What is Machine Unlearning? Why does it matter?
Machine Unlearning (MU) is rapidly emerging as a critical capability for the development, deployment, and governance of modern artificial intelligence systems. It is the process of selectively removing the influence of specific training data from a trained model without the prohibitive cost and time of complete retraining.


Machine Unlearning (MU) is rapidly emerging as a critical capability for the development, deployment, and governance of modern artificial intelligence systems. It is the process of selectively removing the influence of specific training data from a trained model without the prohibitive cost and time of complete retraining. This "subtractive" capability addresses a confluence of pressing regulatory, ethical, and business imperatives that define the current AI landscape.
The primary driver for machine unlearning is regulatory compliance, most notably the "Right to be Forgotten" enshrined in laws like the EU's General Data Protection Regulation (GDPR). These frameworks mandate that individuals can request the erasure of their personal data, a right that extends to the indelible imprints their data leaves on complex ML models. As retraining large models to honor individual requests is operationally infeasible, unlearning provides the only practical path to compliance.
Beyond legal mandates, unlearning is a powerful tool for maintaining model integrity and trustworthiness. It enables the surgical removal of biased data to enhance fairness, the excision of malicious data from poisoning attacks to improve security, and the deletion of outdated information to maintain model relevance and accuracy. For businesses, it offers a crucial mechanism to manage intellectual property risk by removing inadvertently learned copyrighted material and to uphold data lifecycle agreements with partners and clients.
Technically, unlearning methodologies are broadly categorized into two paradigms, each with a distinct trade-off profile. Exact Unlearning provides provable, auditable guarantees that a data point's influence has been completely removed, making the unlearned model identical to one retrained from scratch. This is typically achieved through architectural designs like the Sharded, Isolated, Sliced, and Aggregated (SISA) framework, which comes at the cost of higher upfront complexity and potential impacts on model utility. In contrast, Approximate Unlearning offers a suite of more flexible and scalable techniques—including influence-based removal, gradient reversal, and optimization-based fine-tuning—that efficiently minimize a data point's influence. While better suited for large-scale models, these methods provide weaker, heuristic guarantees that necessitate robust, independent verification.
Successfully implementing machine unlearning requires its deep integration into the enterprise AI lifecycle. This report outlines a strategic framework for this integration, emphasizing the operationalization of unlearning within MLOps pipelines, triggered automatically by consent management systems. It further provides guidance on calculating the return on investment (ROI) by evaluating both cost savings from avoided retraining and the value of mitigated legal and reputational risks. The most significant challenge in this domain is verification: proving that the act of forgetting was successful. This requires a multi-faceted auditing strategy employing techniques like Membership Inference Attacks (MIAs), perturbation analysis, and emerging methods from Explainable AI (XAI).
Ultimately, machine unlearning is not merely a technical tool but a foundational component for building responsible, adaptable, and trustworthy AI. It represents a paradigm shift toward treating data not as a one-time consumable but as a revocable asset, forcing organizations to embed privacy and governance into the very architecture of their AI systems. For technical leaders, developing a mature unlearning capability is becoming an indispensable step in navigating the complexities of the modern AI ecosystem.
I. The Unlearning Imperative: Foundational Concepts and Strategic Drivers
This section establishes the fundamental rationale behind machine unlearning, moving from its core definition to the powerful market, regulatory, and ethical forces compelling its adoption. It clarifies why simple data deletion is insufficient and details the primary catalysts driving the field forward.
1.1. Defining Machine Unlearning: Beyond Simple Data Deletion
At its core, machine unlearning is the process of selectively removing the influence of specific training data points from a trained machine learning model without needing to retrain the entire model from scratch. It provides a "subtractive" capability that stands in direct contrast to the additive nature of conventional model training. The goal is to produce an updated model that behaves, for all intents and purposes, as if it were never trained on the "forgotten" data in the first place.
This distinction is critical and represents a fundamental challenge in modern AI. Unlike a traditional database where information is stored in discrete, identifiable, and retrievable rows, knowledge in a machine learning model is diffuse. During training, information from data points is encoded and deeply embedded across millions or even billions of parameters (the model's weights and biases) in a highly entangled, non-localized manner. As one researcher noted, deleting data from a trained Large Language Model (LLM) is "more like trying to retrieve a whole strawberry from a smoothie". Simply deleting the source data from a storage disk does nothing to erase the patterns, correlations, and knowledge that the model has already learned from it. An AI model can continue to "remember" and generate outputs based on this learned information long after the original data is gone.
This technical reality has given rise to a new vocabulary. While "machine unlearning" is the umbrella term, more specific phrases like "model editing," "concept editing," and "knowledge unlearning" are emerging, particularly in the context of LLMs. These terms reflect the evolving nature of the task, where the target for removal is often not a specific data point (e.g., a user's record) but an abstract concept (e.g., a copyrighted character), a harmful bias, or a dangerous capability.
This entire field signifies a profound paradigm shift in how data is viewed in the context of AI. The traditional model treated training data as a "consumable"—a raw material that is used up during the training process, with its value permanently transferred to the model. Machine unlearning provides the technical underpinnings for a new model: one where data is a "revocable asset." It acknowledges that data is often "borrowed" and must be "returned" upon request, giving data owners meaningful control over their information even after it has been used. This shift has far-reaching consequences, compelling organizations to re-architect their data governance and operational pipelines to accommodate this new reality of data lifecycle management.
1.2. The Regulatory Catalyst: The Right to be Forgotten and Global Privacy Frameworks
The most powerful external force driving the adoption of machine unlearning is the global rise of data privacy regulation. Legislations such as the European Union's General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA) have fundamentally altered the responsibilities of organizations that collect and process personal data.
Central to these regulations is the "Right to be Forgotten" or "Right to Erasure," explicitly codified in Article 17 of the GDPR. This right empowers individuals to request the deletion of their personal data under various circumstances, such as when the data is no longer necessary for its original purpose or when consent is withdrawn. Data protection authorities are increasingly clarifying that this right is not limited to deleting data from databases but extends to removing the influence of that data from trained machine learning models.
This presents a monumental operational challenge. For the complex, large-scale models that power modern enterprise AI, the naive solution—retraining the model from scratch on a dataset that excludes the user's data—is economically and computationally infeasible. Retraining a foundation model can take months and cost millions of dollars in compute resources. Executing this process for every individual data removal request is simply not a viable business strategy.
Machine unlearning, therefore, emerges not merely as an efficient alternative but as a practical necessity for compliance. It offers a targeted, cost-effective method to honor data erasure requests in a timely manner ("without undue delay," as stipulated by the GDPR), thereby avoiding potentially massive fines and legal liability.
