorithms. In a DataOps culture, they collaborate closely with data engineers to ensure the data they need is available and in the correct format for their modeling activities.
Data Analyst / BI Developer
The Data Analyst or Business Intelligence (BI) Developer serves as the crucial translator between the data and the business. They take the structured data and the outputs of data science models and transform them into digestible insights for non-technical stakeholders. Their primary deliverables are interactive dashboards, reports, and visualizations that track key performance indicators and answer specific business questions. They are experts in BI tools and possess strong business acumen, enabling them to tell compelling stories with data that guide day-to-day operational and tactical decision-making.
Data Product Owner
As organizations adopt the "Data as a Product" mindset, the Data Product Owner becomes an essential strategic role. This individual is responsible for a specific data product's success from a business perspective. They maintain the product roadmap, work closely with business stakeholders to understand their needs and gather requirements, prioritize features for the development team, and are ultimately accountable for ensuring the data product delivers measurable value to the organization. This role is the critical bridge between the technical data team and the business consumers they serve.
Data Steward / Governance Specialist
The Data Steward or Governance Specialist is the guardian of the organization's data assets. This role is responsible for defining and enforcing the policies and standards that ensure data is accurate, consistent, secure, and compliant with regulations. Their duties include establishing data quality rules, managing metadata in a data catalog, defining data access policies, and ensuring adherence to privacy laws like GDPR and CCPA. They work closely with DataOps engineers to embed these governance controls directly into the automated data pipelines, a practice known as "Governance by Design."
4.2 Operating Models and Collaboration Patterns
Having the right roles is necessary but not sufficient. How these roles are organized and interact is equally critical to success. Effective DataOps operating models are designed to maximize collaboration and minimize friction.
Cross-Functional Teams
The most effective operating model for DataOps involves moving away from functionally siloed teams (e.g., a central data engineering team, a separate analytics team) and toward the creation of persistent, cross-functional teams aligned with business domains or specific data products. For example, a "Customer 360" team might include data engineers, a DataOps engineer, data analysts, and a Data Product Owner, all dedicated to building and maintaining the data products related to customer data. This model fosters a strong sense of ownership, dramatically improves communication, and reduces the delays and misunderstandings associated with handoffs between separate teams.
Center of Excellence (CoE)
While cross-functional teams provide domain-specific focus, a DataOps Center of Excellence (CoE) can provide centralized expertise and enablement. The role of a modern DataOps CoE is not to be a bureaucratic gatekeeper, but rather a force multiplier. It is responsible for establishing enterprise-wide best practices, selecting and managing the shared DataOps toolchain and platforms, and providing expert consulting and support to the embedded, domain-aligned teams. The CoE builds the "paved road" of standardized tools and patterns, making it easy for the cross-functional teams to build and deploy their data products quickly and consistently.
Technical Best Practices for the Data Pipeline
5.1 End-to-End Automation and Orchestration
At the heart of DataOps' technical implementation lies the principle of end-to-end automation, managed and controlled by a data orchestration platform. Orchestration is the "engine room" of the data factory, responsible for programmatically defining, scheduling, executing, and monitoring the complex web of tasks that constitute a data pipeline. Modern orchestrators represent these workflows as Directed Acyclic Graphs (DAGs), which provide a clear, code-based definition of all tasks and their dependencies.
The Role of Orchestration
Data orchestration tools like Apache Airflow, Prefect, and Dagster provide the backbone for DataOps automation. They move organizations beyond brittle, hard-to-manage cron jobs to a robust system that can handle complex dependencies, automated retries, and detailed logging. A key function of orchestration is to stitch together the various tools and processes in the data stack—from ingestion tools to transformation engines to data quality checkers—into a single, cohesive, and automated workflow.
Best Practices for Orchestration Tools (e.g., Apache Airflow)
Effective use of orchestration tools requires adherence to a set of critical best practices to ensure pipelines are reliable, maintainable, and scalable.
Separate Orchestration from Execution: A common anti-pattern is to perform heavy data processing directly within the orchestration tool's workers (e.g., running a large pandas transformation in an Airflow task). This can overwhelm the orchestrator's resources and lead to instability. The best practice is to use the orchestrator to
trigger and monitor tasks that run on dedicated processing engines (e.g., a Spark cluster, a data warehouse like Snowflake, or a Kubernetes pod). The orchestrator manages the "what" and "when," while the processing engine handles the "how".
Design Idempotent Tasks: An idempotent task is one that can be run multiple times with the same input and will produce the same result, without creating side effects like duplicate data. This is crucial in DataOps because tasks often need to be retried upon failure. For example, instead of using a simple
INSERT statement to load data, which would create duplicates on a re-run, tasks should use an UPSERT (update or insert) or a "load-and-swap" pattern to ensure idempotency.
Centralize and Secure Configurations: Hardcoding connection strings, API keys, or other configuration details directly into pipeline code is a significant security risk and makes pipelines brittle. Best practice dictates using the orchestrator's built-in features for managing secrets and connections, such as Airflow's Connections and Variables, which store this information securely in a metadata database.
Embrace Modularity and Reusability: Monolithic, complex pipelines are difficult to debug, maintain, and update. Pipelines should be broken down into smaller, logical, and modular tasks. Furthermore, common patterns and tasks should be abstracted into reusable components or templates that can be shared across multiple pipelines, accelerating development and ensuring consistency.
5.2 Implementing CI/CD for Data Analytics
Continuous Integration and Continuous Delivery (CI/CD) is the set of practices and automated workflows that enable data teams to deliver changes to their data pipelines frequently and reliably. It is the mechanism that translates the principles of Agile and automation into practice.
Pipeline Stages
A typical CI/CD pipeline for a data analytics workflow consists of several distinct, automated stages :
Prepare: This initial stage sets up the environment for the pipeline run. It may involve checking out code from a version control repository, setting environment variables, and installing necessary dependencies.
Validation: This stage runs static checks on the project code. This can include code linting, checking for adherence to naming conventions, and ensuring proper documentation is present. It serves as an initial, fast-feedback quality check before more intensive processes begin.
Package: Here, the data analytics project is built into a consistent, deployable artifact. For a dbt project, this would involve creating a compiled package of the SQL models. For a Python-based transformation, it might involve building a Docker container. This artifact is versioned and stored, ensuring that the exact same package is used in all subsequent environments.
Pre-production (Staging): The packaged artifact is automatically deployed to a dedicated testing or staging environment that mirrors production as closely as possible. A comprehensive suite of automated tests is then run against this deployment. This includes unit tests, integration tests, and, most importantly, data quality tests on a subset of production or synthetic data. If any test fails, the pipeline stops, preventing the faulty change from reaching production.
Production: Upon successful completion of all tests in the pre-production stage, the artifact is deployed to the live production environment. This step can be fully automated (Continuous Deployment) or can be triggered by a manual approval (Continuous Delivery), providing an additional layer of human oversight for critical changes.
Best Practices
Build Only Once: A core principle of CI/CD is that a software artifact should be built a single time and then promoted through the various environments (e.g., from staging to production). This guarantees that the code running in production is the exact same code that was tested, eliminating a common source of "it worked in staging" errors.
Environment as Code: To prevent "configuration drift," where staging and production environments slowly diverge over time, all environment configurations should be defined as code using Infrastructure as Code (IaC) tools like Terraform or Ansible. This allows environments to be created and torn down automatically, ensuring they are always consistent and reproducible.
Automated Promotion and Rollback: The process of moving a successful build from one stage to the next should be fully automated by the CI/CD tool. Equally important is having an automated rollback mechanism. If a deployment to production causes unforeseen issues, the CI/CD pipeline should be able to quickly and automatically revert to the last known good version.
5.3 Robust Version Control
Version control, typically using Git, is the bedrock of CI/CD and a non-negotiable practice in DataOps. It provides a complete audit trail of every change, facilitates collaboration among team members, and enables the automation that underpins the entire methodology.