Beyond strict legal compliance, the ability to effectively unlearn data is a cornerstone of building user trust. In an era of increasing public skepticism about how personal data is used, providing users with tangible control over their information is a powerful differentiator. Organizations that can demonstrably honor erasure requests build transparency and foster a positive public image, which can in turn encourage users to share the high-quality data that is essential for building state-of-the-art AI systems.
1.3. The Model Integrity Catalyst: Correcting Errors, Bias, and Poisoning
While regulatory pressures are a primary driver, a second, equally important set of motivations for machine unlearning stems from the need to maintain the integrity, security, and performance of the model itself. These use cases are evolving from reactive compliance measures to proactive strategies for model governance and quality assurance.
Data Correction and Adaptability: Machine learning models are not static artifacts. A model trained on a fixed dataset can quickly become outdated or inaccurate as the real-world data distribution it operates on shifts over time. Customer preferences evolve, market trends change, and information becomes obsolete. Machine unlearning provides a mechanism for dynamic model maintenance, allowing practitioners to surgically remove the influence of outdated or unrepresentative data points, thereby keeping the model relevant and performant without the need for periodic, full-scale retraining.
Bias and Fairness Mitigation: One of the most significant ethical challenges in AI is that models can learn and amplify harmful societal biases present in their training data. This can lead to discriminatory outcomes in high-stakes applications like hiring, lending, or criminal justice. Machine unlearning offers a powerful tool for remediation. When an audit reveals that a model is exhibiting bias—for example, a recruiting model that unfairly penalizes candidates from a certain demographic—unlearning techniques can be used to identify and surgically remove the influence of the specific data points or spurious correlations that are causing the biased behavior. This allows for the correction of fairness issues in deployed models, leading to more equitable and trustworthy AI systems.
Security and Robustness: AI models are vulnerable to a class of security threats known as data poisoning attacks. In such an attack, an adversary intentionally injects malicious or manipulated data into the training set to corrupt the model's behavior. For instance, an attacker could introduce samples with a hidden "backdoor" trigger, causing the model to misclassify any input containing that trigger. Machine unlearning serves as a critical post-hoc defense mechanism. Once poisoned data is identified, unlearning algorithms can be used to erase its influence, effectively neutralizing the attack and restoring the model's integrity without starting over from scratch.
1.4. The Business Catalyst: Managing Copyright, Data Freshness, and IP
A final set of drivers is rooted in direct business and operational imperatives, particularly concerning intellectual property and data lifecycle management.
Copyright and IP Protection: Large Language Models, often trained on vast, unfiltered scrapes of the public internet, frequently memorize and reproduce copyrighted content, including text from books, articles, and source code. This exposes their deployers to significant legal and financial risk from copyright infringement claims. Machine unlearning provides a crucial remedial tool to "forget" this protected material after the fact. The well-publicized case of Microsoft researchers making Meta's Llama2 model forget details from the Harry Potter series is a landmark example of this capability in action, demonstrating a path to mitigating IP liability in deployed models.
Data Licensing and Lifecycle Management: In many enterprise contexts, data is not owned outright but is used under specific terms and conditions. This includes data licensed from third-party providers for a finite period or data from clients of a service. When a license expires or a client terminates their contract—for instance, a hospital leaving a consortium that shares data for medical research—there is a contractual and ethical obligation to cease using their data. Machine unlearning provides the mechanism to remove the influence of this data from all shared models, ensuring compliance with data usage agreements.
This evolution of drivers—from reactive legal compliance to proactive model improvement and strategic risk management—shows that machine unlearning is transitioning from a niche academic concept to a core competency for any organization deploying AI at scale. It is becoming less of a defensive tool for the legal department and more of an essential instrument for the ML engineering team to build better, safer, and more valuable models.
II. A Taxonomy of Unlearning Methodologies: From Theoretical Guarantees to Practical Approximations
The technical approaches to machine unlearning can be understood through a foundational dichotomy that shapes the entire field. This section provides a detailed taxonomy of these methodologies, exploring the core trade-offs, mechanisms, and applicability of each major approach.
2.1. The Fundamental Dichotomy: Exact vs. Approximate Unlearning
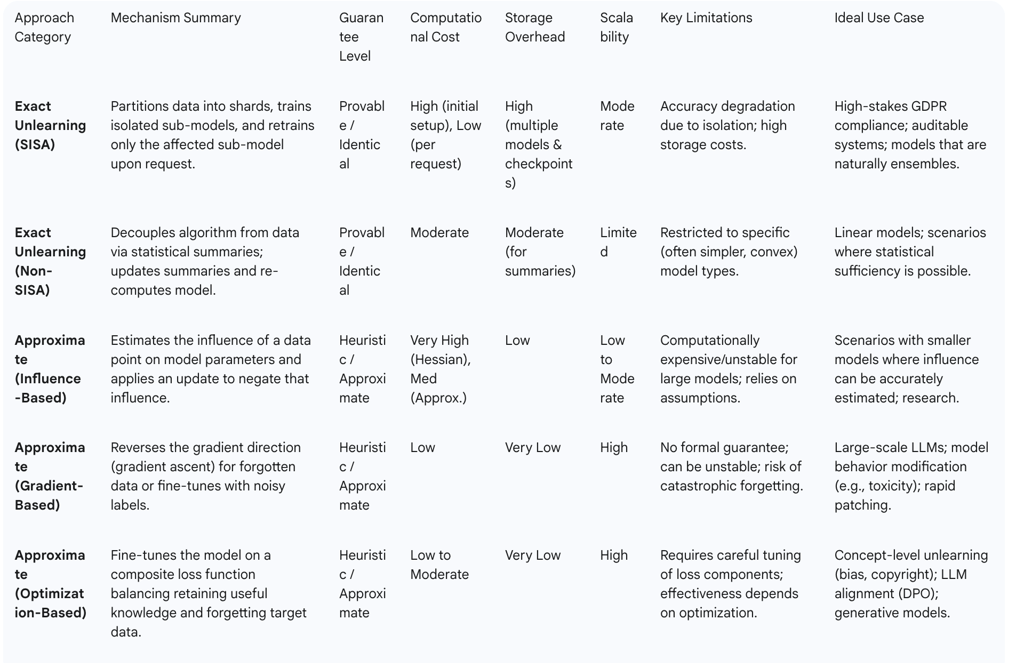
The landscape of machine unlearning techniques is fundamentally structured around a central trade-off between the completeness of data removal and the efficiency of the unlearning process in terms of computational cost, time, and storage requirements. This trade-off gives rise to two distinct categories of methods: exact unlearning and approximate unlearning.
Exact Unlearning, also known as provable unlearning, aims to produce an updated model whose parameter distribution is identical to that of a model retrained from scratch on the dataset excluding the forgotten data. This approach offers the strongest possible guarantee of removal; the unlearning algorithm itself, by its very design, serves as the auditable proof that the data's influence has been completely nullified. However, these strong guarantees typically come at a price: exact unlearning methods are often more computationally expensive, may require significant additional storage, and can impose specific, sometimes restrictive, architectural constraints on the model.