Version Everything: The scope of version control in DataOps is comprehensive. It is not limited to just the Python or Scala code used in data processing. It must also include all transformation logic (e.g., SQL scripts, dbt models), schema definitions (DDL scripts), infrastructure definitions (Terraform files), pipeline configurations (DAG files), and documentation. This ensures that the entire state of the data platform can be recreated from the version control repository.
Git Branching Strategies: To manage development in a collaborative environment without destabilizing the production system, a structured branching strategy is essential. The Feature Branching model is a widely adopted best practice. In this model, the
main branch is always kept in a stable, production-ready state. All new development, whether for a new feature or a bug fix, takes place in a separate, short-lived "feature branch." Once the work in the feature branch is complete and tested, it is merged back into the main branch via a pull request, which triggers the CI/CD pipeline.
Meaningful Commits: The practice of making small, frequent, and "atomic" commits is critical. An atomic commit represents a single, logical unit of work (e.g., "Add customer dimension model" or "Fix null value bug in sales data"). Each commit should be accompanied by a clear, descriptive message explaining what was changed and why. This discipline makes the history of changes easy to understand, simplifies code reviews, and allows for precise rollbacks if a specific change introduces a problem.
Versioning Data Itself: An advanced but increasingly important practice is the versioning of the data itself, not just the code that processes it. Tools like lakeFS bring Git-like capabilities to data lakes and warehouses. They allow data engineers to create zero-copy "branches" of their data, perform transformations and experiments in isolation on these branches, and then "merge" the changes back into the main dataset atomically. This enables risk-free development on production-scale data and provides the ultimate safety net: the ability to instantly revert the data itself to any previous point in time, effectively eliminating the risk of data corruption from a bad deployment.
5.4 The Cornerstone of Trust: Automated Testing and Data Quality
In DataOps, the ultimate goal is not just to deliver data quickly, but to deliver trusted data. Automated testing is the primary mechanism for building and maintaining this trust. A comprehensive testing strategy is essential for ensuring the accuracy, integrity, and reliability of data products.
A key distinction from traditional software testing is the source of potential failure. In software engineering, the logic within the code is the primary source of bugs. In data engineering, while code logic can be faulty, a more frequent and unpredictable source of failure is the data itself—unexpected schema changes, quality degradation in source systems, or sudden shifts in data distribution. Consequently, a testing strategy that focuses solely on the transformation code (e.g., unit tests) while ignoring the data is insufficient. The testing paradigm must shift from asking "Does the code work?" to "Does the code work correctly with this specific data?" This often leads to a testing strategy that prioritizes tests which validate the data in-context within the pipeline, such as integration and end-to-end data quality checks, over isolated unit tests.
A Multi-Layered Testing Strategy
A robust DataOps testing strategy incorporates multiple layers of validation, automated and executed within the CI/CD pipeline:
Unit Tests: These tests validate small, individual pieces of transformation logic in isolation. For example, a unit test might check if a specific Python function correctly parses a date string or if a SQL macro correctly calculates a specific business metric.
Integration Tests: These tests verify that different components of the data pipeline interact correctly. For example, an integration test might check if a data ingestion task correctly writes data to a staging area in a format that a downstream transformation task can read and process.
End-to-End Tests: These tests validate the entire data pipeline, from the initial data source to the final output (e.g., a BI dashboard or a curated data table). They often involve reconciling counts or aggregate values between the source and target to ensure no data was lost or incorrectly transformed during the process.
Continuous Data Quality Monitoring
Beyond testing code changes, mature DataOps involves the continuous monitoring of the data itself as it flows through the pipelines.
Data Quality Dimensions: Monitoring is structured around key dimensions of data quality, which serve as a framework for defining tests. These include:
Accuracy: Is the data correct (e.g., does a state code match a valid list)?
Completeness: Are there missing values or nulls where they shouldn't be?
Consistency: Is the same piece of information (e.g., a customer name) represented uniformly across different systems?
Timeliness/Freshness: Has the data arrived within its expected timeframe?
Validity: Does the data conform to the correct format and type (e.g., is an email address properly formatted)?
Uniqueness: Are there duplicate records where there should be none (e.g., duplicate customer IDs)?