Approximate Unlearning, in contrast, prioritizes efficiency and scalability. Its goal is to efficiently minimize or reduce the influence of the forgotten data to a practically acceptable, often negligible, level rather than guaranteeing its complete elimination. These methods are generally faster, more flexible, and more readily applicable to the large, complex, monolithic models (like LLMs) where exact unlearning is impractical. The trade-off is a weaker, often heuristic, guarantee of removal. The effectiveness of an approximate unlearning operation cannot be taken for granted and must be validated through external verification and auditing procedures.
The choice between these two paradigms is a critical strategic decision, depending on the specific application's requirements for legal defensibility, model architecture, and operational constraints.
2.2. Exact Unlearning: Architecting for Forgetfulness
Exact unlearning methods achieve their provable guarantees by structuring the training process itself in a way that facilitates efficient data removal. Rather than being a post-hoc patch, forgetfulness is designed into the model's architecture from the outset.
2.2.1. The SISA Framework: Sharded, Isolated, Sliced, and Aggregated
The canonical and most widely cited exact unlearning approach is the SISA framework. It is an ensemble-based method that works by partitioning both the data and the model to isolate the influence of individual data points. The mechanism involves four key steps :
Sharding: The full training dataset is partitioned into a number of smaller, disjoint subsets known as shards.
Isolation: A separate, independent sub-model is trained exclusively on each shard. This is the crucial step: because the sub-models are trained in isolation, the influence of any single data point is strictly confined to the one sub-model trained on the shard containing that point.
Aggregation: During inference, the predictions from all the independent sub-models are aggregated to produce a final output. This aggregation can be done via methods like majority voting for classification tasks or averaging for regression tasks.
Unlearning Process: When a request to unlearn a data point arrives, the system identifies which shard contains that point. Then, only the single, small sub-model corresponding to that shard needs to be discarded and retrained from scratch on its shard, now excluding the forgotten point. Since this involves retraining a much smaller model on a much smaller dataset, it is significantly faster and cheaper than retraining the entire monolithic ensemble.
To further enhance efficiency, SISA can be augmented with Slicing. In this extension, each data shard is further divided into even smaller "slices." During the training of a sub-model, its parameters (or state) are saved as a checkpoint after each slice is processed. When an unlearning request is received, the retraining of the affected sub-model does not have to start from a random initialization. Instead, it can be rewound to the last saved checkpoint before the forgotten data point was introduced, saving considerable training time.
The primary trade-off of the SISA framework is a potential degradation in model utility or accuracy compared to a single model trained on all the data at once. The isolation of sub-models prevents them from learning from patterns and interactions that span across shards. Additionally, SISA introduces significant storage overhead due to the need to store multiple sub-models and, if slicing is used, numerous checkpoints.
2.2.2. Applications and Variants of Exact Unlearning
The core principles of SISA have been adapted to create exact unlearning methods for various model architectures:
For Random Forests: In a random forest, each decision tree can be treated as a SISA sub-model. Unlearning a data point only requires retraining the specific trees that used that point in their training bootstrap sample. Techniques like DaRE and HedgeCut optimize this process further for tree-based ensembles.
For Graph Models: For graph-structured data where nodes are highly interconnected, frameworks like GraphEraser and RecEraser adapt SISA by using intelligent graph partitioning algorithms. They divide the large graph into smaller subgraphs, train an isolated Graph Neural Network (GNN) on each, and then aggregate their outputs. Unlearning a node or edge only requires retraining the affected subgraph model.
For Federated Learning: In federated learning, where data is naturally distributed across clients, the KNOT framework applies SISA principles by grouping clients into clusters. An unlearning request from a client only necessitates retraining among the models within that client's cluster, not across the entire federated network.
Non-SISA Approaches: Other exact unlearning methods exist that do not rely on ensembling. The "summations-based" approach, for example, works for certain linear models. It decouples the learning algorithm from the raw data by first computing intermediate statistical summaries (summations). The model is trained on these summaries. To unlearn a data point, one simply updates the summaries—a much faster operation than iterating over the dataset—and then re-computes the final model from the updated summaries.
2.3. Approximate Unlearning: A Spectrum of Heuristic Techniques
Approximate unlearning methods eschew the strict architectural constraints of exact unlearning in favor of flexibility and speed. They operate directly on a pre-trained model and use various heuristics to approximate the effect of removing a data point.
2.3.1. Influence-Based Removal: Calculating and Countering Impact
This class of methods is based on a concept from robust statistics called influence functions. An influence function mathematically estimates the impact that a single training point had on the final parameters of the trained model. The unlearning process leverages this concept as follows:
Calculate the influence of the data point(s) to be forgotten on the model's parameters.
Apply a parameter update to the model in the opposite direction of that influence. This is often done via a single Newton-Raphson step, effectively "canceling out" or nullifying the data's original contribution.
The primary challenge of this approach is its computational complexity. A precise calculation of the influence function requires computing and inverting the Hessian matrix (the matrix of second-order partial derivatives of the loss function), which is computationally infeasible for modern deep neural networks with millions of parameters. Consequently, research in this area focuses on developing efficient methods to approximate the Hessian, or on techniques like L-CODEC that identify a small but critical subset of model parameters to update, avoiding the need to invert a massive matrix.
2.3.2. Gradient-Based Forgetting: Reversing the Learning Process
This is a family of intuitive and widely used approximate unlearning techniques. Instead of complex influence calculations, they manipulate the gradients used during fine-tuning to achieve forgetting. Common variants include:
Gradient Reversal (or Gradient Ascent): The model undergoes a fine-tuning process. For data in the "retain set," standard gradient descent is used to maintain performance. However, for data in the "forget set," the sign of the gradient is flipped. This is called gradient ascent. It actively pushes the model's parameters away from the configuration that minimized loss for the forgotten data, effectively forcing the model to unlearn it.
Random Labeling: In this technique, the data points in the forget set are assigned incorrect, random labels. The model is then fine-tuned on this modified dataset. By being trained to associate the forgotten data with noise, the model's original, correct memory of that data is disrupted and "confused". IBM's work on reducing toxicity in LLMs with their SPUNGE framework is an example of such gradient-based approaches being used in practice.
2.3.3. Optimization-Based Approaches: Fine-tuning and Boundary Shifting
These methods reframe unlearning as a new, multi-objective optimization problem. The goal is to fine-tune the original model to find a new set of parameters that simultaneously satisfies several objectives, which are combined into a composite loss function. This loss function typically includes:
A Retain Loss: A term that encourages the model to maintain its accuracy and performance on the data in the retain set (Dr). This prevents catastrophic forgetting of useful knowledge. The loss is often written as Lr(θ).