Automated Checks as "Quality Gates": Data quality checks based on these dimensions should be implemented as automated steps within the data pipeline at critical junctures, such as immediately after ingestion and after major transformations. These checks function as "quality gates." If the incoming data fails a critical quality check (e.g., more than 5% of records are missing a required field), the pipeline can be configured to halt automatically, preventing the "data garbage" from propagating downstream and corrupting analytics.
Data Observability: This is an evolution of monitoring that focuses on understanding the overall health of the data systems. Data observability platforms automatically collect metadata and statistics about pipelines and data assets to monitor metrics like data freshness (when was the data last updated?), distribution (are the values within expected ranges?), volume (has the expected amount of data arrived?), and schema (has the structure of the data changed?). By establishing historical baselines, these systems can proactively detect anomalies and alert teams to potential "data downtime" incidents, often before downstream consumers are even aware of a problem.
From Data Cleansing to Process Control: The Role of Statistical Process Control (SPC)
A truly advanced DataOps practice moves beyond simply detecting and cleaning bad data to controlling the process that creates it. This is where Statistical Process Control (SPC), a technique from lean manufacturing, becomes invaluable. Instead of just validating the data's content, SPC monitors the operational metadata of the data pipeline process itself over time. For example, a team might track the number of rows processed, the percentage of null values in a key column, or the average value of a numerical field for each pipeline run. This data is plotted on a control chart, which uses statistical analysis to establish upper and lower control limits representing the normal, expected range of variation for that process. Any data point that falls outside these limits signals a "special cause" variation—an unexpected event that indicates a potential problem with the pipeline process (e.g., a change in an upstream source system, a bug in a transformation). This allows the team to investigate and fix the root cause of the variation before it leads to a significant data quality failure, shifting from a reactive to a proactive mode of quality management.
5.5 Governance by Design
In traditional data management, governance is often a manual, bureaucratic process that is perceived as a blocker to agility. In DataOps, the goal is "Governance by Design," where governance and security controls are not an afterthought but are embedded and automated directly within the data pipelines and development workflows.
This is achieved through a variety of practices:
Automated Data Masking and PII/PHI Detection: Pipelines can include automated steps that scan for and classify sensitive data, such as Personally Identifiable Information (PII) or Protected Health Information (PHI), and apply data masking or encryption techniques to protect it, especially in non-production environments.
Access Control as Code: Role-Based Access Controls (RBAC) can be defined as code and managed in version control. This ensures that permissions are applied consistently and provides a clear audit trail of who has access to what data.
Automated Data Lineage: DataOps tools can automatically parse SQL code and orchestration logs to generate data lineage graphs. This provides a clear, visual map of how data flows from its source to its final destination, including all transformations it undergoes. Lineage is critical for impact analysis (understanding what will break if a source changes), root cause analysis (tracing a data error back to its origin), and regulatory compliance.
Data Catalogs: A central data catalog serves as a single source of truth for all data assets. It automatically ingests technical metadata (schemas, data types) and allows for human curation of business metadata (definitions, ownership, quality scores). By integrating with the data pipelines, the catalog ensures that data is not only available but also discoverable, understandable, and trusted by its consumers.
The Implementation Roadmap
6.1 Navigating Common Pitfalls and Blockers
The path to a mature DataOps capability is fraught with potential challenges. Awareness of these common pitfalls is the first step toward avoiding them. A successful implementation requires a holistic strategy that anticipates and mitigates risks across cultural, procedural, and technical dimensions.
Cultural & Strategic Pitfalls
Treating DataOps as a Technology-Only Solution: The most common failure pattern is the assumption that DataOps can be achieved simply by purchasing and implementing a new set of tools. This approach ignores the fact that DataOps is primarily a cultural and process-oriented discipline. Without the corresponding shifts in how teams collaborate, measure success, and manage change, new tools will only automate existing inefficiencies, leading to brittle workflows and a failure to realize the promised value.
Failing to Align with Business Objectives: DataOps initiatives that are treated as internal IT or engineering projects, focused solely on technical metrics like pipeline speed, are likely to lose funding and support. If the data products being delivered faster are not the ones the business actually needs, the effort is wasted. Success requires a constant, obsessive focus on solving real business problems and measuring outcomes in terms of business value, not technical output.