A Forget Loss: A term that encourages the model to perform poorly on the data in the forget set (Df). This could be by maximizing the prediction error on Df. The loss is often written as Lf(θ).
This general framework encompasses a range of techniques, from simple fine-tuning on only the retain set to more sophisticated methods. In the context of LLMs, Direct Preference Optimization (DPO) has emerged as a powerful technique. Here, the model is trained to prefer generating "unlearned" or counterfactual responses over the original, factual responses related to the forgotten knowledge. Another novel approach, "boundary unlearning," operates not on the model's parameters directly but on its decision space. Instead of trying to change the model's internal representations, it works to shift the model's decision boundary to exclude the forgotten class, for instance, by reassigning the forgotten data to its nearest neighboring class during a short fine-tuning process.
Table 1: Comparative Analysis of Machine Unlearning Approaches
The following table provides a strategic overview of the primary unlearning methodologies, comparing them across key criteria to aid technical leaders in selecting the appropriate approach for their specific needs.
III. Strategic Implementation Framework: Integrating Unlearning into the Enterprise AI Lifecycle
Adopting machine unlearning is not merely a matter of selecting an algorithm. To be effective, reliable, and scalable, unlearning must be treated as a core operational capability, deeply integrated into the enterprise's existing AI development and governance workflows. This section provides an actionable framework for this integration, covering MLOps, business justification, and practical decision-making.
3.1. From Lab to Production: Integrating Unlearning into MLOps
Machine unlearning cannot succeed as an ad-hoc, manual process performed by data scientists on a case-by-case basis. To handle requests efficiently and ensure auditable compliance, it must be operationalized within a standardized, automated Machine Learning Operations (MLOps) pipeline. This requires a fundamental "shift left" in thinking about privacy, moving it from a post-deployment legal concern to a core engineering principle embedded in the system's architecture from day one.
3.1.1. A Formal Model for Consent Management in the MLOps Pipeline
The foundation of an operationalized unlearning system is the principle of Privacy by Design (PbD), which mandates that privacy and data protection be considered upfront in the system's design. A practical way to achieve this is by formally integrating a Consent Management (CM) system directly into the MLOps pipeline.
This integration can be modeled using formal state machines to govern the entire data and model lifecycle. For instance:
A Consent Management State Machine (CMSM) tracks the status of each data subject's consent (e.g., Granted, Revoked, Expired).
A Machine Learning Operations State Machine (MOSM) orchestrates the ML workflow (e.g., PrepareData, TrainModel, DeployApplication) and includes events that are contingent on consent status.
In this model, the CM system acts as an automated trigger for unlearning. When a user revokes their consent through a privacy dashboard or a data retention policy automatically flags data for deletion, a monitorConsentViolation event is fired. This event should programmatically initiate the unlearning workflow: the user's data is added to a "forget set," and the corresponding unlearning pipeline is triggered for all affected models. This automated, event-driven approach ensures that unlearning requests are handled reliably and provides a clear, auditable trail for regulatory purposes. It transforms privacy compliance from a manual checklist item into an automated, engineered process.
3.1.2. The Unlearning Pipeline in MLOps
A mature MLOps pipeline that incorporates unlearning would follow a structured, automated sequence of steps:
Request Ingestion: The process begins when an unlearning request is received. This can be triggered automatically by the CM system, manually by an administrator in response to a legal notice (e.g., copyright takedown), or by an internal audit that flags biased or poisoned data.
Forget Set Identification: The system must translate the abstract request into a concrete set of data points to be forgotten (Df) and the corresponding set of data to be retained (Dr). This step is critically dependent on robust data governance and lineage tools that can accurately trace which data was used to train which version of which model.
Unlearning Execution: The MLOps pipeline invokes the appropriate unlearning algorithm, which has been pre-selected based on the model's architecture and the nature of the request. This could involve triggering a retraining job for a specific SISA shard or executing an approximate unlearning script on a deployed LLM.
Verification and Auditing: After the unlearning algorithm has run, the newly generated "unlearned model" is not immediately promoted. Instead, it is passed to an automated verification stage (detailed in Section IV). This stage runs a battery of tests to confirm the quality of forgetting (e.g., using MIAs) and to check for any unacceptable degradation in model utility on the retain set.
Model Deployment: Only if the model passes the verification stage is it versioned and promoted to production, replacing the previous model. The entire workflow, from request to deployment, including the verification results, is meticulously logged in the model registry to ensure full auditability.
3.2. The Business Case: Calculating the Return on Investment (ROI) for Unlearning
For technical leaders to secure budget and resources, a clear business case for investing in unlearning capabilities is essential. The Return on Investment (ROI) for unlearning can be framed through two primary lenses: cost savings and risk mitigation.
Unlearning as a Cost-Saving Mechanism: The most direct and quantifiable ROI comes from comparing the cost of implementing and running an unlearning pipeline against the staggering cost of full, periodic retraining. Case studies provide compelling evidence: IBM's unlearning process on a Llama model took 224 seconds, whereas retraining would have taken months. Research on the SISA framework has shown speed-ups of 2.45x to 4.63x over retraining from scratch for certain datasets. These savings in compute cost, energy consumption, and engineering time are substantial and can be readily calculated.
Unlearning as Risk Mitigation: A more comprehensive ROI analysis must also quantify the value of mitigated risks. While harder to assign a precise dollar value, these are often the most significant drivers of investment. The calculation should attempt to model the potential financial impact of:
Regulatory Fines: GDPR fines can be as high as 4% of an organization's annual global turnover. The cost of an unlearning system is a form of insurance against this catastrophic risk.
Litigation and Settlements: Deploying models that infringe on copyright or violate data usage agreements can lead to costly legal battles. Unlearning provides a tool to remediate these issues and reduce legal exposure.
Reputational Damage: The public fallout from deploying a biased, unfair, or privacy-violating AI system can lead to customer churn, loss of trust, and a decline in brand value.
A break-even analysis can also be a powerful tool. By formalizing the value generated by each correct prediction and the cost incurred by each mistake, one can calculate the minimum model accuracy required for an unlearning-enabled system to be profitable. This shifts the conversation from a vague goal of "perfect unlearning" to a concrete business objective of maximizing ROI.
3.3. Selecting the Right Approach: A Decision-Making Heuristic
With a diverse landscape of unlearning techniques available, technical leaders need a practical framework for choosing the right method for a given situation. The following decision-making heuristic can guide this selection process:
Is a provable, legally defensible guarantee of removal the top priority? (e.g., for handling personal data under GDPR).
Yes: Prioritize Exact Unlearning methods like SISA. The architectural overhead and potential accuracy trade-off are the price paid for the auditable guarantee.
No: Proceed to the next question.
What is the model architecture?
Massive, monolithic model (e.g., a foundation LLM): Approximate Unlearning is likely the only feasible option. Focus on scalable techniques like gradient-based or optimization-based methods.
Ensemble model (e.g., Random Forest) or a model that can be easily sharded: Exact Unlearning via SISA is a strong candidate.
What is the primary unlearning target?
Specific, individual data points: Influence-based or gradient-based methods are well-suited for this task.
An entire class, concept, or behavior (e.g., removing bias against a demographic, forgetting copyrighted content, reducing toxicity): Optimization-based methods (like DPO) or boundary unlearning are generally more effective.
A security threat (e.g., data poisoning): Look for specialized approximate methods designed for backdoor removal.
What are the operational constraints (compute, storage, latency)?
High constraints / Low budget: Favor low-overhead approximate methods like gradient-based approaches. Avoid storage-heavy exact methods (SISA with slicing) or compute-intensive ones (influence functions requiring Hessian inversion).
3.4. Industry in Action: Case Studies
Major technology companies are actively investing in and applying machine unlearning, validating its strategic importance:
Microsoft: In a landmark study, researchers successfully used an approximate unlearning method to make Meta's Llama2-7b model forget copyrighted knowledge from the Harry Potter books. This demonstrated the feasibility of using unlearning for IP compliance in LLMs.
IBM: Researchers at IBM have developed the SPUNGE framework and applied unlearning techniques to Llama models to significantly reduce the generation of toxic content. This showcases the use of unlearning for model safety and behavior alignment.
Google: Google has actively promoted research in this area by launching a machine unlearning challenge. The competition focused on making an age-prediction model, trained on face images, forget a subset of individuals, highlighting the critical application of unlearning for user privacy in computer vision.
JP Morgan Chase: In collaboration with academic researchers, the financial giant is exploring unlearning for image-to-image generative models. A key use case is to protect privacy by removing sensitive content, such as the faces of children, from images captured for real estate analysis.
These examples illustrate that machine unlearning is moving beyond theoretical research and is being applied to solve real-world problems in privacy, safety, and compliance across various industries. However, a notable tension is emerging between unlearning and the popular Retrieval-Augmented Generation (RAG) architecture. While some propose RAG as an alternative to unlearning (by simply deleting information from the external database), this approach introduces its own challenges. Ensuring the complete removal of all paraphrases and adaptations of content from a vector database is a difficult deduplication problem. More importantly, the act of placing sensitive information into a model's context window during retrieval can make it more vulnerable to direct extraction attacks, creating a new and potentially more severe privacy risk. This highlights a crucial strategic trade-off for AI architects between the difficulty of unlearning from model parameters and the potential vulnerabilities of a RAG-based approach.
IV. The Audit and Verification Challenge: Proving the Act of Forgetting
Implementing an unlearning algorithm is only the first step. The most critical and scientifically challenging aspect of machine unlearning is verification: how can an organization prove, to itself and to external auditors, that the targeted information has truly been forgotten? Without robust verification, unlearning is merely an unsubstantiated claim.
4.1. The Three Pillars of Evaluation: Forgetting Quality, Model Utility, and Efficiency
A successful and practical unlearning algorithm must be evaluated against a balanced set of competing objectives. Any evaluation framework must holistically assess the trade-offs between three pillars :
Forgetting Quality: This is the primary goal. It measures how completely and effectively the influence of the target data has been removed from the model. The ideal unlearned model should be indistinguishable from a model that was never exposed to the forgotten data.
Model Utility: This measures the impact of the unlearning process on the model's performance on all other tasks. The unlearning process should not significantly degrade the model's accuracy on the retained data or its general capabilities. An unlearning method that erases the target data but cripples the model's overall usefulness is a failure.
Efficiency: This quantifies the operational cost of the unlearning process. Key metrics include the time, computational resources (CPU/GPU hours), and storage required to perform the unlearning, evaluated relative to the cost of a full retraining.
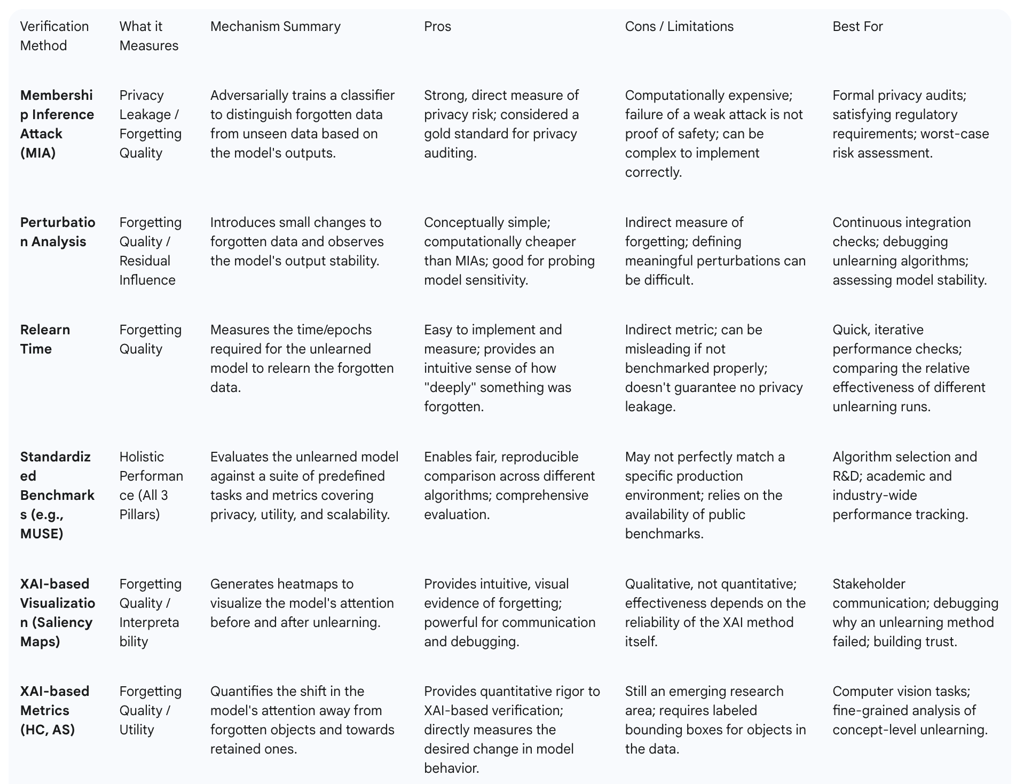
4.2. Adversarial Probing: Membership Inference Attacks (MIAs) as an Audit Tool
The primary technique used to audit the privacy aspect of forgetting quality is the Membership Inference Attack (MIA). An MIA is an adversarial method that aims to determine whether a specific data point was part of a model's original training set by analyzing the model's outputs.