Lack of Executive Sponsorship and Poor Change Management: A DataOps transformation requires a fundamental shift in how people work and think about data. This level of change is impossible without strong, visible, and sustained sponsorship from executive leadership. Without this backing, and without a dedicated change management program to communicate the vision, provide training, and manage resistance, the initiative will stall as it collides with organizational inertia and fear of the new.
Process & Governance Pitfalls
Overlooking Data Governance and Quality: In the pursuit of speed and agility, it can be tempting to cut corners on data governance and quality checks. This is a critical error. The goal of DataOps is to deliver
trusted data faster. Sacrificing quality for speed erodes trust and ultimately renders the entire effort worthless, as business users will refuse to use unreliable data. Governance and automated quality testing must be built into the process from the beginning.
Not Deploying Frequently: Teams that are accustomed to long release cycles may be hesitant to adopt the frequent, small deployments characteristic of DataOps. However, infrequent deployments are paradoxically more risky. They bundle many changes together, making it difficult to identify the source of any problems. Furthermore, the longer the deployment process takes, the more stressful and error-prone it becomes. Frequent, small, automated deployments reduce risk, build operational muscle, and allow for faster feedback and course correction.
Failing to Treat Data Differently from Code: A crucial mental model in DataOps is to treat data and the code/schema that defines it differently. The schema, structures, and transformation code are like a "herd" of cattle—they can be managed as a group and are ultimately replaceable, as they can be recreated from the version-controlled source code. The data itself, however, is often like a "pet"—it is unique, irreplaceable, and requires careful handling, including robust backup, recovery, and rollback strategies.
Technical Pitfalls
Choosing the Wrong Tools or Being Tool-Obsessed: While tools are important enablers, an excessive focus on technology selection without a clear understanding of the underlying principles and business needs can lead to poor choices. Organizations may purchase a data warehouse they don't yet need or select a complex orchestration tool when a simpler solution would suffice. The strategy and process should drive the tool selection, not the other way around.
Not Automating Enough: Partial automation is a common pitfall. Teams may automate their data transformations but leave testing, deployment, or monitoring as manual steps. This creates bottlenecks and reintroduces the risk of human error that DataOps is designed to eliminate. The goal should be to automate as much of the end-to-end lifecycle as is practical.
Technology Integration Issues: The modern data stack is composed of numerous specialized tools. Without a coherent architectural strategy, integrating these disparate systems can become a significant challenge, leading to complex, brittle pipelines that are difficult to manage and maintain.
6.2 The DataOps Maturity Model: A Framework for Progress
DataOps is not a binary state that is either "on" or "off." It is a journey of continuous improvement. A DataOps maturity model provides a valuable framework for organizations to assess their current capabilities, identify areas for improvement, and create a structured, actionable roadmap for advancing their practice. The following synthesized model outlines a typical progression through four levels of maturity.
Level 1: Ad-Hoc / Initial
At this foundational level, data processes are chaotic and reactive.
Characteristics: Work is performed manually on an individual project basis. Data is often stored in "shoeboxes" on local machines or in isolated databases and is not easily discoverable or shareable. There is no version control, no automated testing, and collaboration is minimal, typically occurring via email or ad-hoc meetings. The OT team might hand off raw data to the IT team with little context or collaboration.
Focus: The primary focus is simply on completing individual tasks and responding to immediate, urgent requests.
Level 2: Repeatable
Organizations at this level have begun to introduce basic process discipline.
Characteristics: Some data processes are documented and can be repeated, though they are still largely manual. Routine data sources are made available in a more centralized way (e.g., a data lake), but discovering new data remains an ad-hoc process. Some basic data contextualization may occur, such as adding descriptors for location or function. Automation is limited to isolated scripts, and there is no overarching orchestration or CI/CD pipeline. Collaboration is inconsistent and often still siloed by function.
Focus: The focus is on creating stability and predictability in core data delivery processes.
Level 3: Defined / Managed
This level represents the successful implementation of core DataOps practices.