The application to unlearning is straightforward: after an unlearning algorithm has been applied, a powerful MIA is launched against the unlearned model. The attack attempts to distinguish the "forgotten" data points from a set of "holdout" data points that the model has genuinely never seen. If the MIA can distinguish the forgotten data with an accuracy significantly better than random chance, it implies that some trace or influence of that data remains in the model, and the unlearning process has failed.
A common method for implementing a sophisticated MIA involves training shadow models. The process works as follows:
The attacker trains multiple "shadow" models that mimic the architecture and training process of the target model. These are trained on datasets where the membership of each data point is known to the attacker.
The attacker uses the outputs of these shadow models (e.g., prediction confidence scores) to train a separate "attack model," which is a binary classifier. This attack model learns to recognize the subtle statistical differences in a model's output for data it was trained on versus data it was not.
Finally, this trained attack model is deployed against the target unlearned model to infer the membership of the forgotten data points.
While powerful, MIAs have challenges. They can be computationally expensive to execute, especially those requiring many shadow models. Furthermore, the strength of the conclusion depends entirely on the strength of the attack; the failure of a weak MIA to find information leakage does not prove its absence. It is also crucial to consider that the unlearning process itself might inadvertently increase the privacy risk for the retained samples, an aspect that also needs to be audited.
4.3. Beyond MIAs: Perturbation Analysis, Relearning Time, and Benchmarks
Given the limitations of MIAs, a comprehensive verification strategy should employ a diverse set of techniques:
Perturbation Analysis: This method probes for residual influence by making small, semantically meaningless changes (perturbations) to a forgotten data point and feeding it to the unlearned model. If the model's output changes significantly in response to these minor perturbations, it suggests that the model still retains a sensitive "memory" of the original data's structure. A truly unlearned model should be indifferent to such small changes.
Relearn Time: This is a practical, efficiency-based metric. After unlearning a set of data, this metric measures the number of training epochs required for the model to regain its original level of accuracy on that same data. The intuition is that if the data has been truly forgotten, it should take the model longer to relearn it, similar to learning it from scratch. A short relearn time suggests that residual knowledge remained, giving the model a "head start".
Standardized Benchmarks: To drive progress and enable fair, reproducible comparisons between different unlearning algorithms, the research community is developing standardized evaluation benchmarks. A leading example is MUSE (Machine Unlearning Six-Way Evaluation). MUSE provides a comprehensive framework that assesses algorithms against six key properties covering all three pillars: (1) no verbatim memorization, (2) no knowledge memorization, (3) no privacy leakage (via MIA), (4) utility preservation, (5) scalability with the size of the forget set, and (6) sustainability over sequential unlearning requests. Other specialized benchmarks, like MMUBench for multimodal models, are also emerging.
4.4. The Transparency Frontier: Using Explainable AI (XAI) to Visualize Forgetting
A promising new frontier in unlearning verification involves leveraging techniques from Explainable AI (XAI). Instead of just looking at the model's final output, XAI methods can provide a window into the model's internal reasoning process.
Attribution-based XAI methods, such as those that generate saliency maps or heatmaps, can be particularly useful. These techniques highlight which features or regions of an input the model is "paying attention to" when making a prediction. In the context of unlearning, an auditor can compare a model's attention maps before and after the unlearning process. For example, if the task was to unlearn a specific person's face from a model trained to identify objects in a scene, a successful unlearning operation would be visually confirmed if the post-unlearning heatmap no longer shows any focus on the area of the image where that person was located.
This qualitative visual inspection can be augmented with new quantitative, XAI-based metrics, such as :
Heatmap Coverage (HC): Measures how well the model's attention is focused on the correct, retained objects after unlearning.
Attention Shift (AS): Quantifies the degree to which the model's focus has successfully shifted away from the forgotten objects and towards the relevant, retained objects.
Table 2: Unlearning Verification and Auditing Techniques
This table summarizes the key verification techniques, providing technical leaders with a menu of options for designing a robust auditing strategy for their unlearning systems.
V. The Frontier of Unlearning: Open Problems, Research Horizons, and Future Outlook
While machine unlearning has made significant strides, it remains a nascent field with formidable open challenges. As organizations move towards implementation, they must be aware of the inherent limitations and the active areas of research that will shape the future of this technology.
5.1. The Specter of Catastrophic Unlearning
One of the most significant risks in applying approximate unlearning methods is a phenomenon known as catastrophic unlearning or catastrophic forgetting. This occurs when the process of removing a small amount of targeted information leads to a disproportionately large, and sometimes exponential, degradation in the model's overall performance on the data it was supposed to retain.
This represents the most severe manifestation of the trade-off between forgetting quality and model utility. An overly aggressive unlearning algorithm might successfully erase the target data but render the model useless for its primary task in the process. This risk is particularly acute in production systems where model reliability and performance are paramount. Preventing catastrophic unlearning, especially during iterative unlearning where requests are processed sequentially, remains a major open research problem and a critical consideration for practical deployment.
5.2. Knowledge Entanglement: The Difficulty of Surgical Removal
The core difficulty of unlearning in complex models like deep neural networks stems from knowledge entanglement. In these models, information is not stored in neat, discrete locations. Instead, concepts are represented in a distributed and highly entangled manner across millions of parameters. A single neuron or weight can contribute to the representation of many different concepts.
This entanglement makes true "surgical" removal of a single piece of knowledge incredibly challenging. The attempt to erase one concept (e.g., a copyrighted character like Harry Potter) can have unpredictable and damaging side effects on related, benign concepts (e.g., the broader genre of fantasy novels or the concept of a "wizard"). This means that the unlearning process often acts more like a blunt instrument than a precision scalpel, with a high risk of "over-unlearning" and causing unintended collateral damage to the model's useful capabilities. This is not merely an algorithmic flaw but a reflection of our fundamental lack of understanding of how deep neural networks represent knowledge. The challenges of unlearning are deeply intertwined with the challenges of mechanistic interpretability; a true breakthrough in one may be necessary for a breakthrough in the other.
5.3. Unlearning in Large Language Models (LLMs) and Generative AI
The rise of LLMs and other large-scale generative models presents a unique and amplified set of challenges for machine unlearning.
Scale and Cost: The sheer size of these models makes any process that involves parameter updates, let alone retraining, exceptionally expensive. Retraining a foundation model is almost always out of the question.
Abstract Targets: The target for unlearning in an LLM is frequently not a specific data point but an abstract "concept" (e.g., a bias), a "capability" (e.g., the ability to write malicious code), or a "behavior" (e.g., generating toxic language). Pinpointing the data responsible for these emergent properties is extremely difficult.
Generative Nature: Unlike classifiers, generative models can hallucinate or reconstruct information in novel ways. This makes verification harder; even if a model stops regurgitating a specific copyrighted passage, can it still generate text in the same style or about the same characters?