Characteristics: DataOps processes are standardized and adopted across multiple teams. A Center of Excellence may be established to promote best practices. CI/CD pipelines are implemented for key data products, and automated testing for both code and data quality is a standard part of the development lifecycle. Version control is used for all critical artifacts. Data governance policies are formally defined, and tools like a data catalog are used to enforce them. Collaboration is structured and cross-functional, often through domain-aligned teams. Site-wide visibility is achieved through standard logical models of information.
Focus: The focus is on scaling DataOps practices across the organization to improve the speed, quality, and reliability of data delivery.
Level 4: Optimized / Enterprise-Wide
At the highest level of maturity, DataOps becomes a mechanism for continuous improvement and strategic advantage.
Characteristics: The organization has a deeply ingrained DataOps culture. Processes are not just managed but are continuously measured and optimized. Advanced techniques like Statistical Process Control (SPC) are used to proactively manage pipeline quality. Data is managed and visible across the entire enterprise, with data structures synchronized across multiple sites and systems. There is strong, seamless collaboration among all OT, IT, digital transformation, and business teams. The focus shifts from delivering data to enabling self-service analytics and pushing insights from the enterprise level down to the operational edge.
Focus: The focus is on optimizing the entire data value chain for business impact and using data to drive innovation and competitive differentiation.
Organizations can use this model to benchmark their current state by asking targeted questions (e.g., "Is our code version-controlled?", "Do we have automated quality gates?") and then identify the specific practices and technologies needed to advance to the next level.
DataOps in Action: Industry Case Studies
7.1 Netflix: Scaling Analytics with a DevOps Culture
While Netflix is more famously associated with DevOps, its journey provides a powerful case study on creating the cultural and technical prerequisites for managing data at an immense scale. The company's transformation was catalyzed by a major database failure in 2008, which prompted a multi-year migration to a distributed, cloud-based architecture on AWS. This move forced the company to develop a culture of automation, resilience, and engineering excellence that is directly applicable to DataOps principles.
Netflix's core business model—from its content recommendation engine to its decisions on which new shows to produce—is fundamentally driven by data analytics. The company collects vast amounts of data on user behavior, such as viewing habits, search queries, and even when users pause or abandon a show. This data is fed through robust, scalable data pipelines to generate the personalized experiences that are key to its competitive advantage. According to Netflix, approximately 80% of viewer activity is driven by its personalized algorithmic recommendations, a testament to the business impact of its data infrastructure.
A key lesson from Netflix is its proactive approach to building resilient systems. Their creation of the "Simian Army," including the famous "Chaos Monkey" tool, exemplifies a core DataOps principle: building for failure. Chaos Monkey randomly terminates production instances to force engineers to build fault-tolerant services that can withstand unexpected failures. Applying this mindset to data pipelines means designing them to be resilient to upstream data quality issues, source system outages, and other common problems, ensuring that the flow of data remains reliable even in imperfect conditions. Netflix's story demonstrates that a mature DataOps capability is not just about building pipelines, but about fostering a deep engineering culture focused on automation, testing, and resilience at scale.
7.2 Airbnb: From Brittle Scripts to Scalable Orchestration
Airbnb's data journey provides a classic example of an organization moving up the DataOps maturity model out of necessity. In its earlier stages, the company's data workflows were managed by a collection of brittle cron jobs and custom scripts. This ad-hoc approach became increasingly unmanageable, fragile, and difficult to scale as the company grew, representing a common state for organizations at Level 1 of the maturity model. The pain of managing this complexity directly led a team of Airbnb engineers to create Apache Airflow, which has since become one of the world's leading open-source data orchestration platforms.
The development of Airflow represents Airbnb's transition to a more mature, orchestrated data environment. It allowed them to move from unreliable scripts to defining their data pipelines as code, enabling version control, programmatic scheduling, and clear dependency management. This provided the reliability and scalability needed to support the company's data-driven operations, which are used to optimize everything from search rankings to pricing recommendations.