Consequently, research on unlearning for generative AI is heavily focused on efficient, approximate methods. These include fine-tuning with preference optimization techniques like DPO and NPO to steer the model's behavior, gradient-based methods to suppress undesirable outputs, and knowledge distillation. Key future research directions include developing methods for copyright unlearning that do not degrade model utility or increase hallucinations, designing techniques that are robust to adversarial jailbreak attacks, and finding novel ways to disentangle knowledge to allow for more precise removal.
5.4. Robustness and Security: Can Forgotten Knowledge be Reconstructed?
Perhaps the most profound open problem in unlearning for AI safety is the potential for a model to reconstruct forgotten knowledge. Even if an unlearning procedure is successful by current metrics, the model may retain enough fundamental, benign knowledge to re-derive the harmful capability it was supposed to forget. For example, a model that unlearns a specific, dangerous chemical synthesis pathway might still be able to reason its way back to that pathway from its general knowledge of chemistry. This limits the ultimate reliability of unlearning for mitigating dual-use risks.
Furthermore, the unlearning process itself introduces new security vulnerabilities. An adversary could launch a malicious unlearning attack by submitting carefully crafted data removal requests designed to degrade a competitor's model performance, introduce biases, or disable safety features. This transforms the unlearning API from a compliance tool into a potential attack surface that must be secured and monitored.
VI. Conclusive Analysis and Strategic Recommendations
Machine unlearning is rapidly transitioning from a niche academic pursuit to an indispensable capability for any organization serious about deploying AI responsibly, legally, and effectively. The confluence of stringent privacy regulations, the demand for trustworthy and fair models, and the operational need to manage data and IP risk has made "the ability to forget" a strategic imperative.
6.1. Synthesis of Key Findings
This report has established that machine unlearning is a complex, multi-faceted field defined by a core set of trade-offs. The choice between Exact Unlearning and Approximate Unlearning is a primary strategic decision, balancing the need for provable, auditable guarantees against the operational demands of scalability and flexibility. While exact methods like SISA offer the strongest legal defense, they impose architectural constraints that may be infeasible for many modern systems. Approximate methods are more versatile and scalable, especially for LLMs, but their heuristic nature shifts the burden to rigorous, multi-modal verification.
Successful implementation is not just an algorithmic challenge but a governance and operational one. It necessitates the deep integration of unlearning into automated MLOps pipelines, driven by robust data lineage and consent management systems. This represents a "shift left" for privacy and ethics, embedding them into the engineering lifecycle from day one. The business case for this investment is clear, resting on both the immense cost savings from avoiding full model retraining and the mitigation of catastrophic legal and reputational risks.
However, the most significant challenge remains verification. Proving that information has been truly forgotten is non-trivial. A robust auditing strategy is essential, combining adversarial techniques like Membership Inference Attacks with statistical methods, standardized benchmarks, and emerging visual verification through Explainable AI. Finally, the frontier of unlearning is fraught with deep scientific problems, including catastrophic forgetting, knowledge entanglement, and the potential for models to reconstruct forgotten capabilities, all of which underscore that this field is still in its early stages of development.
6.2. Actionable Recommendations for Technical Leaders
For technical leaders tasked with navigating this complex landscape, the following strategic recommendations provide a clear path forward:
Start Now, Start Small: Do not wait for a perfect, one-size-fits-all solution. Begin by implementing a pilot unlearning project for a non-critical, simpler model (e.g., a classifier rather than an LLM). This will allow your team to build crucial institutional knowledge about the algorithms, operational challenges, and verification processes in a low-risk environment.
Prioritize Governance Before Implementation: Recognize that effective unlearning is impossible without a solid data governance foundation. Before investing heavily in unlearning algorithms, invest in robust data lineage, cataloging, and consent management systems. You cannot unlearn what you cannot track.
Adopt a Risk-Based Approach to Method Selection: Use a decision framework, like the heuristic provided in Section 3.3, to match the unlearning methodology to the specific risk profile of the application. Use provable Exact Unlearning for high-risk scenarios involving sensitive personal data under strict regulation. Employ flexible Approximate Unlearning for lower-risk use cases like model maintenance, bias reduction, or for large-scale models where exact methods are impractical.
Build a Verification-First Culture: Treat the verification of unlearning not as an afterthought but as a mandatory release gate. Do not deploy an unlearning system without a corresponding, automated auditing pipeline. Your verification strategy should be multi-layered, combining quick checks (like relearn time) for continuous integration with more rigorous methods (like strong MIAs) for periodic, formal audits.
Stay Informed and Invest in Research: The field of machine unlearning is evolving at a rapid pace, with significant breakthroughs presented regularly at top AI conferences like NeurIPS and ICML. Dedicate resources—whether through an internal R&D team or by encouraging engineers to track academic literature—to stay abreast of the latest techniques, especially for challenging domains like LLMs and generative AI.
6.3. The Future of Responsible AI: Unlearning as a Core Capability
Ultimately, machine unlearning is more than a technical solution to a compliance problem. It is a foundational pillar of responsible AI. The ability to surgically remove information from AI systems is essential for creating models that are not only powerful but also adaptable, fair, secure, and respectful of individual rights. As AI becomes more deeply integrated into society, the capacity for systems to forget will be just as important as their capacity to learn. For organizations, building this capability is no longer an option but a prerequisite for earning and maintaining the public trust required to innovate responsibly in the age of AI.
FAQ
What is machine unlearning and why is it important for AI systems?
Machine unlearning (MU) is the process of selectively removing the influence of specific training data from a trained AI model without the need for complete retraining, which is prohibitively costly and time-consuming for large models. It provides a "subtractive" capability, allowing models to "forget" information. This is crucial because, unlike traditional databases where data can be simply deleted, information in an AI model is deeply embedded and entangled within its parameters, making simple data deletion ineffective. MU is becoming indispensable for regulatory compliance (like the "Right to be Forgotten" under GDPR), maintaining model integrity (e.g., removing bias or malicious data), and addressing business imperatives such as managing intellectual property risk and adhering to data licensing agreements. It signifies a paradigm shift where data is seen as a "revocable asset" rather than a one-time consumable.
What are the main drivers for the adoption of machine unlearning?
There are four primary catalysts driving the adoption of machine unlearning:
Regulatory Compliance: The "Right to be Forgotten," mandated by regulations like GDPR, requires organisations to delete personal data upon request, extending this to data's influence on AI models. MU offers the only practical, cost-effective way to comply without expensive full model retraining.
Model Integrity: MU helps maintain model quality and trustworthiness. It enables the removal of biased data to enhance fairness, excises malicious data from poisoning attacks to improve security, and deletes outdated information to keep models relevant and accurate.
Business Imperatives: Businesses use MU to manage intellectual property risk by removing inadvertently learned copyrighted material (e.g., from LLMs) and to ensure compliance with data licensing agreements when contracts expire or data access is revoked.
Operational Efficiency: Beyond compliance and integrity, MU offers significant cost savings and time efficiencies compared to retraining large models from scratch, which can take months and cost millions.
What are the two main categories of machine unlearning methodologies, and what are their trade-offs?
The two main categories are Exact Unlearning and Approximate Unlearning, distinguished by their trade-offs between completeness of data removal and efficiency:
Exact Unlearning: Aims to produce a model identical to one retrained from scratch without the forgotten data, offering provable, auditable guarantees of complete removal. This is often achieved through architectural designs like the Sharded, Isolated, Sliced, and Aggregated (SISA) framework. The trade-offs include higher initial complexity, potential degradation in model utility due to data isolation, and significant storage overhead. It's ideal for high-stakes, legally defensible scenarios.
Approximate Unlearning: Prioritises efficiency and scalability, aiming to efficiently minimise a data point's influence to a practically negligible level, rather than guaranteeing complete elimination. Techniques include influence-based removal, gradient reversal, and optimization-based fine-tuning. These methods are faster and more flexible, especially for large models, but offer weaker, heuristic guarantees, necessitating robust external verification. They are suited for large-scale models and rapid patching.
How is the SISA framework used for Exact Unlearning?
The SISA (Sharded, Isolated, Sliced, and Aggregated) framework is a prominent exact unlearning approach that designs forgetfulness into the model's architecture. It involves four key steps:
Sharding: The full training dataset is divided into smaller, disjoint subsets called shards.
Isolation: Separate, independent sub-models are trained on each shard. This ensures that the influence of any single data point is confined to only one sub-model.
Aggregation: During inference, predictions from all sub-models are combined (e.g., via majority voting or averaging) to produce the final output.
Unlearning Process: When a data point needs to be forgotten, only the specific sub-model trained on the shard containing that point needs to be discarded and retrained from scratch on its (smaller) shard, now excluding the forgotten data. This is significantly faster and cheaper than retraining the entire model.
Slicing can further enhance efficiency by saving checkpoints during sub-model training, allowing retraining to restart from a point just before the forgotten data was introduced.
How is machine unlearning integrated into the enterprise AI lifecycle and MLOps pipelines?
Integrating machine unlearning effectively requires deep operationalisation within Machine Learning Operations (MLOps) pipelines, moving privacy from a post-deployment concern to a core engineering principle. Key aspects include:
Privacy by Design: Embedding privacy and data protection into system design from the outset, often via formal Consent Management (CM) systems.
Automated Triggers: The CM system can act as an automated trigger for unlearning. When consent is revoked or data retention policies flag data, an event automatically initiates the unlearning workflow, adding the data to a "forget set" and triggering the relevant unlearning pipeline for affected models.
Structured Unlearning Pipeline: This pipeline typically involves steps such as:
Request Ingestion: Receiving unlearning requests (automated or manual).
Forget Set Identification: Translating requests into specific data points to forget and retain, relying on robust data governance and lineage tools.
Unlearning Execution: Invoking the appropriate unlearning algorithm.
Verification and Auditing: An automated stage to confirm forgetting quality and utility preservation.
Model Deployment: Versioning and promoting the unlearned model to production only after verification.
This automated, event-driven approach ensures reliable handling of requests and provides an auditable trail for regulatory compliance.
How is the success of machine unlearning verified and audited?
Verification is a critical and challenging aspect of machine unlearning, requiring a multi-faceted auditing strategy. Success is evaluated against three pillars:
Forgetting Quality: How completely the target data's influence has been removed.
Model Utility: The impact of unlearning on the model's performance on retained data.
Efficiency: The operational cost (time, compute, storage) of the unlearning process.
Key verification techniques include:
Membership Inference Attacks (MIAs): Adversarial attacks that try to determine if a specific data point was part of the training set. If an MIA can still identify "forgotten" data, unlearning has failed.
Perturbation Analysis: Making small changes to forgotten data and observing if the model's output significantly changes, indicating residual memory.
Relearn Time: Measuring how long it takes the unlearned model to regain original accuracy on the forgotten data; a shorter time suggests residual knowledge.
Standardised Benchmarks: Frameworks like MUSE (Machine Unlearning Six-Way Evaluation) provide comprehensive metrics for comparing algorithms across privacy, utility, and scalability.
Explainable AI (XAI): Using techniques like saliency maps to visually confirm that the model's "attention" has shifted away from forgotten concepts, offering qualitative and quantitative evidence of forgetting.
What are the main challenges and open problems in machine unlearning?
Despite significant progress, machine unlearning faces formidable challenges:
Catastrophic Unlearning: A major risk where removing a small amount of targeted information disproportionately degrades the model's overall performance on retained data, rendering the model useless.
Knowledge Entanglement: In complex neural networks, information is distributed and highly entangled across parameters, making surgical removal of specific knowledge difficult without unintended side effects on related, benign concepts.
Unlearning in Large Language Models (LLMs) and Generative AI: The sheer scale and cost of LLMs make retraining infeasible. Unlearning abstract "concepts," "capabilities," or "behaviours" (e.g., toxicity, copyrighted content) from generative models is difficult, as they can hallucinate or reconstruct information in novel ways.
Robustness and Security: Even if unlearned, there's a concern that models might retain enough fundamental knowledge to reconstruct forgotten capabilities. Additionally, the unlearning process itself can introduce new security vulnerabilities, potentially serving as an attack surface for adversaries.
These challenges highlight that the field is still in its early stages of development, with active research exploring solutions.
Why is investing in machine unlearning a strategic imperative for organisations deploying AI?
Investing in machine unlearning is transitioning from an option to a core competency for any organisation committed to deploying AI responsibly and effectively. It offers a clear Return on Investment (ROI) through:
Cost Savings: Directly quantifies savings by avoiding the immense costs (compute, energy, engineering time) of full model retraining for every data erasure request.
Risk Mitigation: Quantifies the value of mitigating significant financial and reputational risks, including:
Regulatory Fines: Avoiding substantial penalties (e.g., 4% of global turnover under GDPR).
Litigation and Settlements: Reducing exposure to costly legal battles over copyright infringement or data usage violations.
Reputational Damage: Safeguarding brand value and customer trust, which can be severely damaged by biased, unfair, or privacy-violating AI systems.
Beyond ROI, unlearning is a foundational pillar of responsible AI. It enables the creation of adaptable, fair, secure, and privacy-respecting models, which is crucial for earning and maintaining public trust as AI becomes more integrated into society. Organisations that prioritise unlearning demonstrate a commitment to ethical AI governance, making it a prerequisite for responsible innovation.