More recently, Airbnb's development of its internal "Journey Platform" showcases a further evolution toward a highly mature DataOps practice. This platform is a low-code tool that abstracts away the complexity of the underlying orchestration engine (Temporal), allowing non-technical users in areas like marketing to build and manage their own complex, event-driven notification workflows using a simple drag-and-drop interface. This focus on self-service and the empowerment of business users is a hallmark of a Level 4 DataOps capability. It demonstrates a shift from the data team being a service provider to being an enabler, building platforms that allow the rest of the organization to leverage data directly and safely.
7.3 Capital One: Data Management as a Strategic Capability
Capital One's approach to data exemplifies the strategic and business-centric view that defines a mature DataOps implementation. The company's leadership explicitly frames data management not as a technical function but as a core strategic capability essential for competition and innovation. This perspective provides the top-down executive sponsorship that is critical for driving the necessary cultural change.
The company emphasizes three key pillars that align directly with DataOps best practices. First is the deliberate fostering of an effective data culture. This involves leadership reinforcing the data strategy from the top down, democratizing access to data, and investing in continuous learning and upskilling to enhance data literacy across the organization. Second is the modernization of their data ecosystem for the cloud, moving away from legacy systems to a scalable foundation that can handle modern data demands.
Third, and most critically, Capital One insists on strong data management and governance practices to ensure data is well-understood and trusted. This includes knowing the data's origin (lineage), its substance, the changes made to it over time, and who can access it. By centralizing governance policies and tools, they make it easier for teams across the company to use data in a secure and compliant manner. This strategic focus on well-governed data as a foundational asset directly translates into measurable business value. By automating data quality and governance, organizations can rebuild trust in their analytics and save millions of dollars annually that would otherwise be lost to the costs of poor data quality. Capital One's journey illustrates the ultimate "why" of DataOps: to transform data from a raw, chaotic resource into a well-managed, secure, and strategic asset that drives business value.
Conclusion: From Data Operations to Strategic Advantage
8.1 Synthesis of Key Findings
The comprehensive analysis presented in this report leads to an unequivocal conclusion: DataOps is a holistic and transformative discipline, not a piecemeal technical upgrade. Its successful implementation rests upon a balanced and sustained investment in three interdependent pillars: a collaborative culture, agile processes, and automated technology. The evidence clearly indicates that a technology-centric approach, which neglects the profound cultural and procedural shifts required, is destined for failure. The journey from traditional data management to a mature DataOps capability is a strategic transformation that redefines the role of data within the enterprise, elevating it from a passive byproduct of business operations to the central nervous system of data-driven decision-making. The core principles of breaking down silos, treating data as a product, embedding quality and governance by design, and relentlessly automating the data lifecycle are not merely best practices but essential components of a modern, competitive data strategy.
8.2 The Future of DataOps
The evolution of DataOps is ongoing, driven by technological innovation and the increasing demands of the digital economy. Several key trends are shaping its future. The integration of Generative AI into DataOps platforms is poised to further accelerate development, with AI-powered assistants helping to generate pipeline code, create data quality tests from natural language, and enhance data discovery within catalogs. This will lower the technical barrier to entry and further augment the productivity of data teams. Concurrently, the push towards democratizing data and enabling true self-service analytics will continue. As robust DataOps frameworks provide a secure and reliable backbone of trusted data, organizations will be able to safely empower more business users with the tools and access they need to answer their own questions, reducing the dependency on centralized data teams and fostering a truly data-literate culture. The principles of DataOps will also become increasingly critical as data processing moves to the edge, requiring automated, resilient, and observable pipelines to manage data in highly distributed environments.
8.3 Final Call to Action
For enterprise leaders, the imperative is clear. DataOps should not be viewed as a cost center or a discretionary IT project. It must be recognized as a fundamental, ongoing business capability that is as critical to modern commerce as supply chain management or financial operations. In an economic landscape where agility, insight, and data-driven customer experiences are the primary drivers of competitive differentiation, the ability to rapidly and reliably deliver high-quality, trusted data is no longer an operational efficiency—it is a strategic necessity. The organizations that commit to the cultural, procedural, and technological transformation of DataOps will not only survive but will be the ones that thrive and lead in the coming decade. The time to begin building the DataOps blueprint is now